You might also like
- Comic Characters Detection Using Deep LearningDocument6 pagesComic Characters Detection Using Deep LearningBenedict NsiahNo ratings yet
- Specific Comic Character Detection Using Local Feature MatchingDocument5 pagesSpecific Comic Character Detection Using Local Feature MatchingBenedict NsiahNo ratings yet
- Multi-Style Paper Pop-Up Designs From 3D Models: Computer Graphics Forum May 2014Document11 pagesMulti-Style Paper Pop-Up Designs From 3D Models: Computer Graphics Forum May 2014Cristina MIHAINo ratings yet
- Layout Analysis of Tree-Structured Scene Frames in Comic ImagesDocument6 pagesLayout Analysis of Tree-Structured Scene Frames in Comic ImagesPixel CobrizoNo ratings yet
- Line-Wise Text Identification in Comic Books A Support Vector Machine-Based ApproachDocument6 pagesLine-Wise Text Identification in Comic Books A Support Vector Machine-Based ApproachBenedict NsiahNo ratings yet
- BookDocument34 pagesBookImtiaz HossainNo ratings yet
- Learning To Cartoonize Using White-Box Cartoon RepresentationsDocument10 pagesLearning To Cartoonize Using White-Box Cartoon RepresentationsAnujNo ratings yet
- COM 215 December-1-2018Document23 pagesCOM 215 December-1-2018PraiseNo ratings yet
- Mobius StripDocument6 pagesMobius StripdheerajkmishraNo ratings yet
- Folding Flat Silhouettes and Wrapping Polyhedral Packages: New Results in Computational OrigamiDocument10 pagesFolding Flat Silhouettes and Wrapping Polyhedral Packages: New Results in Computational OrigamijesusaselecNo ratings yet
- Xian Ying Eng - A Geometric Study of V-Style Pop-Ups Theories and AlgorithmsDocument10 pagesXian Ying Eng - A Geometric Study of V-Style Pop-Ups Theories and AlgorithmsFebi pebrianiNo ratings yet
- White Box Cartoon Acm StyleDocument9 pagesWhite Box Cartoon Acm Stylekashif amjadNo ratings yet
- An Automated Technique To Recognize and Extract Images From Scanned Archaeological DocumentsDocument6 pagesAn Automated Technique To Recognize and Extract Images From Scanned Archaeological Documentsfdghdfgmty thrhNo ratings yet
- Antologie - The Science of Fractal Images Text 2Document168 pagesAntologie - The Science of Fractal Images Text 2paul popNo ratings yet
- Frank Miller 4Document5 pagesFrank Miller 4api-313715162No ratings yet
- ComicsDocument2 pagesComicsstarshine520100% (1)
- Pop Up PDFDocument12 pagesPop Up PDFHey de LeónNo ratings yet
- Presentación Tesis FJMMDocument36 pagesPresentación Tesis FJMMFrancisco Jesús Martínez MurciaNo ratings yet
- Topic 2 - Page PlanningDocument44 pagesTopic 2 - Page Planningrafidah jaafarNo ratings yet
- Ej 10 2016 EjemploDocument18 pagesEj 10 2016 EjemploSheila GomezNo ratings yet
- Project Details STD 10 - 2023-24-1Document11 pagesProject Details STD 10 - 2023-24-1aarnavgeneral1308No ratings yet
- Calendar: 2014 Non-TraditionalDocument2 pagesCalendar: 2014 Non-TraditionalcandybeebeeNo ratings yet
- Rythmn & Pacing: Book AssignmentDocument4 pagesRythmn & Pacing: Book Assignmentclara8940No ratings yet
- Comic Book WritingDocument12 pagesComic Book Writingpetros100% (1)
- Origami Pop-Up Card Generation From 3D Models Using A Directed Acyclic GraphDocument18 pagesOrigami Pop-Up Card Generation From 3D Models Using A Directed Acyclic GraphLovely ChicNo ratings yet
- Short Story Comic Strip LPDocument6 pagesShort Story Comic Strip LPapi-322034177No ratings yet
- Colour Imaging and Processing ApplicationDocument368 pagesColour Imaging and Processing Applicationboon hiang seetNo ratings yet
- An Overview of Mechanisms and Patterns With Origami Author David DureisseixDocument19 pagesAn Overview of Mechanisms and Patterns With Origami Author David DureisseixMulugeta AbebeNo ratings yet
- Rendering Parametric Surfaces in Pen and Ink: Georges Winkenbach David H. SalesinDocument8 pagesRendering Parametric Surfaces in Pen and Ink: Georges Winkenbach David H. SalesinAnonymous GKqp4HnNo ratings yet
- The Art of Brainding Tessitura GroensteenDocument11 pagesThe Art of Brainding Tessitura GroensteenGeovanaNo ratings yet
- The Philosophy of Comics What They Are How They Work and Why They Matter Henry John Pratt Ebook Full ChapterDocument51 pagesThe Philosophy of Comics What They Are How They Work and Why They Matter Henry John Pratt Ebook Full Chapterkelly.hughes324100% (9)
- Every Image Tells A Story BriefDocument5 pagesEvery Image Tells A Story Briefapi-264226885No ratings yet
- How Do You Define "Comic Book"?: Visual Language: Writing For ComicsDocument31 pagesHow Do You Define "Comic Book"?: Visual Language: Writing For ComicsGeo DobaNo ratings yet
- Module of Art and Culture 2nd SMTDocument12 pagesModule of Art and Culture 2nd SMTPuspitawatiNo ratings yet
- Chapter 9Document7 pagesChapter 9athirahNo ratings yet
- DC105 Module1 Lesson1 - Graphics and VisualizationDocument15 pagesDC105 Module1 Lesson1 - Graphics and VisualizationsdfNo ratings yet
- Computer-Generated PapercuttingDocument8 pagesComputer-Generated PapercuttinggeorgeNo ratings yet
- An Overview of Mechanisms and Patterns With Origami: To Cite This VersionDocument16 pagesAn Overview of Mechanisms and Patterns With Origami: To Cite This VersionAdriana Zwierzanska - KolaczkowskaNo ratings yet
- Bridges2022 63Document9 pagesBridges2022 63loser31415No ratings yet
- 2nd Grade Art Lesson OrgDocument6 pages2nd Grade Art Lesson Orgapi-288691585No ratings yet
- A Puzzle Solver and Its Application in Speech Descrambling: January 2007Document7 pagesA Puzzle Solver and Its Application in Speech Descrambling: January 2007fate apocryphaNo ratings yet
- As Lesson 5 - FinalDocument3 pagesAs Lesson 5 - FinalJessa ArgabioNo ratings yet
- 09.23.mathematical Models For Local Deter Minis Tic in PaintingsDocument31 pages09.23.mathematical Models For Local Deter Minis Tic in PaintingsAlessioNo ratings yet
- 01.09.image in PaintingDocument8 pages01.09.image in PaintingAlessioNo ratings yet
- Zhang - ICIVC17 - Detecting Chinese Calligraphy Style Consistency by Deep Learning and One-Class SVMDocument4 pagesZhang - ICIVC17 - Detecting Chinese Calligraphy Style Consistency by Deep Learning and One-Class SVMpyt000122No ratings yet
- English I: Cambridge School (Icse), Kandivali (East) Class X - Board Projects (2023-24)Document7 pagesEnglish I: Cambridge School (Icse), Kandivali (East) Class X - Board Projects (2023-24)shruticse2024No ratings yet
- Engineering DrawingDocument310 pagesEngineering DrawingViral Van100% (1)
- Introduction To The Special Section On Graph Algorithms in Computer VisionDocument4 pagesIntroduction To The Special Section On Graph Algorithms in Computer VisionYuvi EmpireNo ratings yet
- Computer-Aided Design: Lifeng Zhu, Benyi Xie, Yongjie Jessica Zhang, Lap-Fai YuDocument9 pagesComputer-Aided Design: Lifeng Zhu, Benyi Xie, Yongjie Jessica Zhang, Lap-Fai Yudanny pelaezNo ratings yet
- Paper ModelDocument4 pagesPaper ModelMainak Jana100% (1)
- Modular - Origami - Polyhedra-Part 01Document8 pagesModular - Origami - Polyhedra-Part 01Monike Kusna0% (3)
- Antologie - The Science of Fractal ImagesDocument197 pagesAntologie - The Science of Fractal Imagespaul popNo ratings yet
- Digital Mosaic Frameworks - An Overview: ForumDocument19 pagesDigital Mosaic Frameworks - An Overview: ForumpostiraNo ratings yet
- Early Digital Computer Art at Bell Telephone Laboratories, IncorporatedDocument11 pagesEarly Digital Computer Art at Bell Telephone Laboratories, IncorporatedLily FakhreddineNo ratings yet
- Folding and One Straight Cut SufficeDocument3 pagesFolding and One Straight Cut SufficeSallie HollanderNo ratings yet
- Mapping The Underground British English StudentDocument5 pagesMapping The Underground British English StudentGiovany LeonNo ratings yet
- Paper PDFDocument8 pagesPaper PDFElisa VascottoNo ratings yet
- Intelligent Comic Role Plot Dialogue Recommendation System For Comic Script Creation Educational ApplicationDocument4 pagesIntelligent Comic Role Plot Dialogue Recommendation System For Comic Script Creation Educational ApplicationBenedict NsiahNo ratings yet
- Intelligent Comic Make System Based On Comic Script CreationDocument4 pagesIntelligent Comic Make System Based On Comic Script CreationBenedict NsiahNo ratings yet
- E-Comics in Teaching Evaluating and Using Comic Strip Creator Tools For Educational PurposesDocument5 pagesE-Comics in Teaching Evaluating and Using Comic Strip Creator Tools For Educational PurposesBenedict NsiahNo ratings yet
- Automatic Comic Strip Generation Using Extracted Keyframes From Cartoon AnimationDocument6 pagesAutomatic Comic Strip Generation Using Extracted Keyframes From Cartoon AnimationBenedict NsiahNo ratings yet
- Investigating The Transfer of Scientific Content With The Help of Comic Stories at A Level of Higher Education 2Document6 pagesInvestigating The Transfer of Scientific Content With The Help of Comic Stories at A Level of Higher Education 2Benedict NsiahNo ratings yet
- Sandstorm Absorbent SkyscraperDocument4 pagesSandstorm Absorbent SkyscraperPardisNo ratings yet
- Case CapsuleDocument8 pagesCase CapsuleLiza BulsaraNo ratings yet
- PFEIFER Angled Loops For Hollow Core Slabs: Item-No. 05.023Document1 pagePFEIFER Angled Loops For Hollow Core Slabs: Item-No. 05.023adyhugoNo ratings yet
- Evolution Army 3 R DadDocument341 pagesEvolution Army 3 R DadStanisław DisęNo ratings yet
- Clockwork Dragon's Expanded ArmoryDocument13 pagesClockwork Dragon's Expanded Armoryabel chabanNo ratings yet
- Rana2 Compliment As Social StrategyDocument12 pagesRana2 Compliment As Social StrategyRanaNo ratings yet
- Impact of Pantawid Pamilyang Pilipino Program On EducationDocument10 pagesImpact of Pantawid Pamilyang Pilipino Program On EducationEllyssa Erika MabayagNo ratings yet
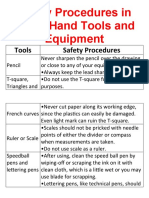
- Safety Procedures in Using Hand Tools and EquipmentDocument12 pagesSafety Procedures in Using Hand Tools and EquipmentJan IcejimenezNo ratings yet
- Desktop 9 QA Prep Guide PDFDocument15 pagesDesktop 9 QA Prep Guide PDFPikine LebelgeNo ratings yet
- Guyana and The Islamic WorldDocument21 pagesGuyana and The Islamic WorldshuaibahmadkhanNo ratings yet
- Cooperative Learning: Complied By: ANGELICA T. ORDINEZADocument16 pagesCooperative Learning: Complied By: ANGELICA T. ORDINEZAAlexis Kaye GullaNo ratings yet
- Determination Rules SAP SDDocument2 pagesDetermination Rules SAP SDkssumanthNo ratings yet
- Wner'S Anual: Led TVDocument32 pagesWner'S Anual: Led TVErmand WindNo ratings yet
- Sem4 Complete FileDocument42 pagesSem4 Complete Fileghufra baqiNo ratings yet
- LSCM Course OutlineDocument13 pagesLSCM Course OutlineDeep SachetiNo ratings yet
- Mechanical Production Engineer Samphhhhhle ResumeDocument2 pagesMechanical Production Engineer Samphhhhhle ResumeAnirban MazumdarNo ratings yet
- Fundaciones Con PilotesDocument48 pagesFundaciones Con PilotesReddy M.Ch.No ratings yet
- SOL LogicDocument21 pagesSOL LogicJa RiveraNo ratings yet
- BSC HTM - TourismDocument4 pagesBSC HTM - Tourismjaydaman08No ratings yet
- Tesco True Results Casing Running in China Results in Total Depth PDFDocument2 pagesTesco True Results Casing Running in China Results in Total Depth PDF123456ccNo ratings yet
- Acer N300 ManualDocument50 pagesAcer N300 Manualc_formatNo ratings yet
- Genetics Icar1Document18 pagesGenetics Icar1elanthamizhmaranNo ratings yet
- UntitledDocument216 pagesUntitledMONICA SIERRA VICENTENo ratings yet
- Julia Dito ResumeDocument3 pagesJulia Dito Resumeapi-253713289No ratings yet
- DBMS Lab ManualDocument57 pagesDBMS Lab ManualNarendh SubramanianNo ratings yet
- Produktkatalog SmitsvonkDocument20 pagesProduktkatalog Smitsvonkomar alnasserNo ratings yet
- Chapter 23Document9 pagesChapter 23Javier Chuchullo TitoNo ratings yet
- (1921) Manual of Work Garment Manufacture: How To Improve Quality and Reduce CostsDocument102 pages(1921) Manual of Work Garment Manufacture: How To Improve Quality and Reduce CostsHerbert Hillary Booker 2nd100% (1)
- (Jones) GoodwinDocument164 pages(Jones) Goodwinmount2011No ratings yet
- Pidsdps 2106Document174 pagesPidsdps 2106Steven Claude TanangunanNo ratings yet