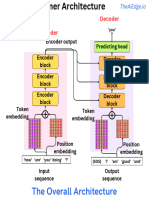
You might also like
- Feedforward Neural Networks: Fundamentals and Applications for The Architecture of Thinking Machines and Neural WebsFrom EverandFeedforward Neural Networks: Fundamentals and Applications for The Architecture of Thinking Machines and Neural WebsNo ratings yet
- Uni2 NNDLDocument21 pagesUni2 NNDLSONY P J 2248440No ratings yet
- Perceptrons: Fundamentals and Applications for The Neural Building BlockFrom EverandPerceptrons: Fundamentals and Applications for The Neural Building BlockNo ratings yet
- 3rd LectureDocument21 pages3rd LectureshilpaNo ratings yet
- Neural Networks NotesDocument22 pagesNeural Networks NoteszomukozaNo ratings yet
- Unit 2-AnnDocument62 pagesUnit 2-Ann4NM17CS077 KARTHIK KAMATHNo ratings yet
- 1 - Introduction of AIDocument92 pages1 - Introduction of AINaveena NagineniNo ratings yet
- Uni2 NN 2023Document52 pagesUni2 NN 2023SONY P J 2248440No ratings yet
- Neural NetworksDocument25 pagesNeural NetworksProgramming LifeNo ratings yet
- 2 DeepLearningDocument46 pages2 DeepLearningSWAMYA RANJAN DASNo ratings yet
- Unit 4Document9 pagesUnit 4akkiketchumNo ratings yet
- 1 - Perceptron in Machine LearningDocument6 pages1 - Perceptron in Machine LearningAnant JainNo ratings yet
- Research Proposal PresentationDocument20 pagesResearch Proposal Presentation20eg107140No ratings yet
- Week-3 Module-2 Neural NetworkDocument58 pagesWeek-3 Module-2 Neural NetworkSagar GuptaNo ratings yet
- Unit II - PerceptronDocument20 pagesUnit II - Perceptronyou • were • trolledNo ratings yet
- WINSEM2023-24 BITE410L TH VL2023240503970 2024-03-11 Reference-Material-IDocument40 pagesWINSEM2023-24 BITE410L TH VL2023240503970 2024-03-11 Reference-Material-IKhwab VachhaniNo ratings yet
- Module 3 Chap 4 ANNsDocument69 pagesModule 3 Chap 4 ANNshetomo5120No ratings yet
- Soft Computing Unit-2Document61 pagesSoft Computing Unit-2namak sung loNo ratings yet
- 2021 Lecture11 NeuralNetworksDocument48 pages2021 Lecture11 NeuralNetworksNguyen ThongNo ratings yet
- Artificial Neural NetworksDocument28 pagesArtificial Neural NetworksMaheswari ChimataNo ratings yet
- What Is A Neural Network?Document26 pagesWhat Is A Neural Network?Angel Pm100% (1)
- Machine Learning Module-3Document23 pagesMachine Learning Module-3Samba Shiva Reddy.g ShivaNo ratings yet
- Artificial Neural NetworksDocument24 pagesArtificial Neural Networkspunita singhNo ratings yet
- Machine Learning NNDocument16 pagesMachine Learning NNMegha100% (1)
- NN IntroductionDocument29 pagesNN IntroductionEman zakriaNo ratings yet
- Artificial Neural Networks: An: G.AnuradhaDocument76 pagesArtificial Neural Networks: An: G.AnuradhashardapatelNo ratings yet
- NNDLDocument96 pagesNNDLYogesh KrishnaNo ratings yet
- Artificial Neural NetworksDocument8 pagesArtificial Neural NetworksPavan SaiNo ratings yet
- Artificial Neural Networks RevDocument82 pagesArtificial Neural Networks RevDr. Swati JoshiNo ratings yet
- Deep Learning UNIT 1&2Document69 pagesDeep Learning UNIT 1&2HarshaNo ratings yet
- Perceptron For ClassDocument28 pagesPerceptron For Classiemct23No ratings yet
- Prepared By: Mayank Kothari (10BIT036) : Face Recognition Using Artificial Neural NetworkDocument36 pagesPrepared By: Mayank Kothari (10BIT036) : Face Recognition Using Artificial Neural Networkmayank036No ratings yet
- CS 611 Slides 5Document28 pagesCS 611 Slides 5Ahmad AbubakarNo ratings yet
- Historical Development of NN: Mcculloch and Pitts, 1943Document15 pagesHistorical Development of NN: Mcculloch and Pitts, 1943taliqaNo ratings yet
- ML Unit-IvDocument18 pagesML Unit-IvSBNo ratings yet
- 2024 MTH058 Lecture02 BackpropagationDocument62 pages2024 MTH058 Lecture02 BackpropagationMark MysteryNo ratings yet
- Biological Neuron Artificial NeuronDocument18 pagesBiological Neuron Artificial NeuronMohit SharmaNo ratings yet
- Introduction To Artificial Neural Networks and PerceptronDocument59 pagesIntroduction To Artificial Neural Networks and PerceptronPrathik NarayanNo ratings yet
- Artificial Neural Networks: A Tutorial: NeginyousefpourDocument27 pagesArtificial Neural Networks: A Tutorial: NeginyousefpourPrabal GoyalNo ratings yet
- Activation Function LearningDocument35 pagesActivation Function LearningVishal JainNo ratings yet
- Types of NetworksDocument31 pagesTypes of NetworksRahulNo ratings yet
- Experiment No. 4 TE SL-II (ANN)Document2 pagesExperiment No. 4 TE SL-II (ANN)RutujaNo ratings yet
- 4.0 The Complete Guide To Artificial Neural NetworksDocument23 pages4.0 The Complete Guide To Artificial Neural NetworksQian Jun AngNo ratings yet
- ML Exp-7Document5 pagesML Exp-7godizlatanNo ratings yet
- Module 5 AIML NotesDocument77 pagesModule 5 AIML Notesbabureddybn262003No ratings yet
- ANN Learning ProcessDocument25 pagesANN Learning ProcessAnurag RautNo ratings yet
- Isch 4Document44 pagesIsch 4190148sandipNo ratings yet
- Supervised Learning Unit 4-Neural NetworkDocument30 pagesSupervised Learning Unit 4-Neural NetworkPrerna SinghNo ratings yet
- Unit-1 Part-2Document89 pagesUnit-1 Part-2Mload 123No ratings yet
- 465-Lecture 2-4Document43 pages465-Lecture 2-4Faisal Bin Abdur Rahman 1912038642No ratings yet
- Unit - 2Document24 pagesUnit - 2vvvcxzzz3754No ratings yet
- Jntuk R20 ML Unit-VDocument19 pagesJntuk R20 ML Unit-VMaheshNo ratings yet
- Introduction To Neural NetworksDocument51 pagesIntroduction To Neural NetworksAayush PatidarNo ratings yet
- Unit 9 - Neural NetworkDocument53 pagesUnit 9 - Neural NetworkMihir MakwanaNo ratings yet
- DWDM Unit 2Document23 pagesDWDM Unit 2niharikaNo ratings yet
- Mi 2Document605 pagesMi 2Ankith VishnuNo ratings yet
- Unit - 4Document26 pagesUnit - 4UNISA SAKHANo ratings yet
- SOS Final SubmissionDocument36 pagesSOS Final SubmissionAyush JadiaNo ratings yet
- Artificial Neural NetworkDocument46 pagesArtificial Neural Networkmanish9890No ratings yet
- Unit-I Computational Intelligence - CSDocument34 pagesUnit-I Computational Intelligence - CSRaman NaamNo ratings yet
- DocScanner 18-DecDocument1 pageDocScanner 18-Deckingsourabh1074No ratings yet
- Assignment No 547Document6 pagesAssignment No 547kingsourabh1074No ratings yet
- Classroom of The Elite - Second Year Volume 11Document263 pagesClassroom of The Elite - Second Year Volume 11kingsourabh1074No ratings yet
- Unit 2 Supervised Learning RegressionDocument111 pagesUnit 2 Supervised Learning Regressionkingsourabh1074No ratings yet
- Unit 4: TreesDocument28 pagesUnit 4: Treeskingsourabh1074No ratings yet
- Handwritten Digit Recognition Using Convolutional Neural NetworksDocument6 pagesHandwritten Digit Recognition Using Convolutional Neural NetworkssososNo ratings yet
- CNN Building BlocksDocument14 pagesCNN Building BlocksANAND M (RA2113003011032)No ratings yet
- E0234 PPTDocument31 pagesE0234 PPTjerry.sharma0312No ratings yet
- Sentiment Classification With Deep Neural Networks: Yi ZhouDocument58 pagesSentiment Classification With Deep Neural Networks: Yi ZhouEdouard_CarvalhoNo ratings yet
- Introduction To Deep LearningDocument49 pagesIntroduction To Deep LearningLuv ChawdaNo ratings yet
- Lec18 Denoising+SparseAutoencodersDocument18 pagesLec18 Denoising+SparseAutoencodersrakeshNo ratings yet
- Traffic Flow Prediction Models A Review of Deep Learning TechniquesDocument25 pagesTraffic Flow Prediction Models A Review of Deep Learning Techniquesoseni wunmiNo ratings yet
- Artificial Intelligence and ExamplesDocument1 pageArtificial Intelligence and ExamplesjeoNo ratings yet
- 50 Deep Learning Technical Interview Questions With AnswersDocument20 pages50 Deep Learning Technical Interview Questions With AnswersIkram Laaroussi100% (1)
- MLSys Class LLM IntroductionDocument43 pagesMLSys Class LLM IntroductionAli ElouafiqNo ratings yet
- Fire DetectionDocument20 pagesFire DetectionB G Sumith KumarNo ratings yet
- Acknowledgement AnnDocument8 pagesAcknowledgement AnnXtremeInfosoftAlwarNo ratings yet
- Answers For End-Sem Exam Part - 2 (Deep Learning)Document20 pagesAnswers For End-Sem Exam Part - 2 (Deep Learning)Ankur BorkarNo ratings yet
- Empirical Evaluation of Rectified Activations in ConvolutionNetworkDocument5 pagesEmpirical Evaluation of Rectified Activations in ConvolutionNetworkMinh TriếtNo ratings yet
- LS 1Document10 pagesLS 1Ms. Divya KonikkaraNo ratings yet
- The Transformer ArchitectureDocument9 pagesThe Transformer Architecturealexandre albalustroNo ratings yet
- Pune University Soft Computing Exam PapersDocument4 pagesPune University Soft Computing Exam PaperspsmeeeNo ratings yet
- Deep Learning Techniques: An Overview: January 2021Document11 pagesDeep Learning Techniques: An Overview: January 2021Hanief RASYIDNo ratings yet
- L09-10 DL and CNNDocument56 pagesL09-10 DL and CNNPaulo SantosNo ratings yet
- Deep Belief NetworksDocument26 pagesDeep Belief NetworksFiromsa TesfayeNo ratings yet
- 2021-Deep Learning - A Comprehensive Overview on Techniques, Taxonomy, Applications and Research DirectionsDocument20 pages2021-Deep Learning - A Comprehensive Overview on Techniques, Taxonomy, Applications and Research Directionsheitoralves.diasNo ratings yet
- Artificial Neural NetworksDocument28 pagesArtificial Neural NetworksMaheswari ChimataNo ratings yet
- 2.3.1 The McCulloch-Pitts Model of NeuronDocument2 pages2.3.1 The McCulloch-Pitts Model of NeuronsegnumutraNo ratings yet
- Multi Layer Feed-Forward Network LearningDocument5 pagesMulti Layer Feed-Forward Network LearningBidkar Harshal SNo ratings yet
- Answer Any Two Full Questions, Each Carries 15 Marks: F F1124 Pages: 2Document2 pagesAnswer Any Two Full Questions, Each Carries 15 Marks: F F1124 Pages: 2Ben Babu PallikkunnelNo ratings yet
- Artificial Neural Networks (Anns) VS Deep Neural NetworksDocument24 pagesArtificial Neural Networks (Anns) VS Deep Neural NetworksSruthi SomanNo ratings yet
- Convolutional Neural Network Architecture - CNN ArchitectureDocument13 pagesConvolutional Neural Network Architecture - CNN ArchitectureRathi PriyaNo ratings yet
- The BACKPROPAGATION Algorithm: KD KDDocument10 pagesThe BACKPROPAGATION Algorithm: KD KDSwathi ReddyNo ratings yet
- Udacity Deep LEarning Part4 RNNDocument338 pagesUdacity Deep LEarning Part4 RNNyousef shabanNo ratings yet