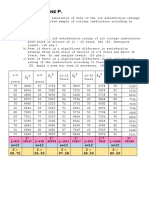
You might also like
- DATA MINING and MACHINE LEARNING. PREDICTIVE TECHNIQUES: ENSEMBLE METHODS, BOOSTING, BAGGING, RANDOM FOREST, DECISION TREES and REGRESSION TREES.: Examples with MATLABFrom EverandDATA MINING and MACHINE LEARNING. PREDICTIVE TECHNIQUES: ENSEMBLE METHODS, BOOSTING, BAGGING, RANDOM FOREST, DECISION TREES and REGRESSION TREES.: Examples with MATLABNo ratings yet
- Machine Learning with Python: A Comprehensive Guide with a Practical ExampleFrom EverandMachine Learning with Python: A Comprehensive Guide with a Practical ExampleNo ratings yet
- DWM1Document19 pagesDWM1Riya PatilNo ratings yet
- Priyadarshini J. L. College of Engineering, Nagpur: Session 2022-23 Semester-VDocument31 pagesPriyadarshini J. L. College of Engineering, Nagpur: Session 2022-23 Semester-VRiya PatilNo ratings yet
- DMBI Exp1: Introduction To WEKA ToolDocument6 pagesDMBI Exp1: Introduction To WEKA ToolAnkitNo ratings yet
- Data Base Management Key PointsDocument8 pagesData Base Management Key Pointsvishnu vardhanNo ratings yet
- Introduction To Weka-A Toolkit For Machine LearningDocument11 pagesIntroduction To Weka-A Toolkit For Machine LearningRisaNo ratings yet
- Laboratory Manual On: Data MiningDocument41 pagesLaboratory Manual On: Data MiningSurya KameswariNo ratings yet
- STRT AbhayDocument14 pagesSTRT AbhayDolly MehraNo ratings yet
- Data Warehouse Lab ManualDocument60 pagesData Warehouse Lab ManualspartansheikNo ratings yet
- Dmbi FileDocument31 pagesDmbi Fileharnek singhNo ratings yet
- Hemant STRTDocument18 pagesHemant STRTDolly MehraNo ratings yet
- DWM1 RiyaDocument16 pagesDWM1 RiyaRiya PatilNo ratings yet
- Appendix WekaDocument17 pagesAppendix WekaImranNo ratings yet
- Rintro WekacompleteDocument135 pagesRintro WekacompletepragyaNo ratings yet
- Exp 6Document5 pagesExp 6BugbearNo ratings yet
- Quran Question and Answer Corpus For Data Mining With WEKADocument6 pagesQuran Question and Answer Corpus For Data Mining With WEKAEric AtwellNo ratings yet
- DW PracticalsDocument40 pagesDW PracticalsMr Sathesh Abraham Leo CSENo ratings yet
- Deepak Dmbi FileDocument40 pagesDeepak Dmbi Filesatyam jhaNo ratings yet
- DWM Prac 1Document8 pagesDWM Prac 1AYUSH KUMARNo ratings yet
- WekaDocument27 pagesWekaShilpa VinayakaNo ratings yet
- CS-703 (B) Data Warehousing and Data Mining LabDocument50 pagesCS-703 (B) Data Warehousing and Data Mining Labgarima bhNo ratings yet
- Comparative Analysis of Data Mining Tools and Classification Techniques Using WEKA in Medical BioinformaticsDocument12 pagesComparative Analysis of Data Mining Tools and Classification Techniques Using WEKA in Medical BioinformaticsSergio AndresNo ratings yet
- Weka LabDocument11 pagesWeka LabAhmad AlsharefNo ratings yet
- WEKA Lab ManualDocument107 pagesWEKA Lab ManualRamesh Kumar100% (1)
- Machine Learning: Algorithms and Applications: Quang Nhat NguyenDocument16 pagesMachine Learning: Algorithms and Applications: Quang Nhat Nguyenapi-19780718No ratings yet
- Weka TutorialDocument58 pagesWeka Tutorialaslikoksal100% (1)
- Data Mining Lab FileDocument20 pagesData Mining Lab FileDanishKhanNo ratings yet
- Weka-: Data Warehousing and Data Mining Lab Manual-Week 9Document8 pagesWeka-: Data Warehousing and Data Mining Lab Manual-Week 9pakizaamin436100% (1)
- DWM - Exp No 5Document7 pagesDWM - Exp No 5cife sawantNo ratings yet
- Data Mining (WEKA) en FormattedDocument52 pagesData Mining (WEKA) en FormattedJefther EdwardNo ratings yet
- Department of Computer Engineering: Experiment No.3Document4 pagesDepartment of Computer Engineering: Experiment No.3BhumiNo ratings yet
- Empirical Software Engineering (SE-404) LAB A1-G1 Laboratory ManualDocument29 pagesEmpirical Software Engineering (SE-404) LAB A1-G1 Laboratory ManualAkash TyagiNo ratings yet
- 9348 11568 1 PB Published PaperDocument12 pages9348 11568 1 PB Published PapersatishdavidNo ratings yet
- 5 MIS510 Weka NetDrawDocument33 pages5 MIS510 Weka NetDrawgauravgd16No ratings yet
- Exp 6Document9 pagesExp 6ansari ammanNo ratings yet
- Iot Domain Analyst-Ece3502: Data Analytics Using Weka For Water Quality Related DataDocument14 pagesIot Domain Analyst-Ece3502: Data Analytics Using Weka For Water Quality Related Datasai manikantaNo ratings yet
- K-Means Clustering Using Weka InterfaceDocument6 pagesK-Means Clustering Using Weka InterfaceMarcelo LisboaNo ratings yet
- Published By: Blue Eyes Intelligence Engineering & Sciences Publication Retrieval Number: I10030789S19/19©BEIESP DOI: 10.35940/ijitee.I1003.0789S19Document1 pagePublished By: Blue Eyes Intelligence Engineering & Sciences Publication Retrieval Number: I10030789S19/19©BEIESP DOI: 10.35940/ijitee.I1003.0789S19MohmmedSaleemNo ratings yet
- Published By: Blue Eyes Intelligence Engineering & Sciences Publication Retrieval Number: I10030789S19/19©BEIESP DOI: 10.35940/ijitee.I1003.0789S19Document1 pagePublished By: Blue Eyes Intelligence Engineering & Sciences Publication Retrieval Number: I10030789S19/19©BEIESP DOI: 10.35940/ijitee.I1003.0789S19MohmmedSaleemNo ratings yet
- ML Assignment 1Document4 pagesML Assignment 1Abs WpsNo ratings yet
- Introduction To WEKA: Data Mining WEKA - What Is It? Weka Uis Integration With Pentaho Projects Based On WekaDocument27 pagesIntroduction To WEKA: Data Mining WEKA - What Is It? Weka Uis Integration With Pentaho Projects Based On WekarjaisankarNo ratings yet
- WekapptDocument58 pagesWekapptbahubali kingNo ratings yet
- Data Mining and Warehousing LabDocument4 pagesData Mining and Warehousing LabPhamThi ThietNo ratings yet
- TanagraDocument8 pagesTanagra2BL20IS038 Pooja SulakheNo ratings yet
- Experiment 1 Aim:: Introduction To ML Lab With Tools (Hands On WEKA On Data Set (Iris - Arff) ) - (A) Start WekaDocument55 pagesExperiment 1 Aim:: Introduction To ML Lab With Tools (Hands On WEKA On Data Set (Iris - Arff) ) - (A) Start WekaJayesh bansalNo ratings yet
- Weka Software ManualaDocument20 pagesWeka Software ManualaAswin Kumar ThanikachalamNo ratings yet
- Predictive Data Analytics With PythonDocument97 pagesPredictive Data Analytics With Pythontoon town100% (1)
- Iot Domain Analyst-Ece3502: Data Analytics Using Weka For Weather Land Related DataDocument21 pagesIot Domain Analyst-Ece3502: Data Analytics Using Weka For Weather Land Related Datasai manikantaNo ratings yet
- Weka TutorialDocument32 pagesWeka TutorialAlgus DarkNo ratings yet
- Lab Manual - DMDocument56 pagesLab Manual - DMUnknown The little worldNo ratings yet
- Orange Machine LearningDocument8 pagesOrange Machine LearningTarekHemdanNo ratings yet
- Oracle Data MiningDocument17 pagesOracle Data Mininggowripriya12No ratings yet
- Performance Enhancement Using Combinatorial Approach of Classification and Clustering in Machine LearningDocument8 pagesPerformance Enhancement Using Combinatorial Approach of Classification and Clustering in Machine LearningInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Weka TutorialDocument8 pagesWeka TutorialVairavasundaram VairamNo ratings yet
- Data Warehousing FullDocument41 pagesData Warehousing FullSECOND YEAR ITNo ratings yet
- DW Lab RecordDocument44 pagesDW Lab Recordrajeshwari1353No ratings yet
- DM Lab CseDocument108 pagesDM Lab Cselavanya penumudiNo ratings yet
- Data Mining and Business Intelligence FileDocument53 pagesData Mining and Business Intelligence FileARCHEENo ratings yet
- DATA MINING AND MACHINE LEARNING. PREDICTIVE TECHNIQUES: REGRESSION, GENERALIZED LINEAR MODELS, SUPPORT VECTOR MACHINE AND NEURAL NETWORKSFrom EverandDATA MINING AND MACHINE LEARNING. PREDICTIVE TECHNIQUES: REGRESSION, GENERALIZED LINEAR MODELS, SUPPORT VECTOR MACHINE AND NEURAL NETWORKSNo ratings yet
- Prof Anuj SharmaDocument1 pageProf Anuj Sharmagauravpatel5436No ratings yet
- O23 Btech Vii 1653Document779 pagesO23 Btech Vii 1653gauravpatel5436No ratings yet
- Renewable PPT Presentation (Every Monday) (Responses)Document1 pageRenewable PPT Presentation (Every Monday) (Responses)gauravpatel5436No ratings yet
- Unit-3 Value Engineering - 1Document6 pagesUnit-3 Value Engineering - 1gauravpatel5436No ratings yet
- Task 6Document8 pagesTask 6gauravpatel5436No ratings yet
- Renewable PPT Presentation (Every Monday) (Responses)Document1 pageRenewable PPT Presentation (Every Monday) (Responses)gauravpatel5436No ratings yet
- Diversity and Inclusion Action Plan 2017-2019Document26 pagesDiversity and Inclusion Action Plan 2017-2019Aygul ZagidullinaNo ratings yet
- Psychology ReportDocument130 pagesPsychology ReportAkhil SethiNo ratings yet
- Ten Principles For A Landscape Approach TERRY SUNDERLAND Y OTROS 2013 CIFORDocument11 pagesTen Principles For A Landscape Approach TERRY SUNDERLAND Y OTROS 2013 CIFORRosario De La CruzNo ratings yet
- Jurnal Kualitas PelayananDocument7 pagesJurnal Kualitas PelayananDwie Rizky RachmadaniNo ratings yet
- Biostatistics and Epidemiology: BioepiDocument25 pagesBiostatistics and Epidemiology: BioepiMaria Lana Grace DiazNo ratings yet
- Critical Value - ANOVADocument2 pagesCritical Value - ANOVAWei TingNo ratings yet
- Automatic Sign Language RecognicationDocument9 pagesAutomatic Sign Language RecognicationManthan DoshiNo ratings yet
- Seminar Worksheet. Measures of Dispersion 2Document5 pagesSeminar Worksheet. Measures of Dispersion 2Aruzhan ZhadyrassynNo ratings yet
- Midterm Exam 1Document4 pagesMidterm Exam 1Elonic AirosNo ratings yet
- Chapter 3Document36 pagesChapter 3asdasdasd122No ratings yet
- Samsung Mobiles: Market ResearchDocument33 pagesSamsung Mobiles: Market ResearchHarsh MohanNo ratings yet
- Dalfa Khotimatul Ulya - 1402180141 - AK-42-07 - Tugas Regresi Data PanelDocument8 pagesDalfa Khotimatul Ulya - 1402180141 - AK-42-07 - Tugas Regresi Data PanelALISA THE chennelNo ratings yet
- Statistics FormulaDocument6 pagesStatistics FormulaमधुNo ratings yet
- Dreem 010 WebversionDocument29 pagesDreem 010 Webversionapi-234824327No ratings yet
- Aniket Gurav: Total Experience: + 3.5 Years Data ScientistDocument4 pagesAniket Gurav: Total Experience: + 3.5 Years Data ScientistAniket GuravNo ratings yet
- BRM Project Report FinalDocument57 pagesBRM Project Report Finaladitya purohit50% (2)
- Data Science With RDocument8 pagesData Science With RSarah bookNo ratings yet
- DBS 521Document140 pagesDBS 521Innocent RamabokaNo ratings yet
- Chap 013Document141 pagesChap 013theluckless77750% (2)
- 2020 GerlachDocument78 pages2020 GerlachKoushik DasNo ratings yet
- Bending Spoons Cover LetterDocument1 pageBending Spoons Cover LetterNick KiaoNo ratings yet
- Due Monday, October 23Document3 pagesDue Monday, October 23karthu48No ratings yet
- Role of Community Organization in Rural DevelopmentDocument9 pagesRole of Community Organization in Rural DevelopmentSagar SunuwarNo ratings yet
- Packt R Machine Learning Projects 1789807948Document262 pagesPackt R Machine Learning Projects 1789807948telaNo ratings yet
- Does Error Feedback Help Student Writers New Evidence On The ShoDocument24 pagesDoes Error Feedback Help Student Writers New Evidence On The ShoĐỗ Quỳnh Trang100% (1)
- ACES Seller Support - Yellow Belt Training-Final - v3.3Document65 pagesACES Seller Support - Yellow Belt Training-Final - v3.3AHS Installations100% (2)
- Review On Density-Based Clustering - DBSCAN, DenClue & GRIDDocument20 pagesReview On Density-Based Clustering - DBSCAN, DenClue & GRIDjagatseshNo ratings yet
- Building A Career in Data Science - The OverviewDocument2 pagesBuilding A Career in Data Science - The OverviewTushar GondaliaNo ratings yet
- Gender DiscriminationDocument20 pagesGender DiscriminationuwendymaeNo ratings yet
- (COM508) Unit 5 - Business StatisticDocument2 pages(COM508) Unit 5 - Business StatisticlemonNo ratings yet