You might also like
- Introduction To Data Science, Evolution of Data ScienceDocument11 pagesIntroduction To Data Science, Evolution of Data Science2200030218csehNo ratings yet
- Fundamentals of Data Engineering: Designing and Building Scalable Data Systems for Modern ApplicationsFrom EverandFundamentals of Data Engineering: Designing and Building Scalable Data Systems for Modern ApplicationsNo ratings yet
- The Art of Data Science: Transformative Techniques for Analyzing Big DataFrom EverandThe Art of Data Science: Transformative Techniques for Analyzing Big DataNo ratings yet
- Data Science Is A Multidisciplinary Field That Uses Scientific MethodsDocument2 pagesData Science Is A Multidisciplinary Field That Uses Scientific MethodsIgor Schmidt FurlanNo ratings yet
- Data Scientist SkillsDocument11 pagesData Scientist SkillsRuksarat KhanankhoawNo ratings yet
- PYTHON DATA ANALYTICS: Harnessing the Power of Python for Data Exploration, Analysis, and Visualization (2024)From EverandPYTHON DATA ANALYTICS: Harnessing the Power of Python for Data Exploration, Analysis, and Visualization (2024)No ratings yet
- Fods QBDocument35 pagesFods QBSRIVARSHIKA SudhakarNo ratings yet
- Data Science Training in NoidaDocument9 pagesData Science Training in NoidaDigital ArnavNo ratings yet
- Module 1 ITE Elective 1 New - CurriculumDocument10 pagesModule 1 ITE Elective 1 New - CurriculumGarry PenoliarNo ratings yet
- Applications of Data Science in Various Fields, Data Security IssuesDocument3 pagesApplications of Data Science in Various Fields, Data Security Issues2200030218csehNo ratings yet
- Chap 1Document42 pagesChap 1suppercellcoc123No ratings yet
- Seminar On Data ScienceDocument25 pagesSeminar On Data Sciencekebe Aman100% (5)
- CUITM217-DATA-SCIENCE DataDocument48 pagesCUITM217-DATA-SCIENCE DataTanakaNo ratings yet
- DSE 3 Unit 1Document10 pagesDSE 3 Unit 1Priyaranjan Soren100% (1)
- Intro Lectures To DSADocument17 pagesIntro Lectures To DSArosieteelamae3No ratings yet
- FDS - Unit 1 Question BankDocument16 pagesFDS - Unit 1 Question Bankakshaya vijayNo ratings yet
- BDA (2019) Two Marks (QB)Document16 pagesBDA (2019) Two Marks (QB)sivaprakashNo ratings yet
- Data ScienceDocument65 pagesData ScienceSamanvitha VijapurapuNo ratings yet
- Data Science S (2 Files Merged)Document30 pagesData Science S (2 Files Merged)Sugisivam KENo ratings yet
- Chapter 1Document47 pagesChapter 1BALKHAZAARNo ratings yet
- Research Assignment 02burhan Ul DinDocument8 pagesResearch Assignment 02burhan Ul DinBurhan ul DinNo ratings yet
- Data VisualizationDocument7 pagesData VisualizationMalik SahabNo ratings yet
- Data Science: What the Best Data Scientists Know About Data Analytics, Data Mining, Statistics, Machine Learning, and Big Data – That You Don'tFrom EverandData Science: What the Best Data Scientists Know About Data Analytics, Data Mining, Statistics, Machine Learning, and Big Data – That You Don'tRating: 5 out of 5 stars5/5 (1)
- Intro-to-Data-and Data-Science-Course-Notes-365-Data-ScienceDocument17 pagesIntro-to-Data-and Data-Science-Course-Notes-365-Data-ScienceHelen MylonaNo ratings yet
- DSF 1-2Document28 pagesDSF 1-2Sultan mehmood hamzaNo ratings yet
- Data Science Course in HyderabadDocument9 pagesData Science Course in Hyderabadrajasrichalamala3zenNo ratings yet
- Python Machine Learning for Beginners: Unsupervised Learning, Clustering, and Dimensionality Reduction. Part 1From EverandPython Machine Learning for Beginners: Unsupervised Learning, Clustering, and Dimensionality Reduction. Part 1No ratings yet
- Data Science ComponentsDocument7 pagesData Science ComponentsKaushalNo ratings yet
- CSA3004 - DATA-VISUALIZATION - LT - 1.0 - 1 - CSA3004 - Data VisualizationDocument3 pagesCSA3004 - DATA-VISUALIZATION - LT - 1.0 - 1 - CSA3004 - Data VisualizationSachin SharmaNo ratings yet
- Fundamentals Data ScienceDocument2 pagesFundamentals Data ScienceDak DaekNo ratings yet
- CH 4 Data VisualizationDocument43 pagesCH 4 Data Visualizationll Y4ZEED llNo ratings yet
- Data Science SpecializationDocument21 pagesData Science SpecializationSEENU MANGALNo ratings yet
- Data Science for Beginners: Unlocking the Power of Data with Easy-to-Understand Concepts and Techniques. Part 3From EverandData Science for Beginners: Unlocking the Power of Data with Easy-to-Understand Concepts and Techniques. Part 3No ratings yet
- Lecture 01.1Document21 pagesLecture 01.1Quazi Hasnat IrfanNo ratings yet
- DS Mod 1 To 2 Complete NotesDocument63 pagesDS Mod 1 To 2 Complete NotesAnish ChoudharyNo ratings yet
- Da CH1 SlqaDocument6 pagesDa CH1 SlqaSushant ThiteNo ratings yet
- AD3491 - FDSA - Unit I - Introduction - Part IDocument23 pagesAD3491 - FDSA - Unit I - Introduction - Part IR.Mohan Kumar100% (1)
- Data Science: Certificate Programme inDocument11 pagesData Science: Certificate Programme inMartin LouisNo ratings yet
- Data Visulization ReportDocument21 pagesData Visulization ReportRushikesh GaikheNo ratings yet
- Unit1 R Full MaterialDocument11 pagesUnit1 R Full MaterialRamesh VarmaNo ratings yet
- Data Analytics Course in NoidaDocument9 pagesData Analytics Course in NoidaDigital ArnavNo ratings yet
- Machine Learning Algorithms for Data Scientists: An OverviewFrom EverandMachine Learning Algorithms for Data Scientists: An OverviewNo ratings yet
- Iimk Cpds BrochureDocument11 pagesIimk Cpds BrochurenNo ratings yet
- Ab Assignment 3Document7 pagesAb Assignment 3Noman NawabNo ratings yet
- Ourse Synopsis 2 Master Data Sciene 2020Document5 pagesOurse Synopsis 2 Master Data Sciene 2020Abdisalan Abdullahi MohamedNo ratings yet
- Application of Multiple Data Warehousing and Visualization Techniques in Student Information SystemDocument19 pagesApplication of Multiple Data Warehousing and Visualization Techniques in Student Information SystemBulls GhimireNo ratings yet
- Data Science Master Class 2023Document8 pagesData Science Master Class 2023giriprasad gunalanNo ratings yet
- Chapter 14 Big Data and Data Science - DONE DONE DONEDocument28 pagesChapter 14 Big Data and Data Science - DONE DONE DONERoche ChenNo ratings yet
- Data ScienceDocument2 pagesData Sciencetalhamughal20188No ratings yet
- Ch1 Data ScienceDocument14 pagesCh1 Data Sciencecherry07 cherryNo ratings yet
- Data Science Report - CompressDocument31 pagesData Science Report - CompressUvais AhmadNo ratings yet
- Ultimate Enterprise Data Analysis and Forecasting using Python: Leverage Cloud platforms with Azure Time Series Insights and AWS Forecast Components for Deep learning Modeling using Python (English Edition)From EverandUltimate Enterprise Data Analysis and Forecasting using Python: Leverage Cloud platforms with Azure Time Series Insights and AWS Forecast Components for Deep learning Modeling using Python (English Edition)No ratings yet
- Data Visualization Techniques Traditional Data To Big DataDocument23 pagesData Visualization Techniques Traditional Data To Big DataaghnetNo ratings yet
- DEV Lecture Notes Unit IDocument72 pagesDEV Lecture Notes Unit Iprins lNo ratings yet
- Introduction of Data ScienceDocument3 pagesIntroduction of Data ScienceNaresh BabuNo ratings yet
- Performance and Feedback AnalyzerDocument6 pagesPerformance and Feedback AnalyzerIJRASETPublicationsNo ratings yet
- Ls 5 Big Data VisualizationDocument7 pagesLs 5 Big Data VisualizationNikita MandhanNo ratings yet
- Computational Thinking Meets Student Learning: Extending the ISTE StandardsFrom EverandComputational Thinking Meets Student Learning: Extending the ISTE StandardsNo ratings yet
- IIQ Plugin - Step by Step GuideDocument9 pagesIIQ Plugin - Step by Step GuidetgudyktzxNo ratings yet
- Transactions and Concurrency ControlDocument7 pagesTransactions and Concurrency Controlbhavesh agrawal100% (1)
- Indexing and Retrieval of Scientific LiteratureDocument8 pagesIndexing and Retrieval of Scientific LiteratureAna Candelaria Dávila PérezNo ratings yet
- Ebook Data Analytics Vce Units 3 4 PDF Full Chapter PDFDocument67 pagesEbook Data Analytics Vce Units 3 4 PDF Full Chapter PDFmichael.carey504100% (29)
- Toward An Arabic Question Answering System Over Linked DataDocument15 pagesToward An Arabic Question Answering System Over Linked Datacasper4519793316No ratings yet
- Bases Datos (basesdedatos@inditexฺcom) has a non-transferable license to use this Student GuideฺDocument264 pagesBases Datos (basesdedatos@inditexฺcom) has a non-transferable license to use this Student GuideฺCacobitoNo ratings yet
- SQLZOODocument2 pagesSQLZOOThanhNo ratings yet
- SF PLT Managing User Info enDocument138 pagesSF PLT Managing User Info enTatenda Christerbel ChabikwaNo ratings yet
- Idsa ReviewerDocument4 pagesIdsa ReviewerorionsiguenzaNo ratings yet
- Informix 4gl by ExampleDocument740 pagesInformix 4gl by Examplemuraleedharanc100% (2)
- Pdms Setup Mds - Pdms MacroDocument3 pagesPdms Setup Mds - Pdms MacroSameerChauhanNo ratings yet
- Data Science Machine Learning Brochure SkillovillaDocument40 pagesData Science Machine Learning Brochure SkillovillaVyanktesh VaishnavNo ratings yet
- 6 Data Sheet - Credential ManagerDocument4 pages6 Data Sheet - Credential ManagerJohn AndradeNo ratings yet
- PI Data Archive 2018 SP3 Patch 1 System Management Guide ENDocument202 pagesPI Data Archive 2018 SP3 Patch 1 System Management Guide ENBachtiar YusufNo ratings yet
- Nishant Dua: Technical Skills ExperiencedDocument5 pagesNishant Dua: Technical Skills ExperiencedNishantNo ratings yet
- Tems Discovery 3.1 - User Manual PDFDocument371 pagesTems Discovery 3.1 - User Manual PDFChu Quang TuanNo ratings yet
- Hardware and Software RequirementsDocument2 pagesHardware and Software RequirementsRajeev Ranjan Tiwari0% (2)
- A1Session7 MBIS4002Document5 pagesA1Session7 MBIS4002saviourmartpkNo ratings yet
- Wt&ds Sem-1 Sppu SlipsDocument30 pagesWt&ds Sem-1 Sppu SlipsAnuja SuryawanshiNo ratings yet
- Library ManagementDocument8 pagesLibrary ManagementAjay SontekeNo ratings yet
- Apps DBA 12.2 TrainingDocument6 pagesApps DBA 12.2 TrainingRaihanNo ratings yet
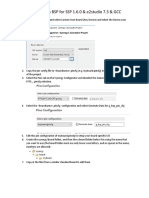
- Custom BSP For SSP 1.6.0 E2studio GCCDocument8 pagesCustom BSP For SSP 1.6.0 E2studio GCCcontateste123No ratings yet
- Advocate Assigning System: Bachelor of Science in Computer ScienceDocument101 pagesAdvocate Assigning System: Bachelor of Science in Computer Sciencepriyanka extazeeNo ratings yet
- 11 ChemistryDocument10 pages11 ChemistryDeepanshu digariNo ratings yet
- Cobie PDFDocument40 pagesCobie PDFShiyamraj ThamodharanNo ratings yet
- Unit 2 SamplingDocument33 pagesUnit 2 SamplingramanatenaliNo ratings yet
- RAC12c Theory Guide v8.0Document132 pagesRAC12c Theory Guide v8.0Irfan AhmadNo ratings yet
- Graph Databases For Dummies PDFDocument51 pagesGraph Databases For Dummies PDFIvan Arenas Meza100% (1)
- Alv ReportsDocument21 pagesAlv Reportsmnsk26No ratings yet
- CS213 - Fundamentals of Databases: Assignment 4Document2 pagesCS213 - Fundamentals of Databases: Assignment 4munib zafarNo ratings yet