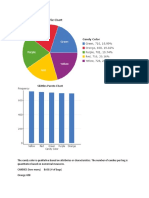
You might also like
- 111 08.x Supplement Central Limit Theorem Key PDFDocument3 pages111 08.x Supplement Central Limit Theorem Key PDFPei JingNo ratings yet
- Modern Physics Test 2 - Elevate Classes - 10352883 - 2022 - 12!25!19 - 53Document6 pagesModern Physics Test 2 - Elevate Classes - 10352883 - 2022 - 12!25!19 - 53dixitratan68No ratings yet
- Common P.G. Entrance Test 2020 Subject: PhysicsDocument19 pagesCommon P.G. Entrance Test 2020 Subject: Physicsamar nayakNo ratings yet
- Multivariate Methods Assignment HelpDocument17 pagesMultivariate Methods Assignment HelpStatistics Assignment ExpertsNo ratings yet
- IIT-JEE 2004 Mains Questions & Solutions - Maths - Version 2 (The Questions Are Based On Memory)Document15 pagesIIT-JEE 2004 Mains Questions & Solutions - Maths - Version 2 (The Questions Are Based On Memory)AlokShuklaNo ratings yet
- 81-E - RF - RR - m1Document31 pages81-E - RF - RR - m1Karthik SadanandaNo ratings yet
- 3 PDFDocument56 pages3 PDFTala AbdelghaniNo ratings yet
- U5A1 - Average Rate of Change1Document6 pagesU5A1 - Average Rate of Change1Halimat BakareNo ratings yet
- PhIMO 2021 Finals Review JS Set 3Document24 pagesPhIMO 2021 Finals Review JS Set 3Gil Deon BasaNo ratings yet
- PENANG 2013 STPM TRIAL PAPERS For Mathematics T TERM 2Document8 pagesPENANG 2013 STPM TRIAL PAPERS For Mathematics T TERM 2SK100% (3)
- 11 Final SolutionsDocument19 pages11 Final Solutionsterrygoh6972No ratings yet
- Chapter 5: Sampling Distributions: Solve The ProblemDocument4 pagesChapter 5: Sampling Distributions: Solve The ProblemEunice WongNo ratings yet
- Var Stand Deviat UngroupDocument2 pagesVar Stand Deviat Ungrouppablgonz8184No ratings yet
- Probability and Statistics With R For Engineers and Scientists 1st Edition Michael Akritas Solutions ManualDocument20 pagesProbability and Statistics With R For Engineers and Scientists 1st Edition Michael Akritas Solutions ManualMichaelGarciamwpge100% (18)
- 10 Jan Slot 2 SolutionsDocument40 pages10 Jan Slot 2 SolutionsBabita MishraNo ratings yet
- Covariance, Correlation CoefficientDocument4 pagesCovariance, Correlation CoefficientIvan ZhuravlevNo ratings yet
- Test1 FR1203Document4 pagesTest1 FR1203moskovkinpetrNo ratings yet
- 332 4 SimpleDocument12 pages332 4 SimpleS HWNo ratings yet
- 12AP Herlzia Prelims '07Document10 pages12AP Herlzia Prelims '07sound05No ratings yet
- Sample PaperDocument7 pagesSample PaperAishanaNo ratings yet
- Mathematics CBSE Model Question Papers 2023 With Marking SCHDocument19 pagesMathematics CBSE Model Question Papers 2023 With Marking SCHThe KingstonNo ratings yet
- Mathematics SPM 2011.powerpointDocument55 pagesMathematics SPM 2011.powerpointuzai88No ratings yet
- Information Festival II: (9.1-11.5) Version D Math 1C WINTER 2015Document10 pagesInformation Festival II: (9.1-11.5) Version D Math 1C WINTER 2015Anonymous rVvkVpZlNo ratings yet
- 36-708 Statistical Machine Learning Homework #3 Solutions: DUE: March 29, 2019Document22 pages36-708 Statistical Machine Learning Homework #3 Solutions: DUE: March 29, 2019SNo ratings yet
- Module 1 Integral ExponentsDocument23 pagesModule 1 Integral ExponentsSucceed Review100% (1)
- Exam 3 - Solution SketchDocument2 pagesExam 3 - Solution SketchAceeNo ratings yet
- Cbse Class 12 Sample Paper 2022 23 MathematicsDocument7 pagesCbse Class 12 Sample Paper 2022 23 Mathematicsttojo7105No ratings yet
- Soln1 PsDocument6 pagesSoln1 PsRafran Rosly100% (1)
- Calculus 2 Final ExamDocument8 pagesCalculus 2 Final Examtevin sessaNo ratings yet
- 14 Variance and Covariance of Random VariablesDocument7 pages14 Variance and Covariance of Random VariablesHarold FinchNo ratings yet
- DPS Gxi Mock Question Paper 041Document7 pagesDPS Gxi Mock Question Paper 041Simoni KhattarNo ratings yet
- CLASS XII Maths-SQPDocument12 pagesCLASS XII Maths-SQPSanjayNo ratings yet
- Maths SQP 2023 24 MergedDocument40 pagesMaths SQP 2023 24 MergedAANCHAL MITTALNo ratings yet
- SSVM Institutions Periodic Test 2 Mathematics: (Each Question Carries 1 Mark)Document3 pagesSSVM Institutions Periodic Test 2 Mathematics: (Each Question Carries 1 Mark)MidhunBhuvaneshB RWSNo ratings yet
- Assignment - MATHS IVDocument11 pagesAssignment - MATHS IVMande VictorNo ratings yet
- 12 TH MathsDocument9 pages12 TH MathsAkshatNo ratings yet
- Past Year Questions: Compiled By: Lee Kian Keong September 14, 2010Document40 pagesPast Year Questions: Compiled By: Lee Kian Keong September 14, 2010Loy Jing ShienNo ratings yet
- Math 124 Final Examination Winter 2011: !!! READ... INSTRUCTIONS... READ !!!Document12 pagesMath 124 Final Examination Winter 2011: !!! READ... INSTRUCTIONS... READ !!!jelenicasabancicaNo ratings yet
- Number TheoryDocument49 pagesNumber TheoryNazm Us Sakib100% (1)
- Hybrid Math 11 Stat Q1 M3 W3 V2Document14 pagesHybrid Math 11 Stat Q1 M3 W3 V2L AlcosabaNo ratings yet
- MATH1050A1Document2 pagesMATH1050A1songpengyuan123No ratings yet
- CrapDocument8 pagesCrapvincentliu11No ratings yet
- Curve Tracing: Monotonic Function, Concavity and Point of InflectionDocument9 pagesCurve Tracing: Monotonic Function, Concavity and Point of InflectionpreetiNo ratings yet
- SPHA031-23 Online Assignment No 1 Solutions 2023Document4 pagesSPHA031-23 Online Assignment No 1 Solutions 2023Ntokozo MasemulaNo ratings yet
- Institute of Actuaries of IndiaDocument15 pagesInstitute of Actuaries of IndiaeuticusNo ratings yet
- 3 Discrete Random Variables and Probability DistributionsDocument26 pages3 Discrete Random Variables and Probability DistributionsRenukadevi RptNo ratings yet
- Sample Final Questions: (A) Converge or Diverge As N ? If ADocument3 pagesSample Final Questions: (A) Converge or Diverge As N ? If ANguyễn Văn QuyếtNo ratings yet
- Online Test Part 2Document3 pagesOnline Test Part 2Srijan2022 H42No ratings yet
- SEM 3 BC0043 1 Computer Oriented Numerical MethodsDocument20 pagesSEM 3 BC0043 1 Computer Oriented Numerical MethodsRajat NandyNo ratings yet
- NOC23 EE49 Assignment Week02 v0.1Document5 pagesNOC23 EE49 Assignment Week02 v0.1Get Into StudyNo ratings yet
- Phys102 Term: 103 Second Major-August 06, 2011Document8 pagesPhys102 Term: 103 Second Major-August 06, 2011Prosonjit Chandra DashNo ratings yet
- Mathematics Xii PaperDocument7 pagesMathematics Xii Paperasi795856No ratings yet
- UntitledDocument10 pagesUntitledapi-98380389No ratings yet
- Industrial Safety Engineering Assignment 0Document3 pagesIndustrial Safety Engineering Assignment 0aleemNo ratings yet
- Physics Quest HW 2bDocument3 pagesPhysics Quest HW 2bFuriFuriNo ratings yet
- Trigonometric Ratios to Transformations (Trigonometry) Mathematics E-Book For Public ExamsFrom EverandTrigonometric Ratios to Transformations (Trigonometry) Mathematics E-Book For Public ExamsRating: 5 out of 5 stars5/5 (1)
- Application of Derivatives Tangents and Normals (Calculus) Mathematics E-Book For Public ExamsFrom EverandApplication of Derivatives Tangents and Normals (Calculus) Mathematics E-Book For Public ExamsRating: 5 out of 5 stars5/5 (1)
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- De Moiver's Theorem (Trigonometry) Mathematics Question BankFrom EverandDe Moiver's Theorem (Trigonometry) Mathematics Question BankNo ratings yet
- JOHNSON 2014 Progress in Regression - Why Natural Language Data Calls For Mixed-Effects ModelsDocument17 pagesJOHNSON 2014 Progress in Regression - Why Natural Language Data Calls For Mixed-Effects ModelsMartha ChávezNo ratings yet
- Risks: Lead-Lag Relationship Using A Stop-And-Reverse-Minmax ProcessDocument20 pagesRisks: Lead-Lag Relationship Using A Stop-And-Reverse-Minmax ProcessRahul RawatNo ratings yet
- Environmental Awareness Research PDFDocument5 pagesEnvironmental Awareness Research PDFKyahNo ratings yet
- One Way AnovaDocument35 pagesOne Way AnovaNinuca ChanturiaNo ratings yet
- Ma. Elizabeth N. DaosDocument144 pagesMa. Elizabeth N. DaosJeffreydanceljr100% (1)
- Day 1 Python NotebookDocument19 pagesDay 1 Python NotebookAviral SaxenaNo ratings yet
- Multiple Regression ProjectDocument10 pagesMultiple Regression Projectapi-27739305433% (3)
- Chi Square TestDocument9 pagesChi Square TestBella YaakubNo ratings yet
- Resumen Gujarati EconometriaDocument8 pagesResumen Gujarati EconometriaJuventudes Provincia VallecaucanaNo ratings yet
- MASSter - A STAT 101 Tutorial HandoutDocument12 pagesMASSter - A STAT 101 Tutorial HandoutDearly Niña OsinsaoNo ratings yet
- Acp 3080Document13 pagesAcp 3080sophiaw1912No ratings yet
- T-Test and It'S Applications: BY Jyoti Todi Harkamal KaurDocument30 pagesT-Test and It'S Applications: BY Jyoti Todi Harkamal KaurmichelleNo ratings yet
- Paired Samples T TestDocument12 pagesPaired Samples T TestHoney Mae Vergara BarceloNo ratings yet
- Class Notes, Statistical Methods in Research 1Document113 pagesClass Notes, Statistical Methods in Research 1Chance ShaforNo ratings yet
- Section F S-6001 (2008) Bearing Temperature PerformanceDocument2 pagesSection F S-6001 (2008) Bearing Temperature Performanceslowrie151No ratings yet
- StatisticsDocument11 pagesStatisticsTrung Tròn TrịaNo ratings yet
- Significance Testing of Word Frequencies in CorporaDocument52 pagesSignificance Testing of Word Frequencies in CorporamiskoscribdNo ratings yet
- A Study of The Factors That Determine Local NGO Financial Sustainability, A Case of CIDRZDocument11 pagesA Study of The Factors That Determine Local NGO Financial Sustainability, A Case of CIDRZInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Lums Nursing StressDocument6 pagesLums Nursing StressShaukat Ali AmlaniNo ratings yet
- Beating The Bookies With Their Own Numbers - and How The Online Sports Betting Market Is RiggedDocument30 pagesBeating The Bookies With Their Own Numbers - and How The Online Sports Betting Market Is Riggedthunderbringer1100% (2)
- Hypothesis Testing Hand NotreDocument6 pagesHypothesis Testing Hand NotreAmzad DPNo ratings yet
- 307 ImpDocument115 pages307 ImpYash DarajiNo ratings yet
- Tes10 ch08Document123 pagesTes10 ch08deonard solanaNo ratings yet
- HR Research 1Document9 pagesHR Research 1MAHATHMA DALANDASNo ratings yet
- Ap23 FRQ Statistics - Pdf#page 16Document25 pagesAp23 FRQ Statistics - Pdf#page 16malvin.fedyanoNo ratings yet
- Skittles Project 2-6Document8 pagesSkittles Project 2-6api-302525501No ratings yet
- 6 Eijmms Vol5 Issue6 June2015Document6 pages6 Eijmms Vol5 Issue6 June2015Arun R UNo ratings yet
- A Review of Basic Statistical Concepts: Answers To Problems and Cases 1Document227 pagesA Review of Basic Statistical Concepts: Answers To Problems and Cases 1Thiên BìnhNo ratings yet
- Testing The Difference Between Two Means, Two Proportions, and Two VariancesDocument39 pagesTesting The Difference Between Two Means, Two Proportions, and Two VariancesaswardiNo ratings yet
- Effect of Parental Involvement On Self Esteem inDocument9 pagesEffect of Parental Involvement On Self Esteem inswathiNo ratings yet