You might also like
- Geometrical Dimensioning and Tolerancing for Design, Manufacturing and Inspection: A Handbook for Geometrical Product Specification Using ISO and ASME StandardsFrom EverandGeometrical Dimensioning and Tolerancing for Design, Manufacturing and Inspection: A Handbook for Geometrical Product Specification Using ISO and ASME StandardsRating: 4.5 out of 5 stars4.5/5 (3)
- SPE-195804-MS An Artificial Intelligence Approach To Predict The Water Saturation in Carbonate Reservoir RocksDocument15 pagesSPE-195804-MS An Artificial Intelligence Approach To Predict The Water Saturation in Carbonate Reservoir RockshijoetigreNo ratings yet
- SWR 10#3Document1 pageSWR 10#3Wage KarsanaNo ratings yet
- 1 s2.0 S0950423021001066 MainDocument8 pages1 s2.0 S0950423021001066 Mainaglen.ergNo ratings yet
- MSC (Emec) Computer Modelling and Simulation Module Surveying Comminution CircuitsDocument4 pagesMSC (Emec) Computer Modelling and Simulation Module Surveying Comminution CircuitskediliterapiNo ratings yet
- Prediction of Compressive Strength of Self-Compacting Concrete Using Intelligent Computational ModelingDocument18 pagesPrediction of Compressive Strength of Self-Compacting Concrete Using Intelligent Computational ModelingAfaq AhmedNo ratings yet
- Fluid Friction in Pipes Laboratory ReportDocument6 pagesFluid Friction in Pipes Laboratory ReportABamishe0% (1)
- Group2 Topic5 ThickcylinderDocument16 pagesGroup2 Topic5 ThickcylinderMuhd RusyaidiNo ratings yet
- The Complex Method of Estimation of Highway Maintenance Quality Taking Into Account The International Roughness IndexDocument6 pagesThe Complex Method of Estimation of Highway Maintenance Quality Taking Into Account The International Roughness IndextaufiqadwNo ratings yet
- A Novel Statistical Method To Analyze The Competitive Adsorption of Heavy Metal Ions in Aqueous SolutionsDocument5 pagesA Novel Statistical Method To Analyze The Competitive Adsorption of Heavy Metal Ions in Aqueous SolutionsBarathan RajandranNo ratings yet
- National Corn-to-Ethanol Research Center Laboratory Research DivisionDocument7 pagesNational Corn-to-Ethanol Research Center Laboratory Research DivisionShai VillalbaNo ratings yet
- Objectives:: What Does Resistance Depend On?Document4 pagesObjectives:: What Does Resistance Depend On?Rodrigo TavarezNo ratings yet
- Exploration of Pressure Driven Method in Hydraulic Modelling of Water Distribution NetworkDocument8 pagesExploration of Pressure Driven Method in Hydraulic Modelling of Water Distribution NetworkIJRASETPublicationsNo ratings yet
- Geotechnical Engineering 1 Laboratory Manual: Department of Civil EngineeringDocument5 pagesGeotechnical Engineering 1 Laboratory Manual: Department of Civil EngineeringRixer PrietoNo ratings yet
- Correlations Between Relative Density AnDocument8 pagesCorrelations Between Relative Density AnAprilian Vinsensius TimangNo ratings yet
- cutoff تقرير ادارةDocument15 pagescutoff تقرير ادارةix JanNo ratings yet
- 1 4 9 PDFDocument7 pages1 4 9 PDFmatias79No ratings yet
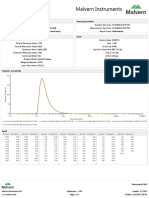
- Malvern Instruments Analysis: Measurement Details Measurement DetailsDocument1 pageMalvern Instruments Analysis: Measurement Details Measurement DetailsqhpuongNo ratings yet
- ISET2019 Extended AbstractDocument9 pagesISET2019 Extended AbstractNaimatul KhoirohNo ratings yet
- Report of Investigation: National Institute of Standards & TechnologyDocument3 pagesReport of Investigation: National Institute of Standards & TechnologyLívia Silvestre AndradeNo ratings yet
- Certificate of Analysis: National Institute of Standards & TechnologyDocument7 pagesCertificate of Analysis: National Institute of Standards & TechnologyCesar BarretoNo ratings yet
- WWW - Supersonic.co - Id Analysis: Measurement Details Measurement DetailsDocument1 pageWWW - Supersonic.co - Id Analysis: Measurement Details Measurement DetailsWage KarsanaNo ratings yet
- WWW - Supersonic.co - Id Analysis: Measurement Details Measurement DetailsDocument1 pageWWW - Supersonic.co - Id Analysis: Measurement Details Measurement DetailsWage KarsanaNo ratings yet
- J Tripleo 2011 02 017Document7 pagesJ Tripleo 2011 02 017Cosmin IfrimNo ratings yet
- Tension TestDocument7 pagesTension Testabdulla abdulkhaliqNo ratings yet
- Particle Size Distribution by LASER Diffraction SPDocument11 pagesParticle Size Distribution by LASER Diffraction SPhamedNo ratings yet
- Paper in TTP Scintific - Net-AuthorsDocument7 pagesPaper in TTP Scintific - Net-AuthorsMohan Kumar Pradhan Associate ProfessorNo ratings yet
- A Note On Saaty'S Random Indexes: CI RIDocument3 pagesA Note On Saaty'S Random Indexes: CI RIcovid19 bebasNo ratings yet
- SkillDocument6 pagesSkillVenkat Chandrakanth ANo ratings yet
- Oup 6Document48 pagesOup 6TAMIZHAN ANo ratings yet
- SCRM No. 666/12 Ductile (Nodular) Iron: L Certificate of AnalysisDocument2 pagesSCRM No. 666/12 Ductile (Nodular) Iron: L Certificate of AnalysisPeterson SudlabNo ratings yet
- OREAS 401 CertificateDocument7 pagesOREAS 401 Certificateflysch_ukNo ratings yet
- Soil Ex3Document5 pagesSoil Ex3Azeezan AlessaNo ratings yet
- Results in PhysicsDocument6 pagesResults in PhysicsaisyahNo ratings yet
- Thesis FinalDocument53 pagesThesis FinalSubrata MondalNo ratings yet
- 1 s2.0 S010956411500319X MainDocument2 pages1 s2.0 S010956411500319X Mainalaa husseinNo ratings yet
- Predicting The Strength of Self-Compacting Self-Curing Concrete Using Artificial Neural NetworkDocument9 pagesPredicting The Strength of Self-Compacting Self-Curing Concrete Using Artificial Neural Networkanbarasan0No ratings yet
- PR Tip IndicatorDocument35 pagesPR Tip IndicatorRullit Urbina SalasNo ratings yet
- Tutorial 5 - Bivariate AnalysisDocument7 pagesTutorial 5 - Bivariate AnalysisNoorNabilaNo ratings yet
- Image Processing Techniques For Velocity, Interface Complexity, and Droplet Production Measurement in The Near-Nozzle Region of A Diesel SprayDocument23 pagesImage Processing Techniques For Velocity, Interface Complexity, and Droplet Production Measurement in The Near-Nozzle Region of A Diesel Spraybayu rahmatNo ratings yet
- Synthesis and Crystal Structures of N-SubstitutedDocument12 pagesSynthesis and Crystal Structures of N-SubstitutedCarolinaZingaliucNo ratings yet
- J Mineng 2010 07 011Document7 pagesJ Mineng 2010 07 011AlbertoNo ratings yet
- Thermal Resistance Field Estimations From IR Thermography Using Multiscale Bayesian InferenceDocument14 pagesThermal Resistance Field Estimations From IR Thermography Using Multiscale Bayesian Inferenceapi-531913674No ratings yet
- Advanced Powder Technology: Takao Ueda, Tatsuya Oki, Shigeki KoyanakaDocument8 pagesAdvanced Powder Technology: Takao Ueda, Tatsuya Oki, Shigeki KoyanakaHARIMETLYNo ratings yet
- Analysis of One-Dimensional Solute Transport of Arsenic in Aquifer Via MT3DMSDocument11 pagesAnalysis of One-Dimensional Solute Transport of Arsenic in Aquifer Via MT3DMSIJRASETPublicationsNo ratings yet
- Basic Calibration of UV/ Visible SpectrophotometerDocument5 pagesBasic Calibration of UV/ Visible SpectrophotometerMeta Zahro KurniaNo ratings yet
- Power and Thrust Measurements of Marine Current Turbines Under Various Hydrodynamic Ow Conditions in A Cavitation Tunnel and A Towing TankDocument20 pagesPower and Thrust Measurements of Marine Current Turbines Under Various Hydrodynamic Ow Conditions in A Cavitation Tunnel and A Towing Tankcristian villegasNo ratings yet
- X RAY DefractionDocument7 pagesX RAY Defractiondulararashmika00No ratings yet
- University of Sharjah: Mechanical Engineering Department Summer 19 Fluid Mechanics LabDocument16 pagesUniversity of Sharjah: Mechanical Engineering Department Summer 19 Fluid Mechanics LabkhalilNo ratings yet
- Drastic Improvement of Change Detection Results With Multilook Complex SAR Images ApproachDocument13 pagesDrastic Improvement of Change Detection Results With Multilook Complex SAR Images Approachnaveen narulaNo ratings yet
- 6.C PSD Microfine May 2020Document1 page6.C PSD Microfine May 2020rakesh prajapatiNo ratings yet
- Design of Experiments For Optimization of Automotive Suspension System Using Quarter Car Test RigDocument8 pagesDesign of Experiments For Optimization of Automotive Suspension System Using Quarter Car Test RigBarot JaynamNo ratings yet
- MicromeriticsDocument60 pagesMicromeriticsamitmgupta3178% (18)
- Richard MinnittDocument39 pagesRichard Minnittgustavoanaya96No ratings yet
- Optimization of Machining Parameters in EDM Process Using Cast and Sintered Copper ElectrodesDocument11 pagesOptimization of Machining Parameters in EDM Process Using Cast and Sintered Copper Electrodesaji setioNo ratings yet
- HDPE Pipe StandardsDocument5 pagesHDPE Pipe StandardsFAHAD HASSANNo ratings yet
- Powder CharacterizationDocument21 pagesPowder CharacterizationecternalNo ratings yet
- Application of RANS and LES Based CFD To Predict The Short and Long Term Distribution and Mixing of Hydrogen in A Large EnclosureDocument14 pagesApplication of RANS and LES Based CFD To Predict The Short and Long Term Distribution and Mixing of Hydrogen in A Large EnclosureParvane SadeghipourNo ratings yet
- Acoustic Sensor For Powder FlowDocument18 pagesAcoustic Sensor For Powder FlowDileep GangwarNo ratings yet
- 15 Professional Development Skills For Modern TeachersDocument3 pages15 Professional Development Skills For Modern TeachersAndevie Balili IguanaNo ratings yet
- ASTM C881 2013 - Epoxy Resin Base Bonding System For ConcreteDocument6 pagesASTM C881 2013 - Epoxy Resin Base Bonding System For Concretetsalemnoush100% (1)
- Causal Essay OutlineDocument7 pagesCausal Essay Outlinemiwaj0pabuk2100% (2)
- Chapter 3Document47 pagesChapter 3yasinNo ratings yet
- Mechanism and Mechanical Vibration (Lab Work) Teaching PlanDocument8 pagesMechanism and Mechanical Vibration (Lab Work) Teaching PlanBelia NomeNo ratings yet
- I Integral Equations and Operator TheoryDocument20 pagesI Integral Equations and Operator TheoryLunas BinNo ratings yet
- Lab Grown MeatDocument17 pagesLab Grown MeatSaya SufiaNo ratings yet
- ភស���រកម� ១.០ (Mechanization of Transport) : កម��� ៤.០ - Cambodia 4.0Document4 pagesភស���រកម� ១.០ (Mechanization of Transport) : កម��� ៤.០ - Cambodia 4.0Cheng vatraNo ratings yet
- Rural - Materials & ConstructionDocument12 pagesRural - Materials & ConstructionHaresh Babu PitchaimaniNo ratings yet
- Chapter 8: More Number TheoryDocument5 pagesChapter 8: More Number TheoryOmnia GalalNo ratings yet
- New Holland E140CSR Crawler Excavator Service Repair ManualDocument21 pagesNew Holland E140CSR Crawler Excavator Service Repair ManualggjjjjotonesNo ratings yet
- Telephone EtiquettesDocument37 pagesTelephone EtiquettesAmit SrivastavaNo ratings yet
- ASTM D4006 - 16e1Document11 pagesASTM D4006 - 16e1Angel MurilloNo ratings yet
- WahbaDocument21 pagesWahbahricha aryalNo ratings yet
- Graphs of A Piecewise Linear FunctionDocument11 pagesGraphs of A Piecewise Linear FunctionRex Lemuel AndesNo ratings yet
- Addis Ababa Science & Technology University: College of Electrical & Mechanical EngineeringDocument91 pagesAddis Ababa Science & Technology University: College of Electrical & Mechanical Engineeringliyou eshetuNo ratings yet
- NFS Concoctions Revised Oa NC IiDocument8 pagesNFS Concoctions Revised Oa NC IiArts IanNo ratings yet
- The Idea of ProgressDocument1 pageThe Idea of Progressvictor carre poussinNo ratings yet
- CLPWDocument13 pagesCLPWRoselyn Lictawa Dela CruzNo ratings yet
- Applied Behavior Analysis Cooper 2nd Edition Test BankDocument5 pagesApplied Behavior Analysis Cooper 2nd Edition Test Bankzacharygonzalezqwjsambgny100% (43)
- Wind System in The WorldDocument4 pagesWind System in The WorldFarrel LeroyNo ratings yet
- MCS-SHS Students' Publication GuidelinesDocument2 pagesMCS-SHS Students' Publication GuidelinesErrol De LeonNo ratings yet
- Zorlu Zemin Şartlarında EPB TBM Tünelciliği: Ataköy - İkitelli Metro Tünelinde Örnek Bir Çalışma, TürkiyeDocument7 pagesZorlu Zemin Şartlarında EPB TBM Tünelciliği: Ataköy - İkitelli Metro Tünelinde Örnek Bir Çalışma, TürkiyecemalbalciNo ratings yet
- Chapter 5Document24 pagesChapter 5Nayama NayamaNo ratings yet
- Annual Exam Syllabus Class IVDocument3 pagesAnnual Exam Syllabus Class IVMuhammad AliNo ratings yet
- Scuderi Split Cycle EngineDocument8 pagesScuderi Split Cycle EnginefalconnNo ratings yet
- "Why Don't We Complain" by William F. Buckley Jr.Document1 page"Why Don't We Complain" by William F. Buckley Jr.Tavar HerbertNo ratings yet
- Ddc2256a FinalDocument47 pagesDdc2256a Final박혜인No ratings yet
- 1 s2.0 S2452321618301161 Main PDFDocument8 pages1 s2.0 S2452321618301161 Main PDFsidNo ratings yet
- Headache Orofacial Pain and Bruxism - Selvaratnam PDFDocument377 pagesHeadache Orofacial Pain and Bruxism - Selvaratnam PDFLukas100% (1)