You might also like
- Handling Missing DataDocument21 pagesHandling Missing DataJenny CastilloNo ratings yet
- Think Globally, Fit LocallyDocument33 pagesThink Globally, Fit LocallyAli Umair KhanNo ratings yet
- Case Study 219302405Document14 pagesCase Study 219302405nishantjain2k03No ratings yet
- MATLAB Based Graphical User Interface GUI For Data Mining As A Tool For Environment Management LibreDocument8 pagesMATLAB Based Graphical User Interface GUI For Data Mining As A Tool For Environment Management LibreakshukNo ratings yet
- 2006 Use of The Interacting Multiple Model Algorithm With Multiple SensorsDocument10 pages2006 Use of The Interacting Multiple Model Algorithm With Multiple SensorsMohamed Hechmi JERIDINo ratings yet
- Evaluating Aptness of A Regression ModelDocument15 pagesEvaluating Aptness of A Regression Modelmazin903No ratings yet
- Synthetic Generation of High Dimensional DatasetDocument8 pagesSynthetic Generation of High Dimensional Datasetmohammad nasir AbdullahNo ratings yet
- Very Fast Estimation For Result and Accuracy of Big Data Analytics: The EARL SystemDocument4 pagesVery Fast Estimation For Result and Accuracy of Big Data Analytics: The EARL SystemDxtr MedinaNo ratings yet
- Estimation of Software Defects Fix Effort Using Neural NetworksDocument2 pagesEstimation of Software Defects Fix Effort Using Neural NetworksSpeedSrlNo ratings yet
- 1 s2.0 S0016003221000739 MainDocument38 pages1 s2.0 S0016003221000739 MainArshad AliNo ratings yet
- Observability of Power Systems Based On Fast Pseudorank Calculation of Sparse Sensitivity MatricesDocument6 pagesObservability of Power Systems Based On Fast Pseudorank Calculation of Sparse Sensitivity Matricesjaved shaikh chaandNo ratings yet
- Information Sciences: Pekka Kumpulainen, Kimmo HätönenDocument20 pagesInformation Sciences: Pekka Kumpulainen, Kimmo HätönenNora Alaa El-dinNo ratings yet
- Streaming Algorithms For Data in MotionDocument11 pagesStreaming Algorithms For Data in MotionLiel BudilovskyNo ratings yet
- Publi 2020 IJNME Ghanem Soize Mehrez Aitharaju PreprintDocument22 pagesPubli 2020 IJNME Ghanem Soize Mehrez Aitharaju PreprintTathagato BoseNo ratings yet
- Fnal+Report Advance+StatisticsDocument44 pagesFnal+Report Advance+StatisticsPranav Viswanathan100% (1)
- Operations Research Applications in The Field of Information and CommunicationDocument6 pagesOperations Research Applications in The Field of Information and CommunicationrushabhrakholiyaNo ratings yet
- NETEXTRACT - Extracting Belief Networks in Telecommunications DataDocument9 pagesNETEXTRACT - Extracting Belief Networks in Telecommunications Datansantos5847No ratings yet
- InavDocument5 pagesInavscap1784No ratings yet
- Development and Implementation of Artificial Neural Networks For Intrusion Detection in Computer NetworkDocument5 pagesDevelopment and Implementation of Artificial Neural Networks For Intrusion Detection in Computer Networks.pawar.19914262No ratings yet
- A Fucking Amazing PaperDocument6 pagesA Fucking Amazing PaperwerallgayNo ratings yet
- Complexity Problems Handled by Big Data Prepared by Shreeya SharmaDocument9 pagesComplexity Problems Handled by Big Data Prepared by Shreeya SharmaPrincy SharmaNo ratings yet
- Data Mining CaseBrasilTelecomDocument15 pagesData Mining CaseBrasilTelecomMarcio SilvaNo ratings yet
- Irjet V5i9192 PDFDocument6 pagesIrjet V5i9192 PDFPRSNo ratings yet
- Model-Based Avionic Prognostic Reasoner (MAPR) PDFDocument9 pagesModel-Based Avionic Prognostic Reasoner (MAPR) PDFlalith.shankar7971No ratings yet
- Nonlinear Regression Using EXCEL SolverDocument10 pagesNonlinear Regression Using EXCEL SolverRalph John UgalinoNo ratings yet
- Computer Rental System ThesisDocument4 pagesComputer Rental System Thesistaniaknappanchorage100% (2)
- Linear Regression Using R - An Introduction To Data ModelingDocument69 pagesLinear Regression Using R - An Introduction To Data ModelingGEna naNo ratings yet
- Anomaly Detection and Classification Using DT and DLDocument10 pagesAnomaly Detection and Classification Using DT and DLbarracudaNo ratings yet
- AbstractsDocument3 pagesAbstractsManju ScmNo ratings yet
- Deep Learning Based Soft Sensor and Its Application On A Pyrolysis Reactor For Compositions Predictions of Gas Phase ComponentsDocument6 pagesDeep Learning Based Soft Sensor and Its Application On A Pyrolysis Reactor For Compositions Predictions of Gas Phase Componentsmice LiNo ratings yet
- 3481 PDFDocument8 pages3481 PDFChikh YassineNo ratings yet
- P-149 Final PPTDocument57 pagesP-149 Final PPTVijay rathodNo ratings yet
- ReportDocument54 pagesReportKesehoNo ratings yet
- Sensors: Conditional Variational Autoencoder For Prediction and Feature Recovery Applied To Intrusion Detection in IotDocument17 pagesSensors: Conditional Variational Autoencoder For Prediction and Feature Recovery Applied To Intrusion Detection in IotAnanya ParameswaranNo ratings yet
- Article in Press: Recognition of Control Chart Patterns Using An Intelligent TechniqueDocument11 pagesArticle in Press: Recognition of Control Chart Patterns Using An Intelligent TechniquesreeshpsNo ratings yet
- A Structured Approach To NeuralDocument8 pagesA Structured Approach To NeuralBalaji SankaralingamNo ratings yet
- MCSE011Document18 pagesMCSE011Anusree AntonyNo ratings yet
- Journal of Statistical Software: Multiple Imputation With Diagnostics (Mi) in R: Opening Windows Into The Black BoxDocument31 pagesJournal of Statistical Software: Multiple Imputation With Diagnostics (Mi) in R: Opening Windows Into The Black BoxAbi ZuñigaNo ratings yet
- Power FactoryDocument9 pagesPower Factorypmahesh268No ratings yet
- Ieee Research Papers On Pattern RecognitionDocument6 pagesIeee Research Papers On Pattern Recognitionhumin1byjig2100% (1)
- An Overview of Discrete Event Simulation Methodologies and ImplementationDocument17 pagesAn Overview of Discrete Event Simulation Methodologies and ImplementationMadhuSudhan KrishnamurthyNo ratings yet
- Algebra SoftwareDocument13 pagesAlgebra SoftwareUmesh MundhraNo ratings yet
- Assessing Software Reliability Using Modified Genetic Algorithm: Inflection S-Shaped ModelDocument6 pagesAssessing Software Reliability Using Modified Genetic Algorithm: Inflection S-Shaped ModelAnonymous lPvvgiQjRNo ratings yet
- Forex - Nnet Vs RegDocument6 pagesForex - Nnet Vs RegAnshik BansalNo ratings yet
- Ijcrti020009 4Document1 pageIjcrti020009 4modib38863No ratings yet
- Data Mining Project 11Document18 pagesData Mining Project 11Abraham ZelekeNo ratings yet
- Implementation of Knowledge-Based Expert System Using Probabilistic Network ModelsDocument4 pagesImplementation of Knowledge-Based Expert System Using Probabilistic Network ModelsEditor IJRITCCNo ratings yet
- Parallel ProcessingDocument5 pagesParallel ProcessingMustafa Al-NaimiNo ratings yet
- Calibration of Software Quality: Fuzzy Neural and Rough Neural Computing ApproachesDocument4 pagesCalibration of Software Quality: Fuzzy Neural and Rough Neural Computing Approachesjatin1001No ratings yet
- Anomaly Prediction in Mobile Networks: A Data Driven Approach For Machine Learning Algorithm SelectionDocument7 pagesAnomaly Prediction in Mobile Networks: A Data Driven Approach For Machine Learning Algorithm SelectionLanceloth01No ratings yet
- Education - Post 12th Standard - CSVDocument11 pagesEducation - Post 12th Standard - CSVRuhee's KitchenNo ratings yet
- Anomalous Topic Discovery in High Dimensional Discrete DataDocument4 pagesAnomalous Topic Discovery in High Dimensional Discrete DataBrightworld ProjectsNo ratings yet
- Optimized Design of Parity Relation-Based Residual Generator For Fault Detection Data-Driven ApproachesDocument10 pagesOptimized Design of Parity Relation-Based Residual Generator For Fault Detection Data-Driven ApproachesDr.Suresh Chavhan -IIITKNo ratings yet
- Data Mining 2-5Document4 pagesData Mining 2-5nirman kumarNo ratings yet
- Discovering Similarity Measures in Software by Using Mining GraphsDocument3 pagesDiscovering Similarity Measures in Software by Using Mining GraphsRakeshconclaveNo ratings yet
- Process Performance Models: Statistical, Probabilistic & SimulationFrom EverandProcess Performance Models: Statistical, Probabilistic & SimulationNo ratings yet
- Annal Investigation of Suffix TreesDocument7 pagesAnnal Investigation of Suffix TreesJ Christian OdehnalNo ratings yet
- Cellpad: Detecting Performance Anomalies in Cellular Networks Via Regression AnalysisDocument9 pagesCellpad: Detecting Performance Anomalies in Cellular Networks Via Regression AnalysisahlemNo ratings yet
- Scale Invariant Feature Transform: Unveiling the Power of Scale Invariant Feature Transform in Computer VisionFrom EverandScale Invariant Feature Transform: Unveiling the Power of Scale Invariant Feature Transform in Computer VisionNo ratings yet
- Compare - Dss and Bi PDFDocument6 pagesCompare - Dss and Bi PDFSharmila SaravananNo ratings yet
- Business Intelligence - Telecom IndustryDocument6 pagesBusiness Intelligence - Telecom IndustrySharmila SaravananNo ratings yet
- Agent Intelligence Through DMDocument135 pagesAgent Intelligence Through DMSharmila SaravananNo ratings yet
- The Particle Swarm Optimization AlgorithmDocument18 pagesThe Particle Swarm Optimization AlgorithmSharmila SaravananNo ratings yet
- Multi-Objective Optimization Using Particle Swarm OptimizationDocument46 pagesMulti-Objective Optimization Using Particle Swarm OptimizationSharmila SaravananNo ratings yet
- Gene Expression ProgrammingDocument24 pagesGene Expression ProgrammingSharmila SaravananNo ratings yet
- Lecture Notes For Chapter 5: by Tan, Steinbach, KumarDocument88 pagesLecture Notes For Chapter 5: by Tan, Steinbach, KumarSharmila Saravanan0% (1)
- Delegated Legislation - PaperDocument14 pagesDelegated Legislation - PaperSharmila SaravananNo ratings yet
- Data Mining Definition: - Finding Hidden Information in A Database - Similar TermsDocument25 pagesData Mining Definition: - Finding Hidden Information in A Database - Similar TermsSharmila SaravananNo ratings yet
- Artificial Bee Colony (ABC) AlgorithmDocument18 pagesArtificial Bee Colony (ABC) AlgorithmSharmila Saravanan100% (1)
- Classification and PredictionDocument31 pagesClassification and PredictionSharmila Saravanan100% (1)
- Classification Algorithms: Chapter 11, "Decision Tree"Document10 pagesClassification Algorithms: Chapter 11, "Decision Tree"Sharmila SaravananNo ratings yet
- Network Security: Presented byDocument24 pagesNetwork Security: Presented bySharmila SaravananNo ratings yet
- Project Finance1Document28 pagesProject Finance1Sharmila SaravananNo ratings yet
- 16 Mark Questions OOADDocument9 pages16 Mark Questions OOADsaravanan_saptc100% (2)
- La Salle Lipa Integrated School Senior High School Community 1 Quarter Summative Assessment Earth Science AY 2021-2022 Household Conservation PlanDocument4 pagesLa Salle Lipa Integrated School Senior High School Community 1 Quarter Summative Assessment Earth Science AY 2021-2022 Household Conservation PlanKarlle ObviarNo ratings yet
- LICDocument82 pagesLICTinu Burmi Anand100% (2)
- Proposal For Chemical Shed at Keraniganj - 15.04.21Document14 pagesProposal For Chemical Shed at Keraniganj - 15.04.21HabibNo ratings yet
- Rs 422Document1 pageRs 422rezakaihaniNo ratings yet
- Hitt PPT 12e ch08-SMDocument32 pagesHitt PPT 12e ch08-SMHananie NanieNo ratings yet
- Leeka Kheifets PrincipleDocument6 pagesLeeka Kheifets PrincipleAlexandreau del FierroNo ratings yet
- Design & Construction of New River Bridge On Mula RiverDocument133 pagesDesign & Construction of New River Bridge On Mula RiverJalal TamboliNo ratings yet
- EW160 AlarmsDocument12 pagesEW160 AlarmsIgor MaricNo ratings yet
- Steam Source Book PDFDocument108 pagesSteam Source Book PDFJose Levican A100% (1)
- Allplan 2006 Engineering Tutorial PDFDocument374 pagesAllplan 2006 Engineering Tutorial PDFEvelin EsthefaniaNo ratings yet
- Pro Tools ShortcutsDocument5 pagesPro Tools ShortcutsSteveJones100% (1)
- Admissibility of Whatsapp Messages in Court For Family MattersDocument3 pagesAdmissibility of Whatsapp Messages in Court For Family Mattersnajihah adeliNo ratings yet
- NIELIT Scientist B' Recruitment 2016 - Computer Science - GeeksforGeeksDocument15 pagesNIELIT Scientist B' Recruitment 2016 - Computer Science - GeeksforGeeksChristopher HerringNo ratings yet
- Gis Tabels 2014 15Document24 pagesGis Tabels 2014 15seprwglNo ratings yet
- Design of Flyback Transformers and Filter Inductor by Lioyd H.dixon, Jr. Slup076Document11 pagesDesign of Flyback Transformers and Filter Inductor by Lioyd H.dixon, Jr. Slup076Burlacu AndreiNo ratings yet
- Introduction To AirtelDocument6 pagesIntroduction To AirtelPriya Gupta100% (1)
- Go Ask Alice EssayDocument6 pagesGo Ask Alice Essayafhbexrci100% (2)
- Dmta 20043 01en Omniscan SX UserDocument90 pagesDmta 20043 01en Omniscan SX UserwenhuaNo ratings yet
- Milestone 9 For WebsiteDocument17 pagesMilestone 9 For Websiteapi-238992918No ratings yet
- Gravity Based Foundations For Offshore Wind FarmsDocument121 pagesGravity Based Foundations For Offshore Wind FarmsBent1988No ratings yet
- Revit 2019 Collaboration ToolsDocument80 pagesRevit 2019 Collaboration ToolsNoureddineNo ratings yet
- Preventive Maintenance - HematologyDocument5 pagesPreventive Maintenance - HematologyBem GarciaNo ratings yet
- BSBOPS601 Develop Implement Business Plans - SDocument91 pagesBSBOPS601 Develop Implement Business Plans - SSudha BarahiNo ratings yet
- Paul Milgran - A Taxonomy of Mixed Reality Visual DisplaysDocument11 pagesPaul Milgran - A Taxonomy of Mixed Reality Visual DisplaysPresencaVirtual100% (1)
- Final Project Report GMS BtechDocument68 pagesFinal Project Report GMS Btech02Musaib Ul FayazNo ratings yet
- The Role of OrganisationDocument9 pagesThe Role of OrganisationMadhury MosharrofNo ratings yet
- The "Solid Mount": Installation InstructionsDocument1 pageThe "Solid Mount": Installation InstructionsCraig MathenyNo ratings yet
- Marley Product Catalogue Brochure Grease TrapsDocument1 pageMarley Product Catalogue Brochure Grease TrapsKushalKallychurnNo ratings yet
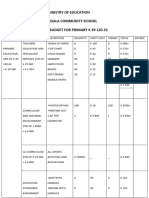
- Ministry of Education Musala SCHDocument5 pagesMinistry of Education Musala SCHlaonimosesNo ratings yet