You might also like
- Hierarchical Program Representation For Program Element MatchingDocument10 pagesHierarchical Program Representation For Program Element MatchingLeonardo MatteraNo ratings yet
- Automatic Test Case Generation of C Program Using CFGDocument5 pagesAutomatic Test Case Generation of C Program Using CFGchiragjindalNo ratings yet
- Explicit-Value Analysis Based On CEGAR and Interpolation: Dirk Beyer and Stefan L OweDocument12 pagesExplicit-Value Analysis Based On CEGAR and Interpolation: Dirk Beyer and Stefan L Owetrial6844No ratings yet
- Visual Basic Application For Statistical Process Control: A Case of Metal Frame For Actuator Production ProcessDocument6 pagesVisual Basic Application For Statistical Process Control: A Case of Metal Frame For Actuator Production ProcessDanny WatsonNo ratings yet
- MKRDocument34 pagesMKRVani RajasekharNo ratings yet
- Metrics & Cost Estimation.Document22 pagesMetrics & Cost Estimation.nespijorziNo ratings yet
- Discovering Similarity Measures in Software by Using Mining GraphsDocument3 pagesDiscovering Similarity Measures in Software by Using Mining GraphsRakeshconclaveNo ratings yet
- Paper 24-Comparison and Analysis of Different Software Cost Estimation MethodsDocument5 pagesPaper 24-Comparison and Analysis of Different Software Cost Estimation MethodsEditor IJACSANo ratings yet
- Oakland 10Document15 pagesOakland 10metatron13No ratings yet
- Abstracting Dependencies Between Software Conguration Items: Abstract Interpretation Description LesDocument14 pagesAbstracting Dependencies Between Software Conguration Items: Abstract Interpretation Description LesbromlantNo ratings yet
- Program Slicing Techniques and Its ApplicationsDocument15 pagesProgram Slicing Techniques and Its ApplicationsijseaNo ratings yet
- Ece I Programming in C Data Structures 15PCD13 Solution PDFDocument46 pagesEce I Programming in C Data Structures 15PCD13 Solution PDFChethana NarayanNo ratings yet
- Automated Test GenerationDocument10 pagesAutomated Test GenerationUsman AliNo ratings yet
- Data Flow Coverage For Testing Erlang ProgramsDocument16 pagesData Flow Coverage For Testing Erlang Programspkp1987No ratings yet
- Concurrent Program Verification With Lazy Sequentialization and Interval AnalysisDocument17 pagesConcurrent Program Verification With Lazy Sequentialization and Interval AnalysisGeorgeNo ratings yet
- Arx 20Document18 pagesArx 20Nabilla FebryNo ratings yet
- From Quads To GraphsDocument29 pagesFrom Quads To Graphsjoy LiuNo ratings yet
- Shift Register Petri NetDocument7 pagesShift Register Petri NetEduNo ratings yet
- Using Genetic Programming To Evolve Detection Strategies For Object-Oriented Design FlawsDocument9 pagesUsing Genetic Programming To Evolve Detection Strategies For Object-Oriented Design Flawsdavidmaya2006No ratings yet
- Objectives:: ES 01A - Computer Fundamentals and ProgrammingDocument42 pagesObjectives:: ES 01A - Computer Fundamentals and ProgrammingJovy0% (1)
- A Hybrid Branch Prediction Scheme: An Integration of Software and Hardware TechniquesDocument8 pagesA Hybrid Branch Prediction Scheme: An Integration of Software and Hardware Techniquesvka_princeNo ratings yet
- 17IT8029Document7 pages17IT8029AlexNo ratings yet
- Backwards-Compatible Bounds Checking For Arrays and Pointers in C ProgramsDocument14 pagesBackwards-Compatible Bounds Checking For Arrays and Pointers in C Programspix3l_2No ratings yet
- Lazy Sequentialization For The Safety Verification of Unbounded Concurrent ProgramsDocument18 pagesLazy Sequentialization For The Safety Verification of Unbounded Concurrent ProgramsGeorgeNo ratings yet
- A Software Metrics Case StudyDocument9 pagesA Software Metrics Case Studynagesh_vejjuNo ratings yet
- Final Stage For Cocomo Using PCADocument8 pagesFinal Stage For Cocomo Using PCAVikas MahurkarNo ratings yet
- Tutorial On High-Level Synthesis: and WeDocument7 pagesTutorial On High-Level Synthesis: and WeislamsamirNo ratings yet
- Classification of Collected Research PapersDocument5 pagesClassification of Collected Research Papersnavinkrsehgal23No ratings yet
- Scheduling Using Genetic AlgorithmsDocument8 pagesScheduling Using Genetic Algorithmsashish88bhardwaj_314No ratings yet
- AIDS - DM Using Python - Lab ProgramsDocument19 pagesAIDS - DM Using Python - Lab ProgramsyelubandirenukavidyadhariNo ratings yet
- SEDocument78 pagesSESyed Hamza KazmiNo ratings yet
- 4Document20 pages4wyh630No ratings yet
- Floating Point To FixedDocument15 pagesFloating Point To Fixedcnt2sskNo ratings yet
- Mining Weather Data Using RattleDocument6 pagesMining Weather Data Using RattleijcsnNo ratings yet
- Software Cost Estimation Through Entity Relationship Model: AbstractDocument5 pagesSoftware Cost Estimation Through Entity Relationship Model: AbstractSyed Shah MuhammadNo ratings yet
- Efficient Derivative Codes Through Automatic Differentiation and Interface Contraction: Application in BiostatisticsDocument13 pagesEfficient Derivative Codes Through Automatic Differentiation and Interface Contraction: Application in Biostatisticsgorot1No ratings yet
- Lesson 2 Flowchart Vs Algorithm Using C ProgramDocument9 pagesLesson 2 Flowchart Vs Algorithm Using C ProgramJontex 254No ratings yet
- Adaptive Online Program AnalysisDocument10 pagesAdaptive Online Program AnalysisPiya DeNo ratings yet
- ECEE2 - Lecture 3 - FlowchartingDocument3 pagesECEE2 - Lecture 3 - FlowchartingJheZz MasinsinNo ratings yet
- Group 7: Software MetricsDocument9 pagesGroup 7: Software Metricslynn zigaraNo ratings yet
- Model Checking For Generation of Test SuitesDocument6 pagesModel Checking For Generation of Test SuitesNorozKhanNo ratings yet
- Evaluation and Comparison of Program Slicing Tools: by Tommy HoffnerDocument67 pagesEvaluation and Comparison of Program Slicing Tools: by Tommy HoffnerhewholivedNo ratings yet
- MC0061 AnswersDocument41 pagesMC0061 AnswersRajendra KoliNo ratings yet
- Beating C in Scientific Computing Applications: On The Behavior and Performance of L, Part 1Document12 pagesBeating C in Scientific Computing Applications: On The Behavior and Performance of L, Part 1cluxNo ratings yet
- Software Model Checking Via Large BlockDocument8 pagesSoftware Model Checking Via Large BlockZsófia ÁdámNo ratings yet
- An Introduction To Parametric EstimatingDocument7 pagesAn Introduction To Parametric EstimatinggenergiaNo ratings yet
- BCA 1st Programming in CaaaDocument130 pagesBCA 1st Programming in CaaaKrishna SahuNo ratings yet
- Document 3Document16 pagesDocument 3Su BoccardNo ratings yet
- Computer Programming Lab ManualDocument159 pagesComputer Programming Lab ManualMuhammad AttiqueNo ratings yet
- An Efficient K-Means Clustering AlgorithmDocument6 pagesAn Efficient K-Means Clustering Algorithmgeorge_43No ratings yet
- Acquired Experiences With Computational Tool MS SV Used in Electronic Circuit DesignDocument12 pagesAcquired Experiences With Computational Tool MS SV Used in Electronic Circuit DesignKhadar BashaNo ratings yet
- Document 4Document16 pagesDocument 4Su BoccardNo ratings yet
- Lect9 Ch9 Unit4 Part1Document29 pagesLect9 Ch9 Unit4 Part1Katie ChristianNo ratings yet
- Pgo NotesDocument10 pagesPgo NotesYang ElioNo ratings yet
- A Machine-Learning Algorithm With Disjunctive ModelDocument41 pagesA Machine-Learning Algorithm With Disjunctive ModelTaolue ChenNo ratings yet
- A Review of Spreadsheet Usage in Chemical Engineering CalculationsDocument14 pagesA Review of Spreadsheet Usage in Chemical Engineering Calculationsm.shehreyar.khan100% (1)
- Programming in C Unit-IDocument30 pagesProgramming in C Unit-IAnonymous 2RPHLJCECdNo ratings yet
- 1 - Program Logic FormulationDocument60 pages1 - Program Logic FormulationHoney Girl100% (2)
- Chapter 12 My Nursing Test BanksDocument10 pagesChapter 12 My Nursing Test Banksنمر نصار100% (1)
- 27 EtdsDocument29 pages27 EtdsSuhag PatelNo ratings yet
- Momi BhattacharyaDocument59 pagesMomi BhattacharyamohchinbokhtiyarNo ratings yet
- Fichas Slate HoneywellDocument1 pageFichas Slate HoneywellING CARLOS RAMOSNo ratings yet
- Saint Albert Polytechnic College, Inc. Bachelor of Science in Office AdministrationDocument15 pagesSaint Albert Polytechnic College, Inc. Bachelor of Science in Office AdministrationAustin Grey Pineda MacoteNo ratings yet
- Proposal Defense Form Chapter 1 3Document3 pagesProposal Defense Form Chapter 1 3Jason BinondoNo ratings yet
- Transportation UnitDocument3 pagesTransportation UnitShannon MartinNo ratings yet
- Non-Display Industrial Computers: User ManualDocument100 pagesNon-Display Industrial Computers: User ManualJason100% (1)
- PlagarisimDocument2 pagesPlagarisimabdullah0336.juttNo ratings yet
- Chapter 17Document78 pagesChapter 17Romar PanopioNo ratings yet
- Lecture Notes For Transition To Advanced MathematicsDocument115 pagesLecture Notes For Transition To Advanced MathematicsAngela WaltersNo ratings yet
- Meeting Wise Agenda TemplateDocument1 pageMeeting Wise Agenda Templateapi-416923934No ratings yet
- Evolution of Management TheoriesDocument20 pagesEvolution of Management TheoriesKanishq BawejaNo ratings yet
- Listening Test 1.1Document2 pagesListening Test 1.1momobear152No ratings yet
- ббббббббббббDocument7 pagesббббббббббббhug1515No ratings yet
- LearnEnglish Reading B1 A Conference ProgrammeDocument4 pagesLearnEnglish Reading B1 A Conference ProgrammeAylen DaianaNo ratings yet
- Technology As A Way of RevealingDocument51 pagesTechnology As A Way of RevealingElla Mae Layar100% (1)
- Philosophy 101Document8 pagesPhilosophy 101scribd5846No ratings yet
- GAT General - Sample PaperDocument10 pagesGAT General - Sample PaperAltaf AhmadNo ratings yet
- HiPerMat 2012 KasselDocument1,059 pagesHiPerMat 2012 KasselAna Mafalda MatosNo ratings yet
- Canada Post ReportDocument202 pagesCanada Post ReportrgranatsteinNo ratings yet
- Capillary PressureDocument12 pagesCapillary PressureamahaminerNo ratings yet
- Lab 18 - Images of Concave and Convex Mirrors 1Document4 pagesLab 18 - Images of Concave and Convex Mirrors 1api-458764744No ratings yet
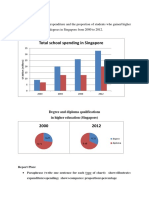
- Total School Spending in Singapore: Task 1 020219Document6 pagesTotal School Spending in Singapore: Task 1 020219viper_4554No ratings yet
- Vertical Axis Wind Turbine ProjDocument2 pagesVertical Axis Wind Turbine Projmacsan sanchezNo ratings yet
- Developing An OutlineDocument18 pagesDeveloping An OutlineEnrico Dela CruzNo ratings yet
- Kolban's Book On C.H.I.P.Document317 pagesKolban's Book On C.H.I.P.thiagocabral88No ratings yet
- Integrated Cost and Risk Analysis Using Monte Carlo Simulation of A CPM ModelDocument4 pagesIntegrated Cost and Risk Analysis Using Monte Carlo Simulation of A CPM ModelPavlos Vardoulakis0% (1)
- A Tribute To Fernando L. L. B. Carneiro (1913 - 2001)Document2 pagesA Tribute To Fernando L. L. B. Carneiro (1913 - 2001)Roberto Urrutia100% (1)
- Problem Solving and Algorithms: Problems, Solutions, and ToolsDocument12 pagesProblem Solving and Algorithms: Problems, Solutions, and ToolsskarthikpriyaNo ratings yet