You might also like
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- COMP2101 / CS20S - Discrete Mathematics Generating Functions and Recurrence RelationsDocument7 pagesCOMP2101 / CS20S - Discrete Mathematics Generating Functions and Recurrence RelationsjevanjuniorNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Affective DomainDocument3 pagesAffective DomainJm Enriquez Dela Cruz50% (2)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5795)
- Joshi C M, Vyas Y - Extensions of Certain Classical Integrals of Erdélyi For Gauss Hypergeometric Functions - J. Comput. and Appl. Mat. 160 (2003) 125-138Document14 pagesJoshi C M, Vyas Y - Extensions of Certain Classical Integrals of Erdélyi For Gauss Hypergeometric Functions - J. Comput. and Appl. Mat. 160 (2003) 125-138Renee BravoNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Tips Experiments With MatlabDocument190 pagesTips Experiments With MatlabVishalNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Materi Pak ARIEF LAGA PUTRADocument32 pagesMateri Pak ARIEF LAGA PUTRAUnggul Febrian PangestuNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- TELEMAC Code InstructionsDocument3 pagesTELEMAC Code Instructionskim lee pooNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Disneyland (Manish N Suraj)Document27 pagesDisneyland (Manish N Suraj)Suraj Kedia0% (1)
- Observation Method in Qualitative ResearchDocument42 pagesObservation Method in Qualitative Researchsantoshipoudel08No ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Assignment Diffraction 2016Document3 pagesAssignment Diffraction 2016Ritesh MeelNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- USACODocument94 pagesUSACOLyokoPotterNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Math Internal Assessment:: Investigating Parametric Equations in Motion ProblemsDocument16 pagesMath Internal Assessment:: Investigating Parametric Equations in Motion ProblemsByron JimenezNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Evaluation FormDocument3 pagesEvaluation FormFreyjaa MabelinNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Brandi Jones-5e-Lesson-Plan 2Document3 pagesBrandi Jones-5e-Lesson-Plan 2api-491136095No ratings yet
- Bergson, The Philosophy of ChangeDocument104 pagesBergson, The Philosophy of ChangeSoha Hassan Youssef100% (2)
- Vertical Axis Wind Turbine ProjDocument2 pagesVertical Axis Wind Turbine Projmacsan sanchezNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Curriculum Vitae: Name: Father S Name: Cell No: Email: Date of Birth: Nationality: Cnic No: Passport No: AddressDocument2 pagesCurriculum Vitae: Name: Father S Name: Cell No: Email: Date of Birth: Nationality: Cnic No: Passport No: AddressJahanzeb JojiNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- SLC 10 ScienceDocument16 pagesSLC 10 SciencePffflyers KurnawanNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Iron Warrior: Volume 25, Issue 11Document8 pagesThe Iron Warrior: Volume 25, Issue 11The Iron WarriorNo ratings yet
- Segmented Shaft Seal Brochure Apr 08Document4 pagesSegmented Shaft Seal Brochure Apr 08Zohaib AnserNo ratings yet
- B.tech - Non Credit Courses For 2nd Year StudentsDocument4 pagesB.tech - Non Credit Courses For 2nd Year StudentsNishant MishraNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Critical Point of View: A Wikipedia ReaderDocument195 pagesCritical Point of View: A Wikipedia Readerrll307No ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Lab 18 - Images of Concave and Convex Mirrors 1Document4 pagesLab 18 - Images of Concave and Convex Mirrors 1api-458764744No ratings yet
- SN Conceptual & Strategic SellingDocument34 pagesSN Conceptual & Strategic Sellingayushdixit100% (1)
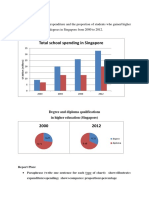
- Total School Spending in Singapore: Task 1 020219Document6 pagesTotal School Spending in Singapore: Task 1 020219viper_4554No ratings yet
- 21st Cent Lit DLP KimDocument7 pages21st Cent Lit DLP KimKim BandolaNo ratings yet
- Culvert Design Write UpDocument8 pagesCulvert Design Write UpifylasyNo ratings yet
- Collaborative Planning Template W CaptionDocument5 pagesCollaborative Planning Template W Captionapi-297728751No ratings yet
- Philosophy 101Document8 pagesPhilosophy 101scribd5846No ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Complaint For Declaratory and Injunctive Relief FINALDocument40 pagesComplaint For Declaratory and Injunctive Relief FINALGilbert CordovaNo ratings yet
- 1st Grading Exam Perdev With TosDocument4 pages1st Grading Exam Perdev With Toshazel malaga67% (3)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)