You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- EIA For Maize & Wheat Milling Plant DEI PDFDocument110 pagesEIA For Maize & Wheat Milling Plant DEI PDFSasira Fionah100% (2)
- OMT ReviewDocument12 pagesOMT ReviewKyle Derouen100% (6)
- The Ultimate Press Release Swipe File by Pete Williams - SAMPLEDocument20 pagesThe Ultimate Press Release Swipe File by Pete Williams - SAMPLEPete Williams100% (9)
- 2.7 Critical Regions, MonitorsDocument12 pages2.7 Critical Regions, MonitorsavishanaNo ratings yet
- 2.2 Scheduling AlgorithmsDocument19 pages2.2 Scheduling AlgorithmsavishanaNo ratings yet
- Web SystemDocument46 pagesWeb SystemavishanaNo ratings yet
- 2.4 Algorithm Evaluation, Critical Section ProblemDocument15 pages2.4 Algorithm Evaluation, Critical Section ProblemavishanaNo ratings yet
- 2.1 Basics Concepts, Scheduling CriteriaDocument12 pages2.1 Basics Concepts, Scheduling CriteriaavishanaNo ratings yet
- Image Restoration Using Deep Learning: Appearing in Proceedings of Benelearn 2016. 2016 by The Author(s) /owner(s)Document3 pagesImage Restoration Using Deep Learning: Appearing in Proceedings of Benelearn 2016. 2016 by The Author(s) /owner(s)avishanaNo ratings yet
- Web SystemDocument46 pagesWeb SystemavishanaNo ratings yet
- Crowd Computing - Just Estimate 01Document2 pagesCrowd Computing - Just Estimate 01avishanaNo ratings yet
- CloudDocument38 pagesCloudmdskpNo ratings yet
- 1.introduction To CSS PDFDocument5 pages1.introduction To CSS PDFavishanaNo ratings yet
- Web SystemDocument46 pagesWeb SystemavishanaNo ratings yet
- Web ProgrammingDocument30 pagesWeb ProgrammingdaniNo ratings yet
- Executing A Sequence of Instructions in The ConsoleDocument1 pageExecuting A Sequence of Instructions in The ConsoleavishanaNo ratings yet
- Crowd Computing - Just Estimate 02Document3 pagesCrowd Computing - Just Estimate 02avishanaNo ratings yet
- Static ExamplesDocument6 pagesStatic ExamplesavishanaNo ratings yet
- Blooms Taxonomy QuestionsDocument6 pagesBlooms Taxonomy Questionsapi-315608861No ratings yet
- Abstract PGM QDocument1 pageAbstract PGM QavishanaNo ratings yet
- List of 29 States and Capitals of India - 7 Union TerritoriesDocument3 pagesList of 29 States and Capitals of India - 7 Union TerritoriesavishanaNo ratings yet
- Communication Notes Unit 4 To 5 PDFDocument64 pagesCommunication Notes Unit 4 To 5 PDFavishanaNo ratings yet
- Import Import Public Class Public Static Void Throws: //chcountDocument2 pagesImport Import Public Class Public Static Void Throws: //chcountavishanaNo ratings yet
- Communication Notes Unit 4 To 5 PDFDocument64 pagesCommunication Notes Unit 4 To 5 PDFavishanaNo ratings yet
- DownloadDocument19 pagesDownloadRuby SmithNo ratings yet
- C Program To Extract Maximum Numeric Value From A Given String.Document1 pageC Program To Extract Maximum Numeric Value From A Given String.avishanaNo ratings yet
- C Progra With K DifferenceDocument1 pageC Progra With K DifferenceavishanaNo ratings yet
- Dynamic Memory and Data StructuresDocument25 pagesDynamic Memory and Data Structuresabraham_sse1594No ratings yet
- C Programming Course - Worksheet FiveDocument5 pagesC Programming Course - Worksheet FiveavishanaNo ratings yet
- StatisticsDocument1 pageStatisticsavishanaNo ratings yet
- Worksheet One - Variables, Loops and If/ElseDocument15 pagesWorksheet One - Variables, Loops and If/ElseavishanaNo ratings yet
- Worksheet One - Variables, Loops and If/ElseDocument15 pagesWorksheet One - Variables, Loops and If/ElseavishanaNo ratings yet
- Chapter OneDocument14 pagesChapter Oneogunseyeopeyemi2023No ratings yet
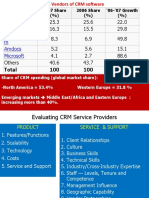
- CRM Vendors, Vendor SelectionDocument7 pagesCRM Vendors, Vendor SelectionsanamkmNo ratings yet
- Quiz II - Company MissionDocument4 pagesQuiz II - Company MissionSuraj SapkotaNo ratings yet
- Prismatic Oil Level GaugeDocument2 pagesPrismatic Oil Level GaugevipulpanchotiyaNo ratings yet
- Project-Based Learning Lesson PlanDocument5 pagesProject-Based Learning Lesson Planapi-324732071100% (1)
- Baranda v. GustiloDocument2 pagesBaranda v. GustiloRiena MaeNo ratings yet
- Tekla - DocumentDocument2,005 pagesTekla - DocumentTranタオNo ratings yet
- Chapter - 1 NetworksDocument61 pagesChapter - 1 NetworksSummiya JangdaNo ratings yet
- 9211 4 PR PE Utility Industry Low Product Range 2017Document226 pages9211 4 PR PE Utility Industry Low Product Range 2017Soporte SyeNo ratings yet
- Content Analysis Research Paper ExampleDocument5 pagesContent Analysis Research Paper Examplefvfzfa5d100% (1)
- Elevator PitchDocument2 pagesElevator PitchChandni SeelochanNo ratings yet
- Guide Spec DX Air Outdoor Condensing Unit 2 2017Document5 pagesGuide Spec DX Air Outdoor Condensing Unit 2 2017JamesNo ratings yet
- Manual DishwashingDocument2 pagesManual Dishwashingkean redNo ratings yet
- Project Procedure IMP 16Document22 pagesProject Procedure IMP 16Jose R C FernandesNo ratings yet
- C31 C31M 03aDocument5 pagesC31 C31M 03aJesus Luis Arce GuillermoNo ratings yet
- 10 Days 7 NightsDocument5 pages10 Days 7 NightsSisca SetiawatyNo ratings yet
- Modern Control Systems Linear Approximation Laplace TransformDocument3 pagesModern Control Systems Linear Approximation Laplace TransformramNo ratings yet
- 312GR Skid Steer Loader PIN 1T0312G G366358 Replacement Parts GuideDocument3 pages312GR Skid Steer Loader PIN 1T0312G G366358 Replacement Parts GuideNelson Andrade VelasquezNo ratings yet
- Capital Expenditure Decision Making ToolsDocument19 pagesCapital Expenditure Decision Making ToolsRoshan PoudelNo ratings yet
- Gmail - DFA Passport Appointment System - Confirmation Notification PDFDocument2 pagesGmail - DFA Passport Appointment System - Confirmation Notification PDFGarcia efrilNo ratings yet
- Motion in A Straight Line: Initial PositionDocument7 pagesMotion in A Straight Line: Initial PositionEngelbert Bicoy AntodNo ratings yet
- Excel calendarDocument28 pagesExcel calendarThanh LêNo ratings yet
- Guided Overview of Impression MaterialsDocument212 pagesGuided Overview of Impression MaterialsSai Kumar100% (1)
- CS 11 - Exam 1 - Answer Key PDFDocument5 pagesCS 11 - Exam 1 - Answer Key PDFeduardo edradaNo ratings yet
- Esp Module 4Document34 pagesEsp Module 4ELLEN B.SINAHONNo ratings yet
- Token Economics BookDocument81 pagesToken Economics BookNara E Aí100% (3)
- 200 NsDocument63 pages200 NsSam SamiNo ratings yet