You might also like
- MathWorks Interview ProcessDocument2 pagesMathWorks Interview ProcessPawan Singh100% (1)
- Neil Strauss - The Annihilation Method - Style's Archives - Volume 1 - The Origin of Style - How To Transform From Chump To Champ in No TimeDocument132 pagesNeil Strauss - The Annihilation Method - Style's Archives - Volume 1 - The Origin of Style - How To Transform From Chump To Champ in No TimeDaniel Nii Armah Tetteh100% (2)
- Statistical Inference: Hypothesis Testing for Two PopulationsDocument44 pagesStatistical Inference: Hypothesis Testing for Two PopulationsPartha Pratim TalukdarNo ratings yet
- Chapter 8 of An Elementary Statistics ClassDocument10 pagesChapter 8 of An Elementary Statistics Classricardo2aguilar2castNo ratings yet
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Asme B18.24-2020Document190 pagesAsme B18.24-2020윤규섭0% (1)
- V200 User ManualDocument171 pagesV200 User ManualuriahskyNo ratings yet
- FS Jack: Information GuideDocument12 pagesFS Jack: Information GuideGemma gladeNo ratings yet
- Chapter 10Document35 pagesChapter 10Venkata KalyanNo ratings yet
- CH 09Document10 pagesCH 09aqillahNo ratings yet
- Hypothesis TestDocument15 pagesHypothesis TestS.S.Rules83% (6)
- Chapter 7 Hypotheses TestingDocument15 pagesChapter 7 Hypotheses TestingAbenezer YohannesNo ratings yet
- Z TestDocument21 pagesZ TestSaha SuprioNo ratings yet
- Overview of Statistical Hypothesis Testing: The - TestDocument21 pagesOverview of Statistical Hypothesis Testing: The - TestPuNeet ShaRmaNo ratings yet
- LECTURE NOTES ON PARAMETRIC & NON-PARAMETRIC TESTSDocument19 pagesLECTURE NOTES ON PARAMETRIC & NON-PARAMETRIC TESTSDiwakar RajputNo ratings yet
- Hypothesis Testing For One Population Parameter - SamplesDocument68 pagesHypothesis Testing For One Population Parameter - SamplesMary Grace Caguioa AgasNo ratings yet
- What Is Hypothesis TestingDocument32 pagesWhat Is Hypothesis TestingNasir Mehmood AryaniNo ratings yet
- 3 - Test of Hypothesis (Part - 1) PDFDocument45 pages3 - Test of Hypothesis (Part - 1) PDFhijab100% (1)
- Hypothesis TestingDocument37 pagesHypothesis TestingPayal SardaNo ratings yet
- 15 Testing of HypothesisDocument54 pages15 Testing of HypothesisNikesh MunankarmiNo ratings yet
- Hypothesis LectureDocument7 pagesHypothesis Lectureikvinder randhawaNo ratings yet
- Statistics Can Be Broadly Classified Into Two Categories Namely (I) Descriptive Statistics and (II) Inferential StatisticsDocument59 pagesStatistics Can Be Broadly Classified Into Two Categories Namely (I) Descriptive Statistics and (II) Inferential Statisticstradag0% (1)
- MTH 4th Grading NotesDocument19 pagesMTH 4th Grading NotesMichelle AnnNo ratings yet
- PARAMETRIC TESTS: A GUIDE TO STATISTICAL INFERENCEDocument19 pagesPARAMETRIC TESTS: A GUIDE TO STATISTICAL INFERENCEayushNo ratings yet
- CHAPTER THREE, Hypothesis TestingDocument17 pagesCHAPTER THREE, Hypothesis TestingGirma erenaNo ratings yet
- Statistics Tutorial: Hypothesis Tests: Null Hypothesis. The Null Hypothesis, Denoted by HDocument66 pagesStatistics Tutorial: Hypothesis Tests: Null Hypothesis. The Null Hypothesis, Denoted by Htafi66No ratings yet
- 04 Statistical Inference v0 1 09062022 090226pmDocument42 pages04 Statistical Inference v0 1 09062022 090226pmSaif ali KhanNo ratings yet
- Hypothesis TestsDocument3 pagesHypothesis TestsXenon FranciumNo ratings yet
- PREETIDocument18 pagesPREETIGovind RohillaNo ratings yet
- Introduction To Hypothesis Testing and EstimationDocument28 pagesIntroduction To Hypothesis Testing and EstimationFatima KausarNo ratings yet
- Hypothesis Testing On A Single Population MeanDocument11 pagesHypothesis Testing On A Single Population MeanEiyra NadiaNo ratings yet
- Week 1 To 3 Lectures Q ADocument16 pagesWeek 1 To 3 Lectures Q AHuma RehmanNo ratings yet
- MATH 403 EDA Chapter 8Document19 pagesMATH 403 EDA Chapter 8Marco YvanNo ratings yet
- Hypothesis TestingDocument21 pagesHypothesis TestingMisshtaCNo ratings yet
- What Is Hypothesis Testing?: TestsDocument16 pagesWhat Is Hypothesis Testing?: TestsSeifu BekeleNo ratings yet
- Hypothesis Testing 1Document118 pagesHypothesis Testing 1sheelajeevakumar100% (1)
- Testing HypothesisDocument9 pagesTesting HypothesisUsama IqbalNo ratings yet
- Assignment No. 02 Introduction To Educational Statistics (8614)Document19 pagesAssignment No. 02 Introduction To Educational Statistics (8614)somiNo ratings yet
- Introduction to Inferential Statistics (1)Document15 pagesIntroduction to Inferential Statistics (1)Harshita ChauhanNo ratings yet
- Hypothesis Testing GuideDocument48 pagesHypothesis Testing GuideanonNo ratings yet
- Hypothesis Testing GuideDocument23 pagesHypothesis Testing GuideMahek GoyalNo ratings yet
- Statistical Inference GuideDocument36 pagesStatistical Inference GuideSherlcok HolmesNo ratings yet
- Statistics and ProbabilityDocument6 pagesStatistics and ProbabilityRonaldNo ratings yet
- Lesson 3 Hypothesis TestingDocument23 pagesLesson 3 Hypothesis TestingAmar Nath BabarNo ratings yet
- Ch-3 HYPOTHESIS TESTINGDocument24 pagesCh-3 HYPOTHESIS TESTINGVibe GagNo ratings yet
- MATH 110 Hypothesis Testing GuideDocument74 pagesMATH 110 Hypothesis Testing GuidePao Castillon100% (1)
- Testing of Hypothesis: Business Mathematics and Statistics MBA (FT) IDocument18 pagesTesting of Hypothesis: Business Mathematics and Statistics MBA (FT) IAashish Kumar PrajapatiNo ratings yet
- Chapter 8Document5 pagesChapter 8Li ChNo ratings yet
- PH D Agric EconomicsSeminarinAdvancedResearchMethodsHypothesistestingDocument24 pagesPH D Agric EconomicsSeminarinAdvancedResearchMethodsHypothesistestingJummy Dr'chebatickNo ratings yet
- Testing Hypothesis Statistical MethodsDocument13 pagesTesting Hypothesis Statistical MethodsPUBG HackerNo ratings yet
- Hypothesis Testing Basic Terminology:: PopulationDocument19 pagesHypothesis Testing Basic Terminology:: PopulationRahat KhanNo ratings yet
- Hypothesis Testing Procedure PT 1Document32 pagesHypothesis Testing Procedure PT 1archy mogusNo ratings yet
- B.Tech, Cse-B, V Sem, Iiird Year Cs-503: Data Analytics Introduction To Inferential StatisticsDocument15 pagesB.Tech, Cse-B, V Sem, Iiird Year Cs-503: Data Analytics Introduction To Inferential StatisticsHarry PotterNo ratings yet
- Hypothesis Testing Part IDocument8 pagesHypothesis Testing Part IAbi AbeNo ratings yet
- Sampling Theory and Hypothesis Testing GuideDocument69 pagesSampling Theory and Hypothesis Testing GuideGaurav SonkarNo ratings yet
- Inferential StatisticsDocument28 pagesInferential StatisticsZLAIQANo ratings yet
- Unit IVDocument132 pagesUnit IVShay ShayNo ratings yet
- Biostat Hypothesis TestingDocument31 pagesBiostat Hypothesis Testingteklay100% (4)
- 90156hypothesis TestingDocument34 pages90156hypothesis TestingAvani KukrejaNo ratings yet
- Machine Learning With R - DAY1Document43 pagesMachine Learning With R - DAY1Inphiknight Inc.No ratings yet
- StatDocument70 pagesStatcj_anero67% (3)
- Unit 09Document25 pagesUnit 09sastrylanka_1980100% (1)
- Hypothesis TestingDocument58 pagesHypothesis TestingkartikharishNo ratings yet
- Combine PDFDocument52 pagesCombine PDFcojeneNo ratings yet
- Premili DefinitionsDocument3 pagesPremili DefinitionsJayakumar ChenniahNo ratings yet
- KKKKKR, autho-WPS OfficeDocument1 pageKKKKKR, autho-WPS OfficeANCHAL SINGHNo ratings yet
- KKKDocument2 pagesKKKANCHAL SINGHNo ratings yet
- KKKDocument2 pagesKKKANCHAL SINGHNo ratings yet
- QuestionsDocument2 pagesQuestionsANCHAL SINGHNo ratings yet
- HDocument2 pagesHANCHAL SINGHNo ratings yet
- Only and where-WPS OfficeDocument2 pagesOnly and where-WPS OfficeANCHAL SINGHNo ratings yet
- Movable propert-WPS OfficeDocument1 pageMovable propert-WPS OfficeANCHAL SINGHNo ratings yet
- 1861, Great Bri-WPS OfficeDocument1 page1861, Great Bri-WPS OfficeANCHAL SINGHNo ratings yet
- Ibps Specialist Officer Cwe Ibps Specialist Officer CweDocument12 pagesIbps Specialist Officer Cwe Ibps Specialist Officer CweGaurav SharmaNo ratings yet
- DvdeDocument1 pageDvdeANCHAL SINGHNo ratings yet
- Google Began in-WPS OfficeDocument1 pageGoogle Began in-WPS OfficeANCHAL SINGHNo ratings yet
- Mobile Phone, C-WPS OfficeDocument1 pageMobile Phone, C-WPS OfficeANCHAL SINGHNo ratings yet
- Mobile Phone, C-WPS OfficeDocument1 pageMobile Phone, C-WPS OfficeANCHAL SINGHNo ratings yet
- HDGGDocument1 pageHDGGMOHAMMAD KAIF AHMEDNo ratings yet
- English 1Document1 pageEnglish 1MIGUEL CASTRO FUENTESNo ratings yet
- Mobile Phone, C-WPS OfficeDocument1 pageMobile Phone, C-WPS OfficeANCHAL SINGHNo ratings yet
- A1666631993 - 19476 - 2 - 2020 - MKT515 Ca 1Document2 pagesA1666631993 - 19476 - 2 - 2020 - MKT515 Ca 1ANCHAL SINGHNo ratings yet
- The RedDocument1 pageThe RedANCHAL SINGHNo ratings yet
- Operations Research Multiple Choice Questions: B. ScientificDocument25 pagesOperations Research Multiple Choice Questions: B. ScientificBilal AhmedNo ratings yet
- India PostDocument1 pageIndia PostANCHAL SINGHNo ratings yet
- CDDocument1 pageCDANCHAL SINGHNo ratings yet
- IV Sem - Operations Research1Document22 pagesIV Sem - Operations Research1MorerpNo ratings yet
- A Project Profile On: HAND SANITIZER (Alcohol Based)Document10 pagesA Project Profile On: HAND SANITIZER (Alcohol Based)Himansu Sekhar SahuNo ratings yet
- MCQ Services Marketing Unit 2Document6 pagesMCQ Services Marketing Unit 2Akash SonekarNo ratings yet
- Q2e12 Fin545 Ca3Document2 pagesQ2e12 Fin545 Ca3kajal malhotraNo ratings yet
- Week 3 Assignment SolutionDocument3 pagesWeek 3 Assignment SolutionSubb RakNo ratings yet
- Lovely Professional University Academic Task No. 2Document4 pagesLovely Professional University Academic Task No. 2ANCHAL SINGHNo ratings yet
- Course Code OPR621 Name Quiz/Test No II Roll No. Section Max. Marks 30 Marks Date Max. Time 50 Minutes 1. (10 Marks)Document1 pageCourse Code OPR621 Name Quiz/Test No II Roll No. Section Max. Marks 30 Marks Date Max. Time 50 Minutes 1. (10 Marks)ANCHAL SINGHNo ratings yet
- A1957478784 - 19476 - 11 - 2020 - New Microsoft Word DocumentDocument1 pageA1957478784 - 19476 - 11 - 2020 - New Microsoft Word DocumentANCHAL SINGHNo ratings yet
- Fault ModelingDocument21 pagesFault ModelingRamarao ChNo ratings yet
- b1 Preliminary For Schools Classroom Posters and Activities PDFDocument13 pagesb1 Preliminary For Schools Classroom Posters and Activities PDFNat ShattNo ratings yet
- Main Body Recruitment Process of Human Resource Division in Brac BankDocument55 pagesMain Body Recruitment Process of Human Resource Division in Brac BankAsfia PrantyNo ratings yet
- From Birth Till Palatoplasty Prosthetic.20Document5 pagesFrom Birth Till Palatoplasty Prosthetic.20Maria FernandaNo ratings yet
- Large Generators WEBDocument16 pagesLarge Generators WEBMaycon MaranNo ratings yet
- Literature Review On Waste Management in NigeriaDocument9 pagesLiterature Review On Waste Management in NigeriajzneaqwgfNo ratings yet
- Microbiology - Prokaryotic Cell Biology: Bacterial Surface Structures Bacterial Cell Wall StructureDocument5 pagesMicrobiology - Prokaryotic Cell Biology: Bacterial Surface Structures Bacterial Cell Wall StructureDani AnyikaNo ratings yet
- Labcir - Marwa - FinalDocument119 pagesLabcir - Marwa - FinalMashavia AhmadNo ratings yet
- Burkert General Catalogue Rev2Document44 pagesBurkert General Catalogue Rev2cuongNo ratings yet
- Uconnect User GuideDocument113 pagesUconnect User GuidetamilarasansrtNo ratings yet
- 22m Fast Patrol Craft Features & SpecsDocument1 page22m Fast Patrol Craft Features & SpecsNico BossiNo ratings yet
- Collective BargainingDocument18 pagesCollective Bargainingchandni kundel100% (3)
- 178 - 7 - Fun For Flyers. Progress Tests - 2017, 4th - 91p.pdf Foods NatureDocument1 page178 - 7 - Fun For Flyers. Progress Tests - 2017, 4th - 91p.pdf Foods NatureYu KoNo ratings yet
- Mercedes Vario 1996 2003 PDF Service ManualDocument22 pagesMercedes Vario 1996 2003 PDF Service Manualveronicamurphy070288aqwNo ratings yet
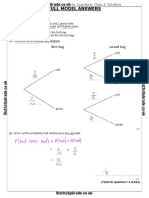
- Probability Tree Diagrams Solutions Mathsupgrade Co UkDocument10 pagesProbability Tree Diagrams Solutions Mathsupgrade Co UknatsNo ratings yet
- Williamstown Cannabis Cultivation PlanDocument48 pagesWilliamstown Cannabis Cultivation PlanOltion JaupajNo ratings yet
- 32 Productivity Increase in A PeirceSmith Convert 153013Document14 pages32 Productivity Increase in A PeirceSmith Convert 153013amirlpNo ratings yet
- WEEK 7 ICPS - and - ICSSDocument31 pagesWEEK 7 ICPS - and - ICSScikguhafidzuddinNo ratings yet
- Educ 580 - Edpuzzle PD HandoutDocument3 pagesEduc 580 - Edpuzzle PD Handoutapi-548868233No ratings yet
- Finite Element Analysis (FEA) Software MarketDocument3 pagesFinite Element Analysis (FEA) Software Marketsurendra choudharyNo ratings yet
- ID Strategi Integrated Marketing Communication Imc Untuk Meningkatkan Loyalitas AngDocument17 pagesID Strategi Integrated Marketing Communication Imc Untuk Meningkatkan Loyalitas AngAiman AzhariNo ratings yet
- Food, Family, and FriendshipsDocument256 pagesFood, Family, and FriendshipsBianca PradoNo ratings yet
- Effects of UrbanizationDocument17 pagesEffects of UrbanizationAriel EstigoyNo ratings yet
- Breaugh Starke PDFDocument30 pagesBreaugh Starke PDFRichard YeongNo ratings yet
- Dear Boy (Acordes para Cancion)Document4 pagesDear Boy (Acordes para Cancion)Rodolfo GuglielmoNo ratings yet