You might also like
- Solucionario Games and Information RasmusenDocument106 pagesSolucionario Games and Information RasmusenByron Bravo GNo ratings yet
- Game-Playing MiniMax Search Cut-off HeuristicsDocument28 pagesGame-Playing MiniMax Search Cut-off HeuristicsIlias YahiaNo ratings yet
- Assignment - 6 Game TheoryDocument2 pagesAssignment - 6 Game TheoryDawit Haile33% (3)
- Games Strategies and Decision Making 2nd Edition Harrington Solutions Manual DownloadDocument18 pagesGames Strategies and Decision Making 2nd Edition Harrington Solutions Manual DownloadAmyBrightdqjm100% (31)
- Game Playing in Artificial IntelligenceDocument12 pagesGame Playing in Artificial IntelligencedevitoshNo ratings yet
- Decision Theory QuizDocument3 pagesDecision Theory QuizAuroraNo ratings yet
- Modern Practice in the King's Indian DefenseDocument260 pagesModern Practice in the King's Indian DefenseManu EmmanuelNo ratings yet
- UNIT-II-Adversarial SearchDocument28 pagesUNIT-II-Adversarial Searchthdghj8No ratings yet
- Unit 3Document25 pagesUnit 3Saurav SemaltiNo ratings yet
- Adversarial Search 2020Document34 pagesAdversarial Search 2020Rafiq MuzakkiNo ratings yet
- Adversial SearchDocument20 pagesAdversial SearchAnkit KumarNo ratings yet
- Adversial SearchDocument21 pagesAdversial Searchk.s.v.gameplayNo ratings yet
- Adversarial SearchDocument13 pagesAdversarial SearchUsman ManiNo ratings yet
- 0 Adversial Search Min Max ALpha BetaDocument64 pages0 Adversial Search Min Max ALpha Betafunnyclups413No ratings yet
- Minimax AlgorithmDocument12 pagesMinimax AlgorithmPavitra PatiNo ratings yet
- 4.3 Adversarial SearchDocument12 pages4.3 Adversarial SearchSuvam vlogsNo ratings yet
- Here is the game tree marked with pruned paths:MAXMIN MAXXXMAXMINDocument23 pagesHere is the game tree marked with pruned paths:MAXMIN MAXXXMAXMINDagmawiNo ratings yet
- AI 2ndunitDocument25 pagesAI 2ndunitPriyansh GuptaNo ratings yet
- Game PlayingDocument53 pagesGame PlayingFairooz TorosheNo ratings yet
- Lesson 3 GamingDocument86 pagesLesson 3 Gamingthomas mumoNo ratings yet
- Games, The Mini-Max AlgorithmDocument160 pagesGames, The Mini-Max AlgorithmChiku PatilNo ratings yet
- AI Notes Part-2Document14 pagesAI Notes Part-2Divyanshu PatwalNo ratings yet
- 18cs753 Ai Module 4Document44 pages18cs753 Ai Module 4Rachana KumariNo ratings yet
- CS6659 AI UNIT 2 NotesDocument51 pagesCS6659 AI UNIT 2 NotesprofBalamurugan100% (4)
- 18cs753 Ai Module 4Document44 pages18cs753 Ai Module 4satarekarpremNo ratings yet
- Adversarial Search Mini-MaxDocument8 pagesAdversarial Search Mini-MaxVariable 14No ratings yet
- 18CS753 Ai Module 4Document43 pages18CS753 Ai Module 4Arham SyedNo ratings yet
- Lecture 09 10+Game+Playing+++MinMax-AlphaBetaDocument54 pagesLecture 09 10+Game+Playing+++MinMax-AlphaBetaM MNo ratings yet
- Adversarial Search in AIDocument21 pagesAdversarial Search in AIM. Talha NadeemNo ratings yet
- Ai Exp 07Document7 pagesAi Exp 07Abhishek TekalkarNo ratings yet
- 21CSC206T Unit3Document138 pages21CSC206T Unit3Aryan AgarwalNo ratings yet
- Games AI Search TechniquesDocument16 pagesGames AI Search TechniquesOm TripathiNo ratings yet
- Fundamentals of Artificial Intelligence: Adversarial Search Game PlayingDocument34 pagesFundamentals of Artificial Intelligence: Adversarial Search Game PlayingAriel AsunsionNo ratings yet
- AI Minmax AlgoDocument13 pagesAI Minmax AlgoNikhil AgrawalNo ratings yet
- Materi AI-07Document48 pagesMateri AI-07niferli julienNo ratings yet
- Ai-Unit 3Document67 pagesAi-Unit 3maharajan241jfNo ratings yet
- Exp No-8-219Document6 pagesExp No-8-219Mayur PawadeNo ratings yet
- Module 3 Games Optimal Decisions in Games Minimax AlgorithmDocument18 pagesModule 3 Games Optimal Decisions in Games Minimax AlgorithmVariable 14No ratings yet
- Documentation of TIK TAK TOE AI GameDocument21 pagesDocumentation of TIK TAK TOE AI GameFaisal ShehzadNo ratings yet
- AI-Lecture 6 (Adversarial Search)Document68 pagesAI-Lecture 6 (Adversarial Search)Braga Gladys MaeNo ratings yet
- Artificial Intelligence Adversarial Search TechniquesDocument62 pagesArtificial Intelligence Adversarial Search TechniquesKhawir MahmoodNo ratings yet
- Module 4 Using Heuristic in Game Min-Max-ProcedureDocument11 pagesModule 4 Using Heuristic in Game Min-Max-ProcedureDr Abdul Gafur MNo ratings yet
- Unit-2 Adversarial SearchDocument13 pagesUnit-2 Adversarial SearchIshaNo ratings yet
- Unit 2c Game Playing (Compatibility Mode)Document36 pagesUnit 2c Game Playing (Compatibility Mode)Madhav ChaudharyNo ratings yet
- Ai Unit 3Document33 pagesAi Unit 3Alima NasaNo ratings yet
- Min max example-for studentsDocument5 pagesMin max example-for studentsahmed.nistas2001No ratings yet
- UT_1_T_5 GAME PLAYINGDocument57 pagesUT_1_T_5 GAME PLAYINGDhivya Bharathi pNo ratings yet
- Minimax Algorithm & Alpha-Beta PruningDocument35 pagesMinimax Algorithm & Alpha-Beta PruninganyangupreciousNo ratings yet
- 3 GamePlaying - MinimaxDocument75 pages3 GamePlaying - Minimax87Saaraansh MishraITNo ratings yet
- Artificial Intelligence - Mini-Max AlgorithmDocument5 pagesArtificial Intelligence - Mini-Max AlgorithmAfaque AlamNo ratings yet
- Game PlayingDocument8 pagesGame PlayingStephen SalNo ratings yet
- 484 7hgfDocument20 pages484 7hgfBonviNo ratings yet
- Chapter 5 - Unit 2: Adversarial SearchDocument37 pagesChapter 5 - Unit 2: Adversarial Search8mk5n2q8ptNo ratings yet
- Institute of Southern Punjab Multan: Syed Zohair Quain Haider Lecturer ISP MultanDocument41 pagesInstitute of Southern Punjab Multan: Syed Zohair Quain Haider Lecturer ISP MultanCh MaaanNo ratings yet
- Adversial SearchDocument39 pagesAdversial SearchIM AM INEVITABLENo ratings yet
- Week 3 C5 Adversarial Search and Games (Belano & Ong Chua)Document57 pagesWeek 3 C5 Adversarial Search and Games (Belano & Ong Chua)vronkalinkishNo ratings yet
- Adversarial SearchDocument42 pagesAdversarial Searcharyatel26No ratings yet
- ADVERS SRCHES - Min Max - StudentsDocument34 pagesADVERS SRCHES - Min Max - StudentsGUNEET SURANo ratings yet
- Game Playing in Artificial IntelligenceDocument17 pagesGame Playing in Artificial IntelligencePraveen KumarNo ratings yet
- Game PlayingDocument48 pagesGame PlayingDhanraj KumarNo ratings yet
- Adversarial Search (Minimax, Alfa-Beta Algorithm)Document15 pagesAdversarial Search (Minimax, Alfa-Beta Algorithm)Sawaira KazmiNo ratings yet
- 5.module3 ADVERSARIAL SEARCH 4Document23 pages5.module3 ADVERSARIAL SEARCH 4justadityabistNo ratings yet
- Artificial Intelligence - Adversarial SearchDocument4 pagesArtificial Intelligence - Adversarial SearchAfaque AlamNo ratings yet
- Game Playing: Adversarial SearchDocument66 pagesGame Playing: Adversarial SearchTalha AnjumNo ratings yet
- Sri Krishna Arts and Science Computer Technology: Course Coordinator Dr. V. S. Anita Sofia Prof. & HeadDocument70 pagesSri Krishna Arts and Science Computer Technology: Course Coordinator Dr. V. S. Anita Sofia Prof. & HeadAnita Sofia VNo ratings yet
- Sri Krishna Arts and Science Computer Technology: Course Coordinator Dr. V. S. Anita Sofia Prof. & HeadDocument20 pagesSri Krishna Arts and Science Computer Technology: Course Coordinator Dr. V. S. Anita Sofia Prof. & HeadAnita Sofia VNo ratings yet
- Sri Krishna Arts and Science Computer Technology: Course Coordinator Dr. V. S. Anita Sofia Prof. & HeadDocument20 pagesSri Krishna Arts and Science Computer Technology: Course Coordinator Dr. V. S. Anita Sofia Prof. & HeadAnita Sofia VNo ratings yet
- Sri Krishna Arts and Science Computer Technology: Course Coordinator Dr. V. S. Anita Sofia Prof. & HeadDocument78 pagesSri Krishna Arts and Science Computer Technology: Course Coordinator Dr. V. S. Anita Sofia Prof. & HeadAnita Sofia VNo ratings yet
- Ethernet Technology: Ethernet), Supports Data Transfer Rates of 100 MbpsDocument27 pagesEthernet Technology: Ethernet), Supports Data Transfer Rates of 100 MbpsAnita Sofia VNo ratings yet
- Reliable Stream Transport Service (TCP)Document8 pagesReliable Stream Transport Service (TCP)Anita Sofia VNo ratings yet
- Internetworking With Tcp/Ip Principles, Protocols, and ArchitectureDocument26 pagesInternetworking With Tcp/Ip Principles, Protocols, and ArchitectureAnita Sofia VNo ratings yet
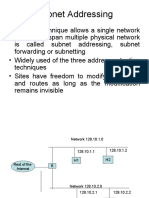
- Subnet AddressingDocument27 pagesSubnet AddressingAnita Sofia VNo ratings yet
- Ethernet Technology: Ethernet), Supports Data Transfer Rates of 100 MbpsDocument27 pagesEthernet Technology: Ethernet), Supports Data Transfer Rates of 100 MbpsAnita Sofia VNo ratings yet
- Asynchronous Transfer ModeDocument14 pagesAsynchronous Transfer ModeAnita Sofia VNo ratings yet
- Decision Theory: Optimal Strategies Under Risk and UncertaintyDocument11 pagesDecision Theory: Optimal Strategies Under Risk and UncertaintyGurleen BajwaNo ratings yet
- Christoph Pfeiffer - Game Theory - Successful Negotiation in Purchasing - Requirements, Incentives and Award-Springer (2023)Document139 pagesChristoph Pfeiffer - Game Theory - Successful Negotiation in Purchasing - Requirements, Incentives and Award-Springer (2023)georges boustanyNo ratings yet
- Nur Hidayah Analisis Swot 4 Jan 2017Document48 pagesNur Hidayah Analisis Swot 4 Jan 2017atikaNo ratings yet
- Computational Game TheoryDocument6 pagesComputational Game TheoryNishiya VijayanNo ratings yet
- A Game Theorist Is Walking Down The Street in His Neighborhood and Finds 20 Just As He Picks ItDocument1 pageA Game Theorist Is Walking Down The Street in His Neighborhood and Finds 20 Just As He Picks ItCharlotteNo ratings yet
- The Role of Leadership in Strategy Formulation and ImplementationDocument7 pagesThe Role of Leadership in Strategy Formulation and ImplementationHtetThinzarNo ratings yet
- Mixed Strategy Nash Equilibrium in Matching PenniesDocument106 pagesMixed Strategy Nash Equilibrium in Matching PenniesCarlos TiradoNo ratings yet
- Chapter Twenty-Eight: Game TheoryDocument81 pagesChapter Twenty-Eight: Game TheoryDejene TumisoNo ratings yet
- B.tech CS S8 Artificial Intelligence Notes Module 3Document49 pagesB.tech CS S8 Artificial Intelligence Notes Module 3Jisha ShajiNo ratings yet
- Part II. Market Power: Chapter 4. Dynamic Aspects of Imperfect CompetitionDocument9 pagesPart II. Market Power: Chapter 4. Dynamic Aspects of Imperfect Competitionmoha dahmaniNo ratings yet
- Microeconomics Qualifying ExaminationDocument3 pagesMicroeconomics Qualifying ExaminationMin Jae ParkNo ratings yet
- Econ 620 SyllabusDocument3 pagesEcon 620 SyllabusTOM ZACHARIASNo ratings yet
- Microeconomics 2nd Edition Karlan Solutions ManualDocument16 pagesMicroeconomics 2nd Edition Karlan Solutions Manualrobertreynoldsosgqczbmdf100% (26)
- Game Theory: Slides by Pamela L. Hall Western Washington UniversityDocument50 pagesGame Theory: Slides by Pamela L. Hall Western Washington Universityananya_aniNo ratings yet
- Game TheoryDocument34 pagesGame TheoryAnkit GuptaNo ratings yet
- Solution 3 RasmussenDocument12 pagesSolution 3 Rasmussenalvaro roberioNo ratings yet
- Artificial Intelligence: Adversarial Search OptimizationDocument58 pagesArtificial Intelligence: Adversarial Search OptimizationAkshita PatelNo ratings yet
- Competitive Strategies Chapter OutlineDocument19 pagesCompetitive Strategies Chapter OutlineJatin PandeyNo ratings yet
- Oligopoly HandoutDocument36 pagesOligopoly HandoutSarat ChandraNo ratings yet
- Game Theory in Stag HuntDocument12 pagesGame Theory in Stag HuntTanmay NayakNo ratings yet
- Strictly Dominant Strategy and Nash Equilibrium in Game Theory SituationsDocument4 pagesStrictly Dominant Strategy and Nash Equilibrium in Game Theory SituationsRayan RahmanNo ratings yet
- Comparing Porter's Five Forces Model and the Resource-Based ViewDocument12 pagesComparing Porter's Five Forces Model and the Resource-Based ViewBoNo ratings yet
- Game TheoryDocument29 pagesGame TheoryZhenyu LaiNo ratings yet
- 1quiz - Game TheoryDocument4 pages1quiz - Game TheoryRaunak Agarwal0% (3)
- Ps3 SolutionDocument4 pagesPs3 SolutionBruno OliveiraNo ratings yet