You might also like
- Hiding From The InternetDocument34 pagesHiding From The Internetgianluca136No ratings yet
- Class XI Practical Assignment MysqlDocument6 pagesClass XI Practical Assignment Mysqlharsh0% (2)
- MS SQLDocument95 pagesMS SQLmanu424No ratings yet
- Business Taxation: - Back To BasicDocument56 pagesBusiness Taxation: - Back To BasicWearIt Co.No ratings yet
- Data Structures & Algorithms Interview Questions You'll Most Likely Be AskedFrom EverandData Structures & Algorithms Interview Questions You'll Most Likely Be AskedRating: 1 out of 5 stars1/5 (1)
- CPA Review - VAT Quizzer - 2019Document11 pagesCPA Review - VAT Quizzer - 2019Kenneth Bryan Tegerero Tegio50% (2)
- Business AnalyticsDocument142 pagesBusiness AnalyticsG Madhuri100% (2)
- Multiple Choice - Problems Part 1: A. Percentage TaxDocument8 pagesMultiple Choice - Problems Part 1: A. Percentage TaxWearIt Co.No ratings yet
- SQL SERVER - 2008 - Interview Questions and Answers - : PinaldaveDocument26 pagesSQL SERVER - 2008 - Interview Questions and Answers - : PinaldaveAvinash Chougule100% (1)
- Isilon Administration and Management Course - Student GuideDocument529 pagesIsilon Administration and Management Course - Student GuideAmit KumarNo ratings yet
- 0603 Implementing SAP HANA On SLT With A Non SAP Source SystemDocument45 pages0603 Implementing SAP HANA On SLT With A Non SAP Source SystemfrintorappaiNo ratings yet
- Taxation - VAT - Quizzer - 2016NDocument8 pagesTaxation - VAT - Quizzer - 2016NKenneth Bryan Tegerero TegioNo ratings yet
- Brief History of The Relational ModelDocument5 pagesBrief History of The Relational ModelSaleem KhanNo ratings yet
- CS502 DBMS Unit-2 - 1692116698Document12 pagesCS502 DBMS Unit-2 - 1692116698Bhavika ShrivastavaNo ratings yet
- Relational DatabaseDocument29 pagesRelational DatabaseRabin KarkiNo ratings yet
- RDBMSDocument61 pagesRDBMSteam 8No ratings yet
- UntitledDocument25 pagesUntitledgouvany tamerNo ratings yet
- MS SQLDocument95 pagesMS SQLsakunthalapcsNo ratings yet
- 01 Database ModelingDocument17 pages01 Database ModelingMay Ann Laneta NoricoNo ratings yet
- Metadata Refers To Data About DataDocument24 pagesMetadata Refers To Data About DataAndreea VonicaNo ratings yet
- DBMS Notes 2Document7 pagesDBMS Notes 2swatiNo ratings yet
- Chapter 5 Relational Data ModelDocument20 pagesChapter 5 Relational Data ModelHildana TamratNo ratings yet
- Dbms Vimp MicroDocument20 pagesDbms Vimp Micromorerishi469No ratings yet
- Summary-Booklet - Jenna TutorialsDocument15 pagesSummary-Booklet - Jenna TutorialsjdsterNo ratings yet
- Lesson2-1Document9 pagesLesson2-1Aimee Joy UgayanNo ratings yet
- Relational Data Model: ThreeDocument37 pagesRelational Data Model: ThreeStar69 Stay schemin2No ratings yet
- Functional Dependency and NormalizationDocument10 pagesFunctional Dependency and NormalizationDo Van TuNo ratings yet
- Database ConceptsDocument3 pagesDatabase ConceptsPRAVEENA R.PNo ratings yet
- Logical Database Design From ERDDocument20 pagesLogical Database Design From ERDHala GharibNo ratings yet
- Xii Cs Unit III Database MGMT 2020 21Document36 pagesXii Cs Unit III Database MGMT 2020 21SamhithNo ratings yet
- DBMSDocument72 pagesDBMSrocketgamer054No ratings yet
- Unit 2 - Database Management Systems - WWW - Rgpvnotes.inDocument22 pagesUnit 2 - Database Management Systems - WWW - Rgpvnotes.inZyter MathuNo ratings yet
- HW5Document7 pagesHW5Rahul Patil100% (1)
- Toaz - Info Hw5 PRDocument7 pagesToaz - Info Hw5 PRJamal Al-jaziNo ratings yet
- Unit 1: How Many Levels Are There in Architecture of DBMSDocument11 pagesUnit 1: How Many Levels Are There in Architecture of DBMSSonu KumarNo ratings yet
- XII CS Unit III DATABASE MGMT 2020 21Document36 pagesXII CS Unit III DATABASE MGMT 2020 21chiarameliaNo ratings yet
- Chapter 3 Relational Data Model and NormalizationDocument41 pagesChapter 3 Relational Data Model and NormalizationAhmad Al Haj IbrahimNo ratings yet
- Lec 09 22102023 041515pmDocument67 pagesLec 09 22102023 041515pmMuhammad BilalNo ratings yet
- Unit-3 DBMSDocument63 pagesUnit-3 DBMSHimanshu GoelNo ratings yet
- RDBMSD 1 42Document42 pagesRDBMSD 1 42net chuckyNo ratings yet
- Lab Book: F. Y. B. B. A. (C.A.) Semester IDocument47 pagesLab Book: F. Y. B. B. A. (C.A.) Semester I3427 Sohana JoglekarNo ratings yet
- 5.2 Structured DataDocument29 pages5.2 Structured DataBLADE LEMONNo ratings yet
- UNIT4Document17 pagesUNIT4Ayush NighotNo ratings yet
- Levels of Database AbstractionDocument32 pagesLevels of Database AbstractionAbhishek KumarNo ratings yet
- Keys in Data Base Management SystemDocument14 pagesKeys in Data Base Management SystemRaghav KhemkaNo ratings yet
- Chapter-8-DBMS CoceptsDocument11 pagesChapter-8-DBMS CoceptsCheryl ChaudhariNo ratings yet
- Logical Database ReportDocument52 pagesLogical Database ReportGlenn AsuncionNo ratings yet
- Unit 2Document21 pagesUnit 2Nanaji UppeNo ratings yet
- Database Management - Session 5Document39 pagesDatabase Management - Session 5Jinen MirjeNo ratings yet
- Database Management SystemDocument23 pagesDatabase Management SystemSheyona Ann ShajiNo ratings yet
- Data Redundancy Risk To Data Integrity Data Isolation Difficult Access To Data Unsatisfactory Security Measure Concurrent AccessDocument80 pagesData Redundancy Risk To Data Integrity Data Isolation Difficult Access To Data Unsatisfactory Security Measure Concurrent Accessjack430No ratings yet
- DatabaseDocument5 pagesDatabasegooda6201No ratings yet
- Lecture 4 Relational ModelDocument20 pagesLecture 4 Relational ModelMalik Adnan JaleelNo ratings yet
- CH 4-1 Relational Datamodel&constraintsDocument31 pagesCH 4-1 Relational Datamodel&constraintsAnshuman021No ratings yet
- Come 301 Dbms Lecture 4 Presentation SlidesDocument25 pagesCome 301 Dbms Lecture 4 Presentation SlidesKosayAudiNo ratings yet
- 20MCA002 (Assignment 2)Document11 pages20MCA002 (Assignment 2)AVINASH NISHAD 2002143No ratings yet
- Relational Data Modal 11 lacture-WPS OfficeDocument24 pagesRelational Data Modal 11 lacture-WPS Officemqasim sheikh5No ratings yet
- DBMS Architecture: Database ModelsDocument6 pagesDBMS Architecture: Database Modelsraazoo19No ratings yet
- Lecture 02 The Relational Model Part II The Relational Model and LanguagesDocument14 pagesLecture 02 The Relational Model Part II The Relational Model and LanguagesTrịnh Thái TuấnNo ratings yet
- Oracle Concepts ERD for Orders and ItemsDocument64 pagesOracle Concepts ERD for Orders and Itemsrahulvits007No ratings yet
- DBMS IiDocument9 pagesDBMS IiSiddharth DwivediNo ratings yet
- ISYS6028 Session 4 - The Relational ModelDocument24 pagesISYS6028 Session 4 - The Relational ModelJauharAzkaNo ratings yet
- Homework Chapter 9Document5 pagesHomework Chapter 9Angela PintoNo ratings yet
- Relational Data Model and Relational Constraints-CISDocument24 pagesRelational Data Model and Relational Constraints-CISFatima AhmedNo ratings yet
- 9.data Models Relational ModelDocument49 pages9.data Models Relational ModelAditya AnandNo ratings yet
- DBMS Unit 3Document25 pagesDBMS Unit 3Yash KadamNo ratings yet
- NormalizationDocument37 pagesNormalizationPrince HarshaNo ratings yet
- Relational - Database SystemDocument65 pagesRelational - Database SystemHuy LêNo ratings yet
- Database System Concepts & Architecture - Conceptual Data Modeling and Database DesignDocument46 pagesDatabase System Concepts & Architecture - Conceptual Data Modeling and Database DesignYohannes AsfawNo ratings yet
- Data Models and ConceptsDocument75 pagesData Models and ConceptsVijay KrishnaNo ratings yet
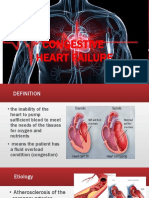
- Congestive Heart Failure: Title LayoutDocument14 pagesCongestive Heart Failure: Title LayoutWearIt Co.No ratings yet
- Rizal Law RA 1425Document1 pageRizal Law RA 1425WearIt Co.No ratings yet
- Iron Defficiency Anemia: Typically Results When The Intake of Dietary Iron Is Inadequate For Hemoglobin SynthesisDocument12 pagesIron Defficiency Anemia: Typically Results When The Intake of Dietary Iron Is Inadequate For Hemoglobin SynthesisLovelitestq ZamoraNo ratings yet
- 1 Introduction To DatabasesDocument23 pages1 Introduction To DatabasesJoana Key Abat SalvadorNo ratings yet
- CreateDBtblInsertLoginFormDocument3 pagesCreateDBtblInsertLoginFormWearIt Co.No ratings yet
- Collecting Data: Prepared By: Jon-Jon B. Corpuz, MaedDocument13 pagesCollecting Data: Prepared By: Jon-Jon B. Corpuz, MaedWearIt Co.No ratings yet
- Basic SyntaxesDocument7 pagesBasic SyntaxesWearIt Co.No ratings yet
- Hematologic Diagnostic Procedures and Anemia ManagementDocument12 pagesHematologic Diagnostic Procedures and Anemia ManagementLovelitestq ZamoraNo ratings yet
- Conceptual Theoretical FrameworkDocument3 pagesConceptual Theoretical FrameworkWearIt Co.No ratings yet
- Freedom Constitution and The 1987 ConstitutionDocument9 pagesFreedom Constitution and The 1987 ConstitutionWearIt Co.100% (1)
- CRUD Tutorial With SearchDocument17 pagesCRUD Tutorial With SearchWearIt Co.No ratings yet
- Business Taxation: - Back To BasicDocument56 pagesBusiness Taxation: - Back To BasicWearIt Co.No ratings yet
- Green IdeologyDocument1 pageGreen IdeologyWearIt Co.No ratings yet
- IA 1 Chapters 12 and 3Document46 pagesIA 1 Chapters 12 and 3Kyla BarbosaNo ratings yet
- CreateDBtblInsertLoginFormDocument3 pagesCreateDBtblInsertLoginFormWearIt Co.No ratings yet
- Local Media1269188023597947749Document2 pagesLocal Media1269188023597947749WearIt Co.No ratings yet
- Chapter 4: Exempt Sales of Goods, Properties and Services Exempt SalesDocument7 pagesChapter 4: Exempt Sales of Goods, Properties and Services Exempt SalesWearIt Co.No ratings yet
- Bir Form 2551Q (2018)Document2 pagesBir Form 2551Q (2018)Obin Tambasacan Baggayan33% (3)
- May Not Be Reproduced or Sold. All Text and Images © Wee Warrior Crafts, LLC, 2019Document1 pageMay Not Be Reproduced or Sold. All Text and Images © Wee Warrior Crafts, LLC, 2019WearIt Co.No ratings yet
- The Good Road by JoseDocument5 pagesThe Good Road by JoseWearIt Co.No ratings yet
- Transfer Tax NotesDocument3 pagesTransfer Tax NotesWearIt Co.No ratings yet
- Multiple Intelligences InventoryDocument4 pagesMultiple Intelligences InventoryleezenarosaNo ratings yet
- Congestive Heart Failure: Title LayoutDocument14 pagesCongestive Heart Failure: Title LayoutWearIt Co.No ratings yet
- PHP & Mysql: It84 - It Elective 1 (PHP Programming)Document17 pagesPHP & Mysql: It84 - It Elective 1 (PHP Programming)WearIt Co.No ratings yet
- Rad CHK MsgboxDocument9 pagesRad CHK MsgboxWearIt Co.No ratings yet
- Method of ProcedureDocument5 pagesMethod of ProcedureHARHSIT JAINNo ratings yet
- Oracle SlideDocument30 pagesOracle Slideshyam ranaNo ratings yet
- Introduction to Java Programming LanguageDocument34 pagesIntroduction to Java Programming LanguageBhavikAgrawalNo ratings yet
- Sajal Katare Resume - V2Document2 pagesSajal Katare Resume - V2Sajal KatareNo ratings yet
- 1NF, 2NF, 3NF and BCNF in Database Normalization - StudytonightDocument1 page1NF, 2NF, 3NF and BCNF in Database Normalization - StudytonightAngana Veenavi PereraNo ratings yet
- Problem Based Learning: Module BookDocument19 pagesProblem Based Learning: Module Bookmaya bangunNo ratings yet
- Moving Your Orion N PM DatabaseDocument9 pagesMoving Your Orion N PM DatabaseJorge Luis López VértizNo ratings yet
- Import Export OJSDocument9 pagesImport Export OJScompaq1501No ratings yet
- Test Bank For Modern Database Management 10th Edition by HofferDocument36 pagesTest Bank For Modern Database Management 10th Edition by Hoffertimaline.episodalstgd8g100% (42)
- Boot - Ubuntu 22.04 Build ISO (Both - MBR and EFI) - Ask UbuntuDocument3 pagesBoot - Ubuntu 22.04 Build ISO (Both - MBR and EFI) - Ask UbuntupacoNo ratings yet
- Hybrid Data Guard To OCI DBDocument35 pagesHybrid Data Guard To OCI DBAnonymous MlhE2saNo ratings yet
- Online Documentation For Altium Products - Tutorial - Using Version Control in Altium Designer - 2013-11-06Document12 pagesOnline Documentation For Altium Products - Tutorial - Using Version Control in Altium Designer - 2013-11-06mNo ratings yet
- Data Mining With Apriori AlgorithmDocument12 pagesData Mining With Apriori AlgorithmMAYANK JAINNo ratings yet
- Data Warehouse SchemasDocument87 pagesData Warehouse Schemassnivas1No ratings yet
- Running Head: Database Development 1Document11 pagesRunning Head: Database Development 1Jack SikoliaNo ratings yet
- Norcal OAUG BI PublisherDocument27 pagesNorcal OAUG BI PublisherKranthi-JuvvaNo ratings yet
- CTAP For NGFW - Data Privacy NoticeDocument3 pagesCTAP For NGFW - Data Privacy NoticeGiovanni -No ratings yet
- Enterprise Database Security & Monitoring: Alfred Horng IBM Software GroupDocument19 pagesEnterprise Database Security & Monitoring: Alfred Horng IBM Software GroupSean LamNo ratings yet
- SYmantec Error Code DescriptionDocument49 pagesSYmantec Error Code Descriptionsupradip deyNo ratings yet
- Project 2 Database Design and ETL: 1 Introduction: What Is This Project All About?Document16 pagesProject 2 Database Design and ETL: 1 Introduction: What Is This Project All About?EllenNo ratings yet
- Spatial Data Base Mangment The GIS BestDocument68 pagesSpatial Data Base Mangment The GIS BesthabteNo ratings yet
- TASK 3fngfgngfnbvnvbnvbnbvnvbnvbnvbnfDocument9 pagesTASK 3fngfgngfnbvnvbnvbnbvnvbnvbnvbnfIkhram JohariNo ratings yet
- Essentials of Marketing Research 6th Edition by Babin Zikmund ISBN Test BankDocument14 pagesEssentials of Marketing Research 6th Edition by Babin Zikmund ISBN Test Bankjeffrey100% (23)
- IntroductionDocument4 pagesIntroductionalexxNo ratings yet