You might also like
- National University of Technology CS4012 Database Systems Lab Assessment 04Document6 pagesNational University of Technology CS4012 Database Systems Lab Assessment 04Ansar IqbalNo ratings yet
- Bookworms Booklist - E-CollectionDocument4,760 pagesBookworms Booklist - E-CollectionRachelle Yu0% (2)
- User Guide: Elektronikon Mk5 Gateway ModuleDocument24 pagesUser Guide: Elektronikon Mk5 Gateway ModuleMohd Faidzal100% (1)
- Data Mining IssuesDocument5 pagesData Mining IssuesBoobalan RNo ratings yet
- Data Mining: An Overview From Database Perspective: Index TermsDocument41 pagesData Mining: An Overview From Database Perspective: Index TermsJaison JustusNo ratings yet
- Lecture 6-Data Mining and WarehousingDocument7 pagesLecture 6-Data Mining and WarehousingKelvin TetoNo ratings yet
- Data MiningDocument29 pagesData MiningMiel9226No ratings yet
- Data Mining Issues and KDD ProcessDocument10 pagesData Mining Issues and KDD ProcessShubham GuptaNo ratings yet
- Data Mining An Overview From A Database PerspectiveDocument18 pagesData Mining An Overview From A Database PerspectiveThanish RaoNo ratings yet
- Laq 1Document2 pagesLaq 1api-198533427No ratings yet
- DMW UNIT 1 PessondranathDocument29 pagesDMW UNIT 1 Pessondranath2344Atharva PatilNo ratings yet
- Lecture 4Document6 pagesLecture 4mohammed.riad.bi.2020No ratings yet
- Data MiningDocument11 pagesData MiningRahul KalyankarNo ratings yet
- Data Mining Written Notes 1Document35 pagesData Mining Written Notes 1Angel SweetyNo ratings yet
- Data Mining and WarehouseDocument30 pagesData Mining and Warehousenoelbaptist827No ratings yet
- Recommender System - Module 2 - Data Mining Techniques in Recommender SystemDocument58 pagesRecommender System - Module 2 - Data Mining Techniques in Recommender SystemDainikMitraNo ratings yet
- Recommender System - Module 2 - Data Mining Techniques in Recommender SystemDocument58 pagesRecommender System - Module 2 - Data Mining Techniques in Recommender SystemDainikMitraNo ratings yet
- Introduction to Data Mining - Analyzing Vast Amounts of Daily DataDocument14 pagesIntroduction to Data Mining - Analyzing Vast Amounts of Daily DataSonga SowjanyaNo ratings yet
- Data Mining Techniques and ApplicationsDocument26 pagesData Mining Techniques and ApplicationsKishor PeddiNo ratings yet
- Lec 01 Data MiningDocument25 pagesLec 01 Data MiningMusa SavageNo ratings yet
- # Understanding DM IssuesDocument34 pages# Understanding DM IssuesDan MasangaNo ratings yet
- Knowledge Mining: Extracting Patterns from DataDocument16 pagesKnowledge Mining: Extracting Patterns from DataKathyaini AlagirisamyNo ratings yet
- Data Mining Notes1Document56 pagesData Mining Notes1SOORAJ CHANDRANNo ratings yet
- Whats AppDocument23 pagesWhats AppRâjä SékhãrNo ratings yet
- Gokaraju Rangaraju Institute of Engineering and TechnologyDocument49 pagesGokaraju Rangaraju Institute of Engineering and TechnologyRamya TejaNo ratings yet
- Trends in Data MiningDocument9 pagesTrends in Data MiningLalitha NaiduNo ratings yet
- DM Unit-1 NotesDocument47 pagesDM Unit-1 Notesbalijagudam shashankNo ratings yet
- Data MiningDocument16 pagesData MiningTanish SaajanNo ratings yet
- 358 44 Datamining and Warehousing 4.4Document155 pages358 44 Datamining and Warehousing 4.4learn naetNo ratings yet
- Major Issues in Data Mining: V. Saranya Ap/Cse Sri Vidya College of Engineering & Technology, VirudhunagarDocument10 pagesMajor Issues in Data Mining: V. Saranya Ap/Cse Sri Vidya College of Engineering & Technology, VirudhunagarbhargaviNo ratings yet
- Week 1-2Document3 pagesWeek 1-2Âįmân ŚhêikhNo ratings yet
- Lesson 3 - Classifying and Predicting Data PatternsDocument3 pagesLesson 3 - Classifying and Predicting Data PatternsromnelleNo ratings yet
- Unit - 4 Introduction To Data MiningDocument71 pagesUnit - 4 Introduction To Data MiningRuchiraNo ratings yet
- Data Warehousing & Data Mining Syllabus Subject Code:56055 L:4 T/P/D:0 Credits:4 Int. Marks:25 Ext. Marks:75 Total Marks:100Document52 pagesData Warehousing & Data Mining Syllabus Subject Code:56055 L:4 T/P/D:0 Credits:4 Int. Marks:25 Ext. Marks:75 Total Marks:100hanmanthNo ratings yet
- ChandrakanthDocument64 pagesChandrakanthSuresh DhamathotiNo ratings yet
- Database Use in Data Warehousing and MiningDocument19 pagesDatabase Use in Data Warehousing and Miningmecool86No ratings yet
- CS1011 Data Warehousing and Data Mining Course MaterialDocument96 pagesCS1011 Data Warehousing and Data Mining Course Materialjames russell west brookNo ratings yet
- Data Mining and Warehousing-1Document43 pagesData Mining and Warehousing-1Vijay Kumar SainiNo ratings yet
- Use of Database in Data Warehousing: What Motivated Data Mining? Why Is It Important?Document19 pagesUse of Database in Data Warehousing: What Motivated Data Mining? Why Is It Important?mecool86No ratings yet
- Data Warehouse PresentationDocument28 pagesData Warehouse PresentationPrasad DhanikondaNo ratings yet
- Main of ReportDocument23 pagesMain of Reportapi-20013961No ratings yet
- ARM and DBSCAN data mining techniquesDocument1 pageARM and DBSCAN data mining techniquesCH Rajan GujjarNo ratings yet
- Data Mining & Data WarehousingDocument84 pagesData Mining & Data Warehousingeyoung9No ratings yet
- Chapter 11 2 Applications and Trends in Data MiningDocument2 pagesChapter 11 2 Applications and Trends in Data MiningbharathimanianNo ratings yet
- Unit 1fDocument50 pagesUnit 1fVasudevarao PeyyetiNo ratings yet
- Unit-I DW&DMDocument19 pagesUnit-I DW&DMthe sinha'sNo ratings yet
- LECTURE NOTES ON DATA MINING and DATA WADocument84 pagesLECTURE NOTES ON DATA MINING and DATA WAAli AzfarNo ratings yet
- References: Machine Learning Tools and Techniques, 2 EditionDocument32 pagesReferences: Machine Learning Tools and Techniques, 2 EditionDwi Wahyu PrabowoNo ratings yet
- Unit 1Document9 pagesUnit 1sunnynnusNo ratings yet
- Data Mining and Data Analysis UNIT-1 Notes For PrintDocument22 pagesData Mining and Data Analysis UNIT-1 Notes For PrintpadmaNo ratings yet
- AS C I T T D M: Tudy ON Omputational Ntelligence Echniques O ATA IningDocument13 pagesAS C I T T D M: Tudy ON Omputational Ntelligence Echniques O ATA IningpancawawanNo ratings yet
- 1 ST Review DocumentDocument37 pages1 ST Review DocumentsumaniceNo ratings yet
- Why We Need Data Mining?Document39 pagesWhy We Need Data Mining?Bhanu RoyceNo ratings yet
- Data Mining and Data Warehousing Lecture NotesDocument84 pagesData Mining and Data Warehousing Lecture NotesNikhila GoliNo ratings yet
- # Understanding DM Architecture, KDD & DM ToolsDocument29 pages# Understanding DM Architecture, KDD & DM ToolsDan MasangaNo ratings yet
- Data Mining Functionalities and IssuesDocument12 pagesData Mining Functionalities and Issuesnaman gujarathiNo ratings yet
- Data Warehousing & Mining BasicsDocument40 pagesData Warehousing & Mining BasicsRavi SistaNo ratings yet
- BDA Unit 1Document50 pagesBDA Unit 1Alekhya AbbarajuNo ratings yet
- Screenshot 2023-10-19 at 11.36.57Document27 pagesScreenshot 2023-10-19 at 11.36.57mr2b9jfhy4No ratings yet
- Data Mining in Digital LibraryDocument5 pagesData Mining in Digital LibrarymonikaNo ratings yet
- CHP 19Document63 pagesCHP 19mona yadvNo ratings yet
- Data Analysis in the Cloud: Models, Techniques and ApplicationsFrom EverandData Analysis in the Cloud: Models, Techniques and ApplicationsNo ratings yet
- Display ASCII: #Include Using Namespace STDDocument26 pagesDisplay ASCII: #Include Using Namespace STDLikith MallipeddiNo ratings yet
- Tarp DocumentDocument16 pagesTarp DocumentLikith MallipeddiNo ratings yet
- Data Mining Review - 1Document9 pagesData Mining Review - 1Likith MallipeddiNo ratings yet
- Letter of IntentDocument1 pageLetter of IntentLikith MallipeddiNo ratings yet
- Article TemplateDocument1 pageArticle TemplateLikith MallipeddiNo ratings yet
- Urban Planning: Digital Assignment - 1Document10 pagesUrban Planning: Digital Assignment - 1Likith MallipeddiNo ratings yet
- DA-I Question Bank From Module 1-3 of PHY1701 Course, Winter Semester 2020-21Document6 pagesDA-I Question Bank From Module 1-3 of PHY1701 Course, Winter Semester 2020-21Likith MallipeddiNo ratings yet
- 4-Confluence of Multiple Disciplines, Classifictaion, Integration-08-Feb-2021Material I 08-Feb-2021 Mod1 Confluence ClassifictaionDocument4 pages4-Confluence of Multiple Disciplines, Classifictaion, Integration-08-Feb-2021Material I 08-Feb-2021 Mod1 Confluence ClassifictaionLikith MallipeddiNo ratings yet
- 2-Stages of Data Mining Process, Data Mining Knowledge Representation-03-Feb-2021Material - I - 03-Feb-2021 - Mod1 - StagesDocument10 pages2-Stages of Data Mining Process, Data Mining Knowledge Representation-03-Feb-2021Material - I - 03-Feb-2021 - Mod1 - StagesLikith MallipeddiNo ratings yet
- Data Mining Functionalities:: - Characterization and DiscriminationDocument21 pagesData Mining Functionalities:: - Characterization and DiscriminationLikith MallipeddiNo ratings yet
- 2-Stages of Data Mining Process, Data Mining Knowledge Representation-03-Feb-2021Material - I - 03-Feb-2021 - Mod1 - StagesDocument10 pages2-Stages of Data Mining Process, Data Mining Knowledge Representation-03-Feb-2021Material - I - 03-Feb-2021 - Mod1 - StagesLikith MallipeddiNo ratings yet
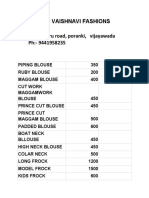
- Nidamanuru Road, Poranki, Vijayawada: Sri Vaishnavi FashionsDocument2 pagesNidamanuru Road, Poranki, Vijayawada: Sri Vaishnavi FashionsLikith MallipeddiNo ratings yet
- 2-Stages of Data Mining Process, Data Mining Knowledge Representation-03-Feb-2021Material - I - 03-Feb-2021 - Mod1 - StagesDocument10 pages2-Stages of Data Mining Process, Data Mining Knowledge Representation-03-Feb-2021Material - I - 03-Feb-2021 - Mod1 - StagesLikith MallipeddiNo ratings yet
- 3 Functionalities 04 Feb 2021material I 04 Feb 2021 Mod1 FunctionalitiesDocument21 pages3 Functionalities 04 Feb 2021material I 04 Feb 2021 Mod1 FunctionalitiesLikith MallipeddiNo ratings yet
- 2-Stages of Data Mining Process, Data Mining Knowledge Representation-03-Feb-2021Material - I - 03-Feb-2021 - Mod1 - StagesDocument10 pages2-Stages of Data Mining Process, Data Mining Knowledge Representation-03-Feb-2021Material - I - 03-Feb-2021 - Mod1 - StagesLikith MallipeddiNo ratings yet
- 2-Stages of Data Mining Process, Data Mining Knowledge Representation-03-Feb-2021Material - I - 03-Feb-2021 - Mod1 - StagesDocument10 pages2-Stages of Data Mining Process, Data Mining Knowledge Representation-03-Feb-2021Material - I - 03-Feb-2021 - Mod1 - StagesLikith MallipeddiNo ratings yet
- 2-Stages of Data Mining Process, Data Mining Knowledge Representation-03-Feb-2021Material - I - 03-Feb-2021 - Mod1 - StagesDocument10 pages2-Stages of Data Mining Process, Data Mining Knowledge Representation-03-Feb-2021Material - I - 03-Feb-2021 - Mod1 - StagesLikith MallipeddiNo ratings yet
- Final - Course - Outcomes - of - All - Courses - Comp Dept - RCTIDocument14 pagesFinal - Course - Outcomes - of - All - Courses - Comp Dept - RCTISmit PankhaniaNo ratings yet
- Cwms - B - User Guide Cwms 4 0Document90 pagesCwms - B - User Guide Cwms 4 0DRI HQ CINo ratings yet
- Guri Final Year ReportDocument40 pagesGuri Final Year ReportadaNo ratings yet
- MVT model view templateDocument8 pagesMVT model view templateVenu DNo ratings yet
- Availability Is Not Equal To ReliabilityDocument5 pagesAvailability Is Not Equal To ReliabilityIwan AkurNo ratings yet
- BeamdirectionDocument8 pagesBeamdirectionyacine bouazniNo ratings yet
- Learning Book - Theory, Methodology, Tools and Applications For Modeling and Simulation of Complex Systems - 3 PDFDocument580 pagesLearning Book - Theory, Methodology, Tools and Applications For Modeling and Simulation of Complex Systems - 3 PDFhoussem eddineNo ratings yet
- Python StringsDocument52 pagesPython StringsStudyopediaNo ratings yet
- Mekatronik Sistem Tasarımı SlaytDocument33 pagesMekatronik Sistem Tasarımı SlaytM Kasım YılmazNo ratings yet
- Shaik Khaleel Miya.: Client: General Data Tech (Jan 2020 To Present)Document2 pagesShaik Khaleel Miya.: Client: General Data Tech (Jan 2020 To Present)Mohd ShoaibNo ratings yet
- IC Sample Scope of Work 11358 - WORDDocument4 pagesIC Sample Scope of Work 11358 - WORDQAQC OmtechNo ratings yet
- Wireframes: Communication & Multimedia DesignDocument15 pagesWireframes: Communication & Multimedia DesignGarimaNo ratings yet
- Cloudiax by Comparison: Ready To Use SAP Business OneDocument1 pageCloudiax by Comparison: Ready To Use SAP Business OneSaif Ali MominNo ratings yet
- Instruktsiya Sony-WH CH720NDocument129 pagesInstruktsiya Sony-WH CH720Njohed97094No ratings yet
- Erori La Instalare BC16Document3 pagesErori La Instalare BC16Gelu MoldovanNo ratings yet
- 1 Tập Tin Đích: Victoria Can Tho HotelDocument81 pages1 Tập Tin Đích: Victoria Can Tho Hotelapi-26179120No ratings yet
- Open NNDocument2 pagesOpen NNsophia787No ratings yet
- Partho Protim SanyalDocument1 pagePartho Protim Sanyalabdulafsar586No ratings yet
- TM112: Introduction to Computing and Information Technology 2Document50 pagesTM112: Introduction to Computing and Information Technology 2Husam NaserNo ratings yet
- MDM9206 Data Features Overview: 80-P8101-7 Rev. CDocument52 pagesMDM9206 Data Features Overview: 80-P8101-7 Rev. CprakashnpkNo ratings yet
- En - stm32-Stm8 Embedded Software SolutionsDocument108 pagesEn - stm32-Stm8 Embedded Software SolutionsAswath RangarajNo ratings yet
- Cnav 3050Document189 pagesCnav 3050Charly LyraNo ratings yet
- Ambo University Woliso Campus: Advanced Database For 2 YearDocument48 pagesAmbo University Woliso Campus: Advanced Database For 2 YearTesfahun Maru100% (1)
- Iw 7Document49 pagesIw 7AlkaNo ratings yet
- Event Driven Programming: Class ScheduleDocument7 pagesEvent Driven Programming: Class ScheduleOlsen CortunaNo ratings yet
- Chapter 1BDocument54 pagesChapter 1BnadiaNo ratings yet
- Accumark Made-To-Measure: OptimumDocument2 pagesAccumark Made-To-Measure: Optimumahmed esmatNo ratings yet