You might also like
- CADD Unit 4 TPDocument7 pagesCADD Unit 4 TPmohitNo ratings yet
- Deep Action An Approach On The Basis of Deep Learning For The Prediction of Novel Drug-Target InteractionsDocument6 pagesDeep Action An Approach On The Basis of Deep Learning For The Prediction of Novel Drug-Target InteractionsInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Clinical Drug Interaction DatasetDocument6 pagesClinical Drug Interaction DatasetDavidNo ratings yet
- MMDD - Digital Assignmen2Document9 pagesMMDD - Digital Assignmen2SAMMY KHANNo ratings yet
- Unit 5-Bioinformatics-DRUG DISCOVERY-02.01.22Document8 pagesUnit 5-Bioinformatics-DRUG DISCOVERY-02.01.2220SMB24 - ShafanaNo ratings yet
- Jakupovic 2018Document4 pagesJakupovic 2018smritii bansalNo ratings yet
- Artificial Intelligence in Early Drug Discovery Enabling Precision MedicineDocument18 pagesArtificial Intelligence in Early Drug Discovery Enabling Precision Medicine23Anggita AyuTipaNo ratings yet
- Artificial Neural Networks in Medical SciencesDocument6 pagesArtificial Neural Networks in Medical SciencesIJRASETPublicationsNo ratings yet
- Research PaperDocument20 pagesResearch PaperShristi Das BiswasNo ratings yet
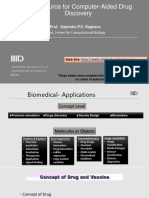
- Open Source For Computer-Aided Drug Discovery: Prof. Gajendra P.S. RaghavaDocument190 pagesOpen Source For Computer-Aided Drug Discovery: Prof. Gajendra P.S. RaghavaVaibhav JindalNo ratings yet
- Li 2017 Improving The in Silico AssessmentDocument12 pagesLi 2017 Improving The in Silico AssessmentsadsadNo ratings yet
- InvdockDocument10 pagesInvdockiancasvitNo ratings yet
- 5 Vol. 210 IJPSR 331 Review 5Document13 pages5 Vol. 210 IJPSR 331 Review 5Tukai KulkarniNo ratings yet
- 1 s2.0 S2666379121003694 MainDocument21 pages1 s2.0 S2666379121003694 MainAldera76No ratings yet
- Radiogenomic Analysis of Oncological Data: A Technical SurveyDocument28 pagesRadiogenomic Analysis of Oncological Data: A Technical SurveyPriyanka VermaNo ratings yet
- Pocket2Drug: An Encoder-Decoder Deep Neural Network For The Target-Based Drug DesignDocument12 pagesPocket2Drug: An Encoder-Decoder Deep Neural Network For The Target-Based Drug DesignmbrylinskiNo ratings yet
- Chemometric Methods For Spectroscopy-Based Pharmaceutical AnalysisDocument14 pagesChemometric Methods For Spectroscopy-Based Pharmaceutical AnalysisNandini GattadahalliNo ratings yet
- The Drug Discovery Process: Studies of Disease MechanismsDocument7 pagesThe Drug Discovery Process: Studies of Disease MechanismsSajanMaharjanNo ratings yet
- Artificial Intelligence in Drug Discovery Recent Advances and Future PerspectivesDocument12 pagesArtificial Intelligence in Drug Discovery Recent Advances and Future PerspectivesnikhilNo ratings yet
- Computer Aided Drug Design (Cadd) : Naresh.T M.Pharmacy 1 YR/1 SEMDocument40 pagesComputer Aided Drug Design (Cadd) : Naresh.T M.Pharmacy 1 YR/1 SEMJainendra JainNo ratings yet
- Biomarker-Based Drug Safety Assessment in The Age of Systems Pharmacology From Foundational To Regulatory ScienceDocument12 pagesBiomarker-Based Drug Safety Assessment in The Age of Systems Pharmacology From Foundational To Regulatory Scienceminglei.yeNo ratings yet
- Applications of Machine Learning To Diagnosis and Treatment of Neurodegenerative DiseasesDocument17 pagesApplications of Machine Learning To Diagnosis and Treatment of Neurodegenerative DiseasesgcinarNo ratings yet
- 1999 - Mird 16Document26 pages1999 - Mird 16Teresa PerezNo ratings yet
- The Drug Discovery Process: Studies of Disease MechanismsDocument23 pagesThe Drug Discovery Process: Studies of Disease MechanismssantusNo ratings yet
- ELS Lec 11-LMSDocument37 pagesELS Lec 11-LMSrajivNo ratings yet
- Reducing Attrition Through Early Assessment of Drug SafetyDocument6 pagesReducing Attrition Through Early Assessment of Drug Safetyירדן לויןNo ratings yet
- The Power of Deep Learning To Ligand-Based Novel Drug DiscoveryDocument11 pagesThe Power of Deep Learning To Ligand-Based Novel Drug DiscoveryBilal AhmadNo ratings yet
- Evolving Scenario of Big Data and Artificial Intelligence (AI) in Drug DiscoveryDocument22 pagesEvolving Scenario of Big Data and Artificial Intelligence (AI) in Drug Discoverypaulo alonsoNo ratings yet
- Recent Updates On Nanomedicine Based Products: Current Sce-Nario and Future OpportunitiesDocument13 pagesRecent Updates On Nanomedicine Based Products: Current Sce-Nario and Future OpportunitiesvijuNo ratings yet
- ScribedDocument12 pagesScribedDr. Victor Adolfo RochaNo ratings yet
- Gulumian SAJS 2012Document9 pagesGulumian SAJS 2012Neo Mervyn MonahengNo ratings yet
- BMJ m127 FullDocument11 pagesBMJ m127 FullDiana DianaNo ratings yet
- Application of in Silico Approaches To Predicting Drug-Drug InteractionsDocument5 pagesApplication of in Silico Approaches To Predicting Drug-Drug InteractionsamanuipsNo ratings yet
- Molecular Dynamics Simulations and Novel Drug DiscoveryDocument16 pagesMolecular Dynamics Simulations and Novel Drug DiscoveryRishavNo ratings yet
- Drug-Abuse Nanotechnology: Opportunities and Challenges: Morteza Mahmoudi, Sepideh Pakpour, and George PerryDocument11 pagesDrug-Abuse Nanotechnology: Opportunities and Challenges: Morteza Mahmoudi, Sepideh Pakpour, and George PerryEma UrzicaNo ratings yet
- Thnov 06 P 1306Document18 pagesThnov 06 P 1306julidedysonNo ratings yet
- Drug 3Document6 pagesDrug 3Salem Optimus Technocrates India Private LimitedNo ratings yet
- Small-Molecule Library Screening by Docking With Pyrx: Sargis Dallakyan and Arthur J. OlsonDocument8 pagesSmall-Molecule Library Screening by Docking With Pyrx: Sargis Dallakyan and Arthur J. OlsonzahidNo ratings yet
- A Network Integration Approach For Drug Target Interaction Prediction and Computational Drug RepositioningDocument13 pagesA Network Integration Approach For Drug Target Interaction Prediction and Computational Drug RepositioningWirawan AdikusumaNo ratings yet
- Drug Discovery and Drug DesignDocument77 pagesDrug Discovery and Drug DesignMeyrika Putri Wandala S1 2018No ratings yet
- 2020 - Which Psychotherapy Is Effective inDocument9 pages2020 - Which Psychotherapy Is Effective inadelacrovara.seoNo ratings yet
- Drug - Disease Association For DrugDocument3 pagesDrug - Disease Association For DrugInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- 2 Overall DD DDDocument10 pages2 Overall DD DDUjwal Shinde USNo ratings yet
- Fabbs Cnsf2011-Thomas Rick-PosterDocument1 pageFabbs Cnsf2011-Thomas Rick-PosterAlizbah KazmiNo ratings yet
- CADD Unit 4 2Document11 pagesCADD Unit 4 2mohitNo ratings yet
- Expert Systems - 2021 - Shan - COVID 19 Patient Diagnosis and Treatment Data Mining Algorithm Based On Association RulesDocument13 pagesExpert Systems - 2021 - Shan - COVID 19 Patient Diagnosis and Treatment Data Mining Algorithm Based On Association RulesAkbar aliNo ratings yet
- Performance Analysis of ANN and Naive Bayes Classification Algorithm For Data ClassificationDocument4 pagesPerformance Analysis of ANN and Naive Bayes Classification Algorithm For Data ClassificationKillerbeeNo ratings yet
- International Postermaking - 21pca009Document1 pageInternational Postermaking - 21pca009Fun GadgetsNo ratings yet
- Aguero NatureReviewsDrugDiscovery 2008Document8 pagesAguero NatureReviewsDrugDiscovery 2008Fathima BasariyaNo ratings yet
- Classification of Cancerous Profiles Using Machine LearningDocument6 pagesClassification of Cancerous Profiles Using Machine LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- URI Poster Nguyen Thi Bich Ngoc, Tran Thi Huong 2020 GRAPHDocument1 pageURI Poster Nguyen Thi Bich Ngoc, Tran Thi Huong 2020 GRAPHHUONGNo ratings yet
- Integration and Visualization of Gene Selection and Gene Regulatory Networks for Cancer GenomeFrom EverandIntegration and Visualization of Gene Selection and Gene Regulatory Networks for Cancer GenomeNo ratings yet
- From Single Drug Targets To Synergistic Network Pharmacology in Ischemic StrokeDocument8 pagesFrom Single Drug Targets To Synergistic Network Pharmacology in Ischemic StrokeSharan SahotaNo ratings yet
- Cramer Et Al 2019 Neurologic Medical Device Overview For PathologistsDocument14 pagesCramer Et Al 2019 Neurologic Medical Device Overview For Pathologistsb00403007No ratings yet
- Evolving Regulatory Perspectives On Digital Health Technologies For Medicinal Product DevelopmentDocument11 pagesEvolving Regulatory Perspectives On Digital Health Technologies For Medicinal Product DevelopmentNot 8No ratings yet
- 1 s2.0 S235291482200034X MainDocument18 pages1 s2.0 S235291482200034X MainpedroNo ratings yet
- Med TechniqueDocument15 pagesMed TechniqueBHARGAVI DEVADIGANo ratings yet
- Roadmap On NanomedicineDocument27 pagesRoadmap On NanomedicineSudeep BhattacharyyaNo ratings yet
- Mobile Technology For Primary Stroke Prevention: Brief ReportDocument3 pagesMobile Technology For Primary Stroke Prevention: Brief ReportOrsolya FilepNo ratings yet
- Phytopathology DiagnosisDocument9 pagesPhytopathology DiagnosisRUBESH M 20ITA44No ratings yet
- Display ASCII: #Include Using Namespace STDDocument26 pagesDisplay ASCII: #Include Using Namespace STDLikith MallipeddiNo ratings yet
- Urban Planning: Digital Assignment - 1Document10 pagesUrban Planning: Digital Assignment - 1Likith MallipeddiNo ratings yet
- Letter of IntentDocument1 pageLetter of IntentLikith MallipeddiNo ratings yet
- Tarp DocumentDocument16 pagesTarp DocumentLikith MallipeddiNo ratings yet
- DA-I Question Bank From Module 1-3 of PHY1701 Course, Winter Semester 2020-21Document6 pagesDA-I Question Bank From Module 1-3 of PHY1701 Course, Winter Semester 2020-21Likith MallipeddiNo ratings yet
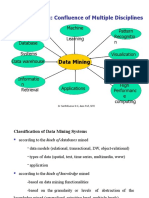
- 4-Confluence of Multiple Disciplines, Classifictaion, Integration-08-Feb-2021Material I 08-Feb-2021 Mod1 Confluence ClassifictaionDocument4 pages4-Confluence of Multiple Disciplines, Classifictaion, Integration-08-Feb-2021Material I 08-Feb-2021 Mod1 Confluence ClassifictaionLikith MallipeddiNo ratings yet
- Nidamanuru Road, Poranki, Vijayawada: Sri Vaishnavi FashionsDocument2 pagesNidamanuru Road, Poranki, Vijayawada: Sri Vaishnavi FashionsLikith MallipeddiNo ratings yet
- Data Mining Functionalities:: - Characterization and DiscriminationDocument21 pagesData Mining Functionalities:: - Characterization and DiscriminationLikith MallipeddiNo ratings yet
- 5 Major Issues 10 Feb 2021material I 10 Feb 2021 Mod1 IssuesDocument5 pages5 Major Issues 10 Feb 2021material I 10 Feb 2021 Mod1 IssuesLikith MallipeddiNo ratings yet
- 3 Functionalities 04 Feb 2021material I 04 Feb 2021 Mod1 FunctionalitiesDocument21 pages3 Functionalities 04 Feb 2021material I 04 Feb 2021 Mod1 FunctionalitiesLikith MallipeddiNo ratings yet
- 07 Array ProcessingDocument15 pages07 Array ProcessingRakaBetaNo ratings yet
- Minimax With - Alpha Beta PruningDocument9 pagesMinimax With - Alpha Beta PruningmmahmoudNo ratings yet
- Deep Learning Totally From ScratchDocument52 pagesDeep Learning Totally From Scratchbert hubertNo ratings yet
- Course: Machine Learning Duration: 30-40 Hours Course Fee: 12000/-Course DescriptionDocument2 pagesCourse: Machine Learning Duration: 30-40 Hours Course Fee: 12000/-Course DescriptionPadmini PalliNo ratings yet
- Figures For Chapter 8 Introduction To Data Mining: by Tan, Steinbach, KumarDocument41 pagesFigures For Chapter 8 Introduction To Data Mining: by Tan, Steinbach, KumarPhantom BeingNo ratings yet
- Rayleigh Ritz Method: APL705 Finite Element MethodDocument4 pagesRayleigh Ritz Method: APL705 Finite Element MethodAshitosh KadamNo ratings yet
- Interpretable Machine LearningDocument7 pagesInterpretable Machine LearningbkiakisolakoNo ratings yet
- Classical Control 1 Sche A MeDocument7 pagesClassical Control 1 Sche A MeEric Leo AsiamahNo ratings yet
- A Survey Paper of Bellman-Ford Algorithm and Dijkstra Algorithm For Finding Shortest Path in GIS ApplicationDocument3 pagesA Survey Paper of Bellman-Ford Algorithm and Dijkstra Algorithm For Finding Shortest Path in GIS ApplicationyashNo ratings yet
- I. Comment On The Effect of Profmarg On CEO Salary. Ii. Does Market Value Have A Significant Effect? ExplainDocument5 pagesI. Comment On The Effect of Profmarg On CEO Salary. Ii. Does Market Value Have A Significant Effect? ExplainTrang TrầnNo ratings yet
- Lecture 3 Answers 1Document5 pagesLecture 3 Answers 1Thắng ThôngNo ratings yet
- Eee-V-Signals and Systems U3Document17 pagesEee-V-Signals and Systems U3Charan V ChanNo ratings yet
- Transportation ProblemDocument10 pagesTransportation Problempuneeth hNo ratings yet
- ch6 Mitra DSP C PDFDocument62 pagesch6 Mitra DSP C PDFjisha mvNo ratings yet
- 3F3 2a More On DFTDocument16 pages3F3 2a More On DFTSarvender SinghNo ratings yet
- Accepted Manuscript: 10.1016/j.applthermaleng.2014.03.055Document43 pagesAccepted Manuscript: 10.1016/j.applthermaleng.2014.03.055parth bhalaNo ratings yet
- Convex and Concave FunctionsDocument3 pagesConvex and Concave FunctionsrnmukerjeeNo ratings yet
- For Every Linear Programming Problem Whether Maximization or Minimization Has Associated With It Another Mirror Image Problem Based On Same DataDocument21 pagesFor Every Linear Programming Problem Whether Maximization or Minimization Has Associated With It Another Mirror Image Problem Based On Same DataAffu ShaikNo ratings yet
- Bayesian Statistics: Thomas BayesDocument22 pagesBayesian Statistics: Thomas BayesAn NguyenNo ratings yet
- No.1 Maths Guru: Practice Set: Matrix TIME-1.30 MDocument2 pagesNo.1 Maths Guru: Practice Set: Matrix TIME-1.30 MABDUS SAMADNo ratings yet
- An Empirical Comparison and Evaluation of Minority OversamplingDocument13 pagesAn Empirical Comparison and Evaluation of Minority Oversamplingnitelay355No ratings yet
- BCA 3.3 Non Linear Data Structure Using C++Document18 pagesBCA 3.3 Non Linear Data Structure Using C++UMESH SIRMVNo ratings yet
- The Memory Palace - A Quick Refresher For Your CISSP ExamDocument127 pagesThe Memory Palace - A Quick Refresher For Your CISSP Examjunyan.quNo ratings yet
- QABD OverviewDocument70 pagesQABD OverviewSai VarunNo ratings yet
- The Lagrangian Equation ExamplesDocument8 pagesThe Lagrangian Equation ExamplesGustavo100% (1)
- ch01 Overview NemoDocument32 pagesch01 Overview NemoAkula SreenivasuluNo ratings yet
- Gujarat Technological University: W.E.F. AY 2018-19Document4 pagesGujarat Technological University: W.E.F. AY 2018-19dpatel 2310No ratings yet
- Data Warehouse AdministrationDocument14 pagesData Warehouse AdministrationJoe HanNo ratings yet
- Pert/Cpm: Short Note: Pert: Project Evaluation and Review Technique (PERT) Is A Procedure Through WhichDocument13 pagesPert/Cpm: Short Note: Pert: Project Evaluation and Review Technique (PERT) Is A Procedure Through WhichHenryNo ratings yet
- Unit - V: Sorting and SearchingDocument21 pagesUnit - V: Sorting and SearchinghemanthNo ratings yet