You might also like
- Error and Uncertainty: General Statistical PrinciplesDocument8 pagesError and Uncertainty: General Statistical Principlesdéborah_rosalesNo ratings yet
- Solutions To II Unit Exercises From KamberDocument16 pagesSolutions To II Unit Exercises From Kamberjyothibellaryv83% (42)
- Measures of VariabilityDocument71 pagesMeasures of VariabilityRinna Legaspi100% (1)
- (SIGNED) PSA 2021-2025 Strategic PlanDocument76 pages(SIGNED) PSA 2021-2025 Strategic PlanGITA SAFITRINo ratings yet
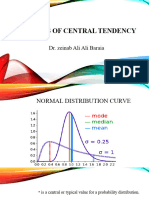
- Measures of Central TendencyDocument8 pagesMeasures of Central TendencyAnnie Claire VisoriaNo ratings yet
- GCSE Maths Revision: Cheeky Revision ShortcutsFrom EverandGCSE Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (2)
- Introduction To GUI BuildingDocument6 pagesIntroduction To GUI BuildingErnesto S. Caseres JrNo ratings yet
- Soviet Flower ChildrenDocument21 pagesSoviet Flower ChildrenKimmie PetkovNo ratings yet
- Mean Median ModeDocument12 pagesMean Median ModeSriram Mohan100% (3)
- Descriptive Statistics PDFDocument130 pagesDescriptive Statistics PDFShaheed MorweNo ratings yet
- 15 Types of Regression You Should KnowDocument30 pages15 Types of Regression You Should KnowRashidAliNo ratings yet
- Hanna Havnevik - Tibetan Buddhist Nuns - History, Cultural Norms and Social Reality (Excerpt)Document126 pagesHanna Havnevik - Tibetan Buddhist Nuns - History, Cultural Norms and Social Reality (Excerpt)YDYD1234100% (3)
- Research 8 Grade 8 Melc 1 q4 Week1Document26 pagesResearch 8 Grade 8 Melc 1 q4 Week1iancyrillvillamer10No ratings yet
- 0 - Last Module Math in The Modern WorldDocument20 pages0 - Last Module Math in The Modern WorldCristy Lansangan Mejia50% (2)
- Structural Equation Modeling Using AMOS: An IntroductionDocument64 pagesStructural Equation Modeling Using AMOS: An IntroductionErShadman100% (2)
- Background of The StudyintroductionDocument10 pagesBackground of The StudyintroductionErnesto S. Caseres JrNo ratings yet
- Mathematical AnalysisDocument46 pagesMathematical AnalysisGilbert Dwasi100% (1)
- Basic Statistical Descriptions of Data: Dr. Amiya Ranjan PandaDocument35 pagesBasic Statistical Descriptions of Data: Dr. Amiya Ranjan PandaAnu agarwalNo ratings yet
- Measures of VariationDocument30 pagesMeasures of VariationJahbie ReyesNo ratings yet
- For The Students - MODULE 3 - Week 5-7 - Numerical Techniques in Describing DataDocument24 pagesFor The Students - MODULE 3 - Week 5-7 - Numerical Techniques in Describing DataAgravante LourdesNo ratings yet
- Introduction To StatisticsDocument42 pagesIntroduction To StatisticsGeetu SodhiNo ratings yet
- Chapter 4Document58 pagesChapter 4meia quiderNo ratings yet
- 2 - Chapter 1 - Measures of Central Tendency and Variation NewDocument18 pages2 - Chapter 1 - Measures of Central Tendency and Variation NewDmddldldldl100% (1)
- Notas EstadisticaDocument20 pagesNotas EstadisticaCristian CanazaNo ratings yet
- MMW-7 2Document40 pagesMMW-7 2Unknown UnknownNo ratings yet
- QQQMDocument16 pagesQQQMmonuNo ratings yet
- Measures of VariationDocument20 pagesMeasures of VariationArman Benedict NuguidNo ratings yet
- 3 Measures of Central Tendency (Mean, Median)Document32 pages3 Measures of Central Tendency (Mean, Median)Mohamed FathyNo ratings yet
- Describing Data: Centre Mean Is The Technical Term For What Most People Call An Average. in Statistics, "Average"Document4 pagesDescribing Data: Centre Mean Is The Technical Term For What Most People Call An Average. in Statistics, "Average"Shane LambertNo ratings yet
- Topic 3 Measures of DispersionDocument5 pagesTopic 3 Measures of DispersionEll VNo ratings yet
- Lesson A: Measures of Central Tendency: Unit 1: Utilization of Assessment DataDocument24 pagesLesson A: Measures of Central Tendency: Unit 1: Utilization of Assessment DataAnalyn Bintoso DabanNo ratings yet
- Frequency Distribution Table: Measure of Dispersion: Range, Variance, Standard DeviationDocument4 pagesFrequency Distribution Table: Measure of Dispersion: Range, Variance, Standard DeviationJmazingNo ratings yet
- Measures of Central Tendency: Mean, Mode, Median: Soumendra RoyDocument34 pagesMeasures of Central Tendency: Mean, Mode, Median: Soumendra Roybapparoy100% (1)
- ASSIGNMEN4Document15 pagesASSIGNMEN4Harshita Sharma100% (1)
- Measures of Central Tendency and Measures of Dispersion or VariabilityDocument37 pagesMeasures of Central Tendency and Measures of Dispersion or VariabilityHilo MethodNo ratings yet
- Class 5.2 B Business Statistics Measures of DispersionDocument63 pagesClass 5.2 B Business Statistics Measures of DispersionPriya ChughNo ratings yet
- Chapter 4 Statistics and Data Measures of VariationDocument15 pagesChapter 4 Statistics and Data Measures of VariationAteng FordNo ratings yet
- Lesson 6c, 7, 8Document46 pagesLesson 6c, 7, 8Fevee Joy BalberonaNo ratings yet
- Measures of Central TendencyDocument49 pagesMeasures of Central TendencyCecile Cataga BalingcongNo ratings yet
- MMM SD NDDocument41 pagesMMM SD NDEj VillarosaNo ratings yet
- 08 Lecture5 - WhyMeanMattersDocument31 pages08 Lecture5 - WhyMeanMattersLakshmi Priya BNo ratings yet
- Measure of Central TendencyDocument40 pagesMeasure of Central TendencybmNo ratings yet
- Tech Seminar Sem 2Document35 pagesTech Seminar Sem 2Athira SajeevNo ratings yet
- SASA211: Finding The CenterDocument28 pagesSASA211: Finding The CenterMJ LositoNo ratings yet
- Unit 2Document24 pagesUnit 2Mawutor AddatorviNo ratings yet
- Module 6 Lesson 2Document15 pagesModule 6 Lesson 2Jan JanNo ratings yet
- Ubaidullah 783-2019 Business Statistics ReportDocument14 pagesUbaidullah 783-2019 Business Statistics ReportUbaid ArifNo ratings yet
- Chap1 Lesson 2Document10 pagesChap1 Lesson 2Jun PontiverosNo ratings yet
- Statical Data 1Document32 pagesStatical Data 1Irma Estela Marie EstebanNo ratings yet
- Safari - 23-Mar-2019 at 1:49 PMDocument1 pageSafari - 23-Mar-2019 at 1:49 PMRakesh ChoNo ratings yet
- CHAPTER 1 Descriptive StatisticsDocument5 pagesCHAPTER 1 Descriptive StatisticsOana Şi CosminNo ratings yet
- New Lesson 2a - Measure of Central TendencyDocument12 pagesNew Lesson 2a - Measure of Central Tendencyjhean dabatosNo ratings yet
- Chapter 4 Describing Educational Data Libmanan GroupDocument31 pagesChapter 4 Describing Educational Data Libmanan Groupjoy borjaNo ratings yet
- Stat422: Lecture 1 - Part 1Document64 pagesStat422: Lecture 1 - Part 1Azza KassemNo ratings yet
- Lesson 3 Measures of Central TendencyDocument17 pagesLesson 3 Measures of Central TendencypyaplauaanNo ratings yet
- Measures of Central Tendency Arroyo BañezDocument55 pagesMeasures of Central Tendency Arroyo BañezChristian GebañaNo ratings yet
- Definition of Terms 1. StatisticsDocument25 pagesDefinition of Terms 1. StatisticsJane BermoyNo ratings yet
- Definition of Statistics: Solved Example On StatisticsDocument10 pagesDefinition of Statistics: Solved Example On StatisticsMary Grace MoralNo ratings yet
- Mean Median ModeDocument56 pagesMean Median ModeJenneth Cabinto DalisanNo ratings yet
- Central Tendency (Ungrouped)Document8 pagesCentral Tendency (Ungrouped)Arielle T. TanNo ratings yet
- Math StatsDocument6 pagesMath StatsPein MwaNo ratings yet
- Chapter4 StatisticsDocument108 pagesChapter4 Statisticsaymane dibNo ratings yet
- 2.2 Unit-DspDocument63 pages2.2 Unit-Dspsuryashiva422No ratings yet
- Descriptive Statistics IIDocument24 pagesDescriptive Statistics IIJoseDSantosNo ratings yet
- How To Calculate Standard DeviationDocument3 pagesHow To Calculate Standard DeviationAkash TapreNo ratings yet
- How To Calculate Standard DeviationDocument3 pagesHow To Calculate Standard DeviationAkash TapreNo ratings yet
- How To Calculate Standard DeviationDocument3 pagesHow To Calculate Standard DeviationAkash TapreNo ratings yet
- Why Use JavaDocument10 pagesWhy Use JavaErnesto S. Caseres JrNo ratings yet
- Analysis & Interpretation of Statistical Data: Quarter 4, Learning Activity Sheet 5Document29 pagesAnalysis & Interpretation of Statistical Data: Quarter 4, Learning Activity Sheet 5Ernesto S. Caseres JrNo ratings yet
- Analysis & Interpretation of Statistical Data: Quarter 4, Learning Activity Sheet 5Document29 pagesAnalysis & Interpretation of Statistical Data: Quarter 4, Learning Activity Sheet 5Ernesto S. Caseres JrNo ratings yet
- KEY - QUIZ - Simple Interest PDFDocument3 pagesKEY - QUIZ - Simple Interest PDFErnesto S. Caseres JrNo ratings yet
- PowerpointDocument27 pagesPowerpointErnesto S. Caseres JrNo ratings yet
- Simple Interest ComputationDocument12 pagesSimple Interest ComputationErnesto S. Caseres JrNo ratings yet
- What Are The Roles of MIS in The Fields of EducationDocument10 pagesWhat Are The Roles of MIS in The Fields of EducationErnesto S. Caseres JrNo ratings yet
- KEY - QUIZ - Simple InterestDocument3 pagesKEY - QUIZ - Simple InterestErnesto S. Caseres Jr44% (9)
- Job SheetDocument1 pageJob SheetErnesto S. Caseres JrNo ratings yet
- The Lexical Syllabus: by Ana Marie D. CaseresDocument9 pagesThe Lexical Syllabus: by Ana Marie D. CaseresErnesto S. Caseres JrNo ratings yet
- HPLC - FingerprintDocument8 pagesHPLC - FingerprintMukul SuryawanshiNo ratings yet
- Computer Vision Framework For Crack Detection of Civil Infrastructure-A Review - ScienceDirectDocument10 pagesComputer Vision Framework For Crack Detection of Civil Infrastructure-A Review - ScienceDirectHarikrishnaGaddamNo ratings yet
- CHAPTER II-dikonversiDocument19 pagesCHAPTER II-dikonversiMuzlifatulNo ratings yet
- 5 Pe-Pua Rogelia (2018) - Unpackaging The Concept of Loob in Handbook of Filipino Psychology Vol. 1 p.382-394Document17 pages5 Pe-Pua Rogelia (2018) - Unpackaging The Concept of Loob in Handbook of Filipino Psychology Vol. 1 p.382-394kuyainday123No ratings yet
- Teaching Reading: Directed Reading Thinking ActivityDocument12 pagesTeaching Reading: Directed Reading Thinking ActivityElla AustriaNo ratings yet
- Student Guide Writing Reports Prelims Chapter 1Document36 pagesStudent Guide Writing Reports Prelims Chapter 1Diana BengeaNo ratings yet
- Activity 2. Search On This Activity 3. THINK OF THISDocument3 pagesActivity 2. Search On This Activity 3. THINK OF THISpayno gelacioNo ratings yet
- Rural Marketing Ppt-2Document44 pagesRural Marketing Ppt-2maddy161No ratings yet
- Group 2 Exploring The Lived Experience of Grade 11 TVL Automotive Students in TDocument8 pagesGroup 2 Exploring The Lived Experience of Grade 11 TVL Automotive Students in Tgerdcat300No ratings yet
- SP 13 1 Part1 SolutionDocument6 pagesSP 13 1 Part1 SolutionRavinder SinghNo ratings yet
- Marketing As Science PDFDocument31 pagesMarketing As Science PDFtongamuliNo ratings yet
- Lab ReportDocument10 pagesLab ReportCercel Ana MariaNo ratings yet
- Social Phobia in Higher Education: The in Uence of Nomophobia On Social PhobiaDocument9 pagesSocial Phobia in Higher Education: The in Uence of Nomophobia On Social PhobiaLiaNo ratings yet
- Mark Rec103Document6 pagesMark Rec103RadMollyNo ratings yet
- Practical Research 2: Quarter 2, LAS 2 Sampling TechniquesDocument10 pagesPractical Research 2: Quarter 2, LAS 2 Sampling TechniquesHannah Bianca RegullanoNo ratings yet
- Ebook Business Case For AnalyticsDocument18 pagesEbook Business Case For AnalyticsDavid FatemanNo ratings yet
- 123CSR) ProjectDocument62 pages123CSR) ProjectDivyeshNo ratings yet
- The Role of Dissonance Reduction and Co-Creation Strategies in Shaping Smart Service SatisfaDocument21 pagesThe Role of Dissonance Reduction and Co-Creation Strategies in Shaping Smart Service SatisfaMarshal SamuelNo ratings yet
- 2019 Proefschrift Sanne Verdoorn Clinical Medication Review PDFDocument234 pages2019 Proefschrift Sanne Verdoorn Clinical Medication Review PDFSerdarNo ratings yet
- SIP - Kit PGDM Batch 2020-22Document33 pagesSIP - Kit PGDM Batch 2020-22Anmole AryaNo ratings yet
- Determining The Business Information Systems StrategyDocument41 pagesDetermining The Business Information Systems StrategyasfrnfaridNo ratings yet
- Annotated Bibliography 1Document5 pagesAnnotated Bibliography 1api-548519539No ratings yet
- Aone ResearchDocument41 pagesAone ResearchThato MathogojaneNo ratings yet
- Principles of Management Course Outline (Fall 2020) Instructor: Dr. Amna Niazi Course ObjectiveDocument2 pagesPrinciples of Management Course Outline (Fall 2020) Instructor: Dr. Amna Niazi Course Objectivefaraherh amberNo ratings yet
- Skittles ReportDocument5 pagesSkittles Reportapi-242736484No ratings yet