You might also like
- ENGR AE 6 CircuitAnalysisAndTroubleshootingPowerPointDocument18 pagesENGR AE 6 CircuitAnalysisAndTroubleshootingPowerPointMarvs SD RojsvelNo ratings yet
- Tools Pack List ElectrikDocument9 pagesTools Pack List ElectrikHr DaniNo ratings yet
- Column Design - Staad ReactionsDocument12 pagesColumn Design - Staad ReactionsNitesh SinghNo ratings yet
- Practical Data Acquisition for Instrumentation and Control SystemsFrom EverandPractical Data Acquisition for Instrumentation and Control SystemsNo ratings yet
- Programmable Logic ControllerDocument79 pagesProgrammable Logic ControllerDrPraveen KumarNo ratings yet
- 08 GULN ZXRAN Base Station TroubleshootingDocument39 pages08 GULN ZXRAN Base Station Troubleshootinga2227 jglNo ratings yet
- PLC - Sies PDFDocument116 pagesPLC - Sies PDFABHISHEK THAKURNo ratings yet
- CCIE RNS v5 - Configuration - Question - Lab 1.1 - Final Release - 01-Jul-2018Document33 pagesCCIE RNS v5 - Configuration - Question - Lab 1.1 - Final Release - 01-Jul-2018blck bxNo ratings yet
- Easy Soft ManualDocument117 pagesEasy Soft ManualroscovanulNo ratings yet
- Summer Training ReportDocument45 pagesSummer Training ReportPracheer SinghNo ratings yet
- BS 4999-143-1987 Requirements For Rotating Electrical MachinDocument8 pagesBS 4999-143-1987 Requirements For Rotating Electrical MachinJames AlejoNo ratings yet
- True Launch Assurance Training - Call Drop Issue Troubleshooting V1.0Document29 pagesTrue Launch Assurance Training - Call Drop Issue Troubleshooting V1.09494772774No ratings yet
- 1 MSOFTX3000 (ATCA) Hardware SystemDocument53 pages1 MSOFTX3000 (ATCA) Hardware Systemgunner04100% (4)
- CloudEngine 12800 Quick Maintenance GuideDocument15 pagesCloudEngine 12800 Quick Maintenance GuideriyasathsafranNo ratings yet
- Cispr18-2 (Ed2 0) enDocument76 pagesCispr18-2 (Ed2 0) enSajjad PirzadaNo ratings yet
- Node B - Alarms TroubleshootingDocument23 pagesNode B - Alarms TroubleshootinghassanNo ratings yet
- Guide To Perform Initial DT With GENEX ProbeDocument19 pagesGuide To Perform Initial DT With GENEX Probewantwant56750% (2)
- OSPF LabsDocument83 pagesOSPF LabsGulsah BulanNo ratings yet
- E1 Traffic RoutingDocument75 pagesE1 Traffic RoutingWidimongar W. JarqueNo ratings yet
- LTE ENodeB Initial Config Integration GuideDocument77 pagesLTE ENodeB Initial Config Integration GuideSteadRed100% (10)
- Routing Over Ericsson Mini-LinkDocument45 pagesRouting Over Ericsson Mini-LinkCalvinho100% (2)
- 10.alarm Handling of ZTE B8018 BtsDocument45 pages10.alarm Handling of ZTE B8018 BtsYadav Mahesh100% (2)
- L1 Troubleshooting GuideDocument18 pagesL1 Troubleshooting GuidePetyo GeorgievNo ratings yet
- Health CheckDocument13 pagesHealth CheckJocoleNo ratings yet
- OptiX WDM System Troubleshooting ISSUE1.0Document75 pagesOptiX WDM System Troubleshooting ISSUE1.0SeifEldinADel50% (2)
- GPON TroubleshootingDocument16 pagesGPON TroubleshootingAr RasidNo ratings yet
- 2 BSC RNC 6900 Hardware Structure and System Description 2Document33 pages2 BSC RNC 6900 Hardware Structure and System Description 2kamalNo ratings yet
- Industrial RF (Radio Frequency) Control: For Use With Model 8394053 SPIT-FIRE® MonitorDocument11 pagesIndustrial RF (Radio Frequency) Control: For Use With Model 8394053 SPIT-FIRE® MonitortawfeeqsylanNo ratings yet
- Lecture 4Document34 pagesLecture 4KelvinNo ratings yet
- Guide Manual: Analogue Fire Detection Control Panels Installation GuideDocument96 pagesGuide Manual: Analogue Fire Detection Control Panels Installation GuideMilorad PantelinacNo ratings yet
- JRC ErrorcodeDocument98 pagesJRC ErrorcodeNguyen Minh Giap100% (1)
- S7-300 PLC in RTG NEW V1.0Document42 pagesS7-300 PLC in RTG NEW V1.0Dinh SangNo ratings yet
- RNC PresentationDocument16 pagesRNC Presentationrico6No ratings yet
- Unit 4Document51 pagesUnit 4Vyshnavi Challa ObullaNo ratings yet
- CCNA Exploration 3 LAN SwitchingDocument9 pagesCCNA Exploration 3 LAN SwitchingSozana ArtherNo ratings yet
- GERAN-B-EN-ZXG10 B8018 Troubleshooting-1-PPT-201010Document27 pagesGERAN-B-EN-ZXG10 B8018 Troubleshooting-1-PPT-201010aslam_326580186No ratings yet
- Electronic Emission Notices: Federal Communications Commission (FCC) StatementDocument16 pagesElectronic Emission Notices: Federal Communications Commission (FCC) StatementfostechNo ratings yet
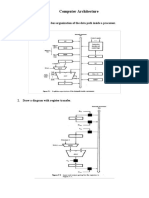
- Computer Architecture: 1. Draw A Diagram Single Bus Organization of The Data Path Inside A ProcessorDocument8 pagesComputer Architecture: 1. Draw A Diagram Single Bus Organization of The Data Path Inside A Processormd sayemNo ratings yet
- CCNA - 3 Final Exam LAN Switching and WirelessDocument13 pagesCCNA - 3 Final Exam LAN Switching and Wirelessgumbee2012No ratings yet
- Section (4B) - SCS PDFDocument17 pagesSection (4B) - SCS PDFMohamed Ben mahmoudNo ratings yet
- 07 - Input OutputDocument22 pages07 - Input OutputSadiholicNo ratings yet
- Polaroid LCD FLM1511Document30 pagesPolaroid LCD FLM1511videosonNo ratings yet
- Cxc-2000pvr Service ManualDocument63 pagesCxc-2000pvr Service ManualGoran StojkovicNo ratings yet
- Node B Troubleshooting V100R007Document30 pagesNode B Troubleshooting V100R007Bala KathirNo ratings yet
- Circuit Analysis and Troubleshooting PowerpointDocument6 pagesCircuit Analysis and Troubleshooting PowerpointAzmeer ReemzaNo ratings yet
- 3rdsessional 2019Document97 pages3rdsessional 2019Utsav VedantNo ratings yet
- GBPPR 'Zine - Issue #3Document61 pagesGBPPR 'Zine - Issue #3GBPPRNo ratings yet
- PLC - PresDocument30 pagesPLC - PresSandeep Yadav100% (1)
- UNIT-5: I/O SystemsDocument24 pagesUNIT-5: I/O SystemsKapil NagwanshiNo ratings yet
- Routing Over Ericsson Mini-Link: Presented By: Eng Ahmed Mohammed Nabieh Supervised By: Eng Amr AbdelkreemDocument45 pagesRouting Over Ericsson Mini-Link: Presented By: Eng Ahmed Mohammed Nabieh Supervised By: Eng Amr AbdelkreemRupesh PatelNo ratings yet
- Status Refresh: - INV002 - Refresh: INV 002 Basic Function SymbolDocument10 pagesStatus Refresh: - INV002 - Refresh: INV 002 Basic Function SymbolJosephNo ratings yet
- Jiuzhou dtt1609 Service Manual PDFDocument44 pagesJiuzhou dtt1609 Service Manual PDFVishu JoshiNo ratings yet
- Lec 8Document17 pagesLec 8deemo1354210No ratings yet
- Ocb 283Document27 pagesOcb 283Roni SharmaNo ratings yet
- Listado de Manuales para CJ PDFDocument1 pageListado de Manuales para CJ PDFSergio Eu CaNo ratings yet
- Ps4-200 Hardware h1184gDocument94 pagesPs4-200 Hardware h1184gEmmanuel PatryNo ratings yet
- 2G Alarm Training MaterialDocument26 pages2G Alarm Training MaterialAhmed SharafNo ratings yet
- 07 - WLAN Product Troubleshooting and Management - IIIDocument49 pages07 - WLAN Product Troubleshooting and Management - IIIXanNo ratings yet
- Optix NG WDM Maintenance Case Collection PDFDocument10 pagesOptix NG WDM Maintenance Case Collection PDFtelec10No ratings yet
- Vacon NXS 3 Speed Positioning ASFIFF15 ApplicationDocument81 pagesVacon NXS 3 Speed Positioning ASFIFF15 ApplicationTanuTiganuNo ratings yet
- MPS - Ch10 - AVR - Interrupt Programming in Assembly and CDocument83 pagesMPS - Ch10 - AVR - Interrupt Programming in Assembly and CPhương Nghi LiênNo ratings yet
- Content: - Introduction To Pipeline Hazard - Structural Hazard - Data Hazard - Control HazardDocument27 pagesContent: - Introduction To Pipeline Hazard - Structural Hazard - Data Hazard - Control HazardAhmed NabilNo ratings yet
- VMC Advance 1 Paper 1Document11 pagesVMC Advance 1 Paper 1amogh kumarNo ratings yet
- 1448 Data Gmet6 25eph Pfep191022 Forktruck 191024Document227 pages1448 Data Gmet6 25eph Pfep191022 Forktruck 191024Gustavo FerrerNo ratings yet
- Effect of Rim Seal On Evaporation Loss From Khark Island Storage Tanks 2157 7463 1 103 PDFDocument7 pagesEffect of Rim Seal On Evaporation Loss From Khark Island Storage Tanks 2157 7463 1 103 PDFHuynh Thanh TamNo ratings yet
- Technical CataloguelDocument20 pagesTechnical CataloguelNgoc Vũ TrầnNo ratings yet
- Vedic Maths 1Document5 pagesVedic Maths 1Ajmal AshrafNo ratings yet
- Vector Worksheet 10 AnsDocument13 pagesVector Worksheet 10 AnsMegan GohNo ratings yet
- Image MIDlet GuideDocument26 pagesImage MIDlet GuideNivedita MittalNo ratings yet
- Optimization of Material Handling Trolley Using Finite Element AnalysisDocument13 pagesOptimization of Material Handling Trolley Using Finite Element AnalysisRumah WayangNo ratings yet
- Arranging Fractions Lesson PlanDocument5 pagesArranging Fractions Lesson PlanSusan TalusigNo ratings yet
- Ignition Systems: Igor Porfírio Nº1020361Document14 pagesIgnition Systems: Igor Porfírio Nº1020361Aashik AashikNo ratings yet
- Figure 7-11 Inter-VLAN Routing Example1Document10 pagesFigure 7-11 Inter-VLAN Routing Example1GoodsonNo ratings yet
- Descartes' Rule of SignsDocument21 pagesDescartes' Rule of SignsChona ZamoraNo ratings yet
- Fake ReviewDocument6 pagesFake ReviewHarshal PimpalshendeNo ratings yet
- 106802-2727 Ijet-IjensDocument8 pages106802-2727 Ijet-IjensPrabakaran SubramaniamNo ratings yet
- Worksheet On Carboxylic AcidsDocument3 pagesWorksheet On Carboxylic AcidsmalisnotokNo ratings yet
- Archmodels 06Document5 pagesArchmodels 06JEAN CARLO LARA PEREZNo ratings yet
- X Physics WorksheetDocument2 pagesX Physics WorksheetHima ShettyNo ratings yet
- What Is Dynamometer ?Document28 pagesWhat Is Dynamometer ?Harpreet RandhawaNo ratings yet
- Projectile Motion Lab ReportDocument6 pagesProjectile Motion Lab ReportThu Phuong LeNo ratings yet
- PVGIS-5 GridConnectedPV 46.047 14.545 Undefined Crystsi 0.6kWp 15 90deg 0deg-1Document1 pagePVGIS-5 GridConnectedPV 46.047 14.545 Undefined Crystsi 0.6kWp 15 90deg 0deg-1FinanceNo ratings yet
- Compilation of EPA's Sampling and Analysis MethodsDocument214 pagesCompilation of EPA's Sampling and Analysis Methodspiero astiNo ratings yet
- Gozak - LeonidovDocument14 pagesGozak - LeonidovMartí ARNo ratings yet
- User Manual Smart-UPS Src5Kuxi/Srce6Kuxi Tower/Rack-Mount 3U 220/230/240 VacDocument36 pagesUser Manual Smart-UPS Src5Kuxi/Srce6Kuxi Tower/Rack-Mount 3U 220/230/240 VacLakshmanan SethupathiNo ratings yet
- Shreya Sharma ReportDocument62 pagesShreya Sharma ReportshreyakesharwaniaryabhataNo ratings yet