You might also like
- Bdhs - EbookDocument970 pagesBdhs - Ebookkrishna vamsiNo ratings yet
- COMP9313: Big Data Management: Course Web Site: HTTP://WWW - Cse.unsw - Edu.au/ cs9313Document76 pagesCOMP9313: Big Data Management: Course Web Site: HTTP://WWW - Cse.unsw - Edu.au/ cs9313maithuong85No ratings yet
- Big DataDocument4 pagesBig Dataaryan kothambiaNo ratings yet
- JNTU ANANTAPUR BIG DATA ANALYTICS SYLLABUSDocument24 pagesJNTU ANANTAPUR BIG DATA ANALYTICS SYLLABUSAishwarya RayasamNo ratings yet
- CIT-650 Introduction To Big Data, Developing With Spark and HadoopDocument4 pagesCIT-650 Introduction To Big Data, Developing With Spark and HadoopAmgad AlsisiNo ratings yet
- 17ci18 - Big Data AnalyticsDocument2 pages17ci18 - Big Data Analyticsviju001No ratings yet
- Zero Lecture: Big Data Analytics Lab BCA04206 From: Megha GargDocument19 pagesZero Lecture: Big Data Analytics Lab BCA04206 From: Megha GargMegha GargNo ratings yet
- CC ZG522 Course HandoutDocument6 pagesCC ZG522 Course Handout2023mt03587No ratings yet
- BUDT 758B Big Data - Syllabus-2016 - Gao & Gopal - 0Document4 pagesBUDT 758B Big Data - Syllabus-2016 - Gao & Gopal - 0pooh06No ratings yet
- Big Data Analytics SyllabusDocument2 pagesBig Data Analytics SyllabusSaiyed Faiayaz WarisNo ratings yet
- Outline 2017Document15 pagesOutline 2017Gladys Gladys MakNo ratings yet
- Big Data Management SyllabusDocument5 pagesBig Data Management SyllabusANOOPATICS YNo ratings yet
- Samsung Innovation Campus Big Data Course DesignDocument5 pagesSamsung Innovation Campus Big Data Course DesignDaniel GarcésNo ratings yet
- 2cse506 Big Data AnalyticsDocument1 page2cse506 Big Data AnalyticsAswin NairNo ratings yet
- Big Data Analysis Using Apache Spark MLlibDocument9 pagesBig Data Analysis Using Apache Spark MLlibalvarolucasNo ratings yet
- Introduction To Hadoop & SparkDocument28 pagesIntroduction To Hadoop & SparkJustin TalbotNo ratings yet
- Big Data With Hadoop & Spark - IntroductionDocument28 pagesBig Data With Hadoop & Spark - IntroductionPremjit SenguptaNo ratings yet
- Big Data Storge ManagementDocument4 pagesBig Data Storge ManagementV Harsha ShastriNo ratings yet
- 4-2 Bda PPTSDocument114 pages4-2 Bda PPTSLOKESWARI GNo ratings yet
- BigData Course Curriculum (Gyan Plus)Document5 pagesBigData Course Curriculum (Gyan Plus)Aakriti GoyalNo ratings yet
- CS 498: Cloud Computing Applications Syllabus: Course DescriptionDocument8 pagesCS 498: Cloud Computing Applications Syllabus: Course DescriptionGokul KrishnamoorthyNo ratings yet
- Understanding Big Data Concepts and TechnologiesDocument4 pagesUnderstanding Big Data Concepts and Technologieschetana tukkojiNo ratings yet
- hadoopDocument14 pageshadoopsrcesrbije.onlineNo ratings yet
- Unit -I Introduction to Big DataDocument38 pagesUnit -I Introduction to Big Datapraneelp2000No ratings yet
- Research Paper On HadoopDocument5 pagesResearch Paper On Hadoopwlyxiqrhf100% (1)
- Elearning Course CurriculumDocument9 pagesElearning Course CurriculumMaheshwarNo ratings yet
- Hadoop Architecture and its Functionality ExplainedDocument7 pagesHadoop Architecture and its Functionality ExplainedJohnNo ratings yet
- Mca Big Data PDF Sem 3Document193 pagesMca Big Data PDF Sem 3Rohan JadhavNo ratings yet
- BIG DATA & Hadoop Interview Questions With AnswersDocument9 pagesBIG DATA & Hadoop Interview Questions With AnswersMikky JamesNo ratings yet
- Big Data HadoopDocument13 pagesBig Data HadoopLakshmi Prasanna KalahastriNo ratings yet
- Teaching Big Data TechnologiesDocument8 pagesTeaching Big Data Technologiessrinivasa helwarNo ratings yet
- RV College of Engineering: Big Data Analytics 16CS7F1 Prof - Mamatha TDocument64 pagesRV College of Engineering: Big Data Analytics 16CS7F1 Prof - Mamatha TtesterNo ratings yet
- Symbiosis Skills and Professional UniversityDocument3 pagesSymbiosis Skills and Professional UniversityAakash TiwariNo ratings yet
- Hadoop Release 2.0Document54 pagesHadoop Release 2.0Prashant SharmaNo ratings yet
- Lecture 1Document17 pagesLecture 1Sana MehmoodNo ratings yet
- IIT Kharagpur Data Science PDFDocument22 pagesIIT Kharagpur Data Science PDFRintu DeyNo ratings yet
- Big Data With Hadoop & Spark - IntroductionDocument42 pagesBig Data With Hadoop & Spark - IntroductionCit AssocDean RosarioNo ratings yet
- Gujarat Technological UniversityDocument8 pagesGujarat Technological UniversityuditNo ratings yet
- Hadoop N Lechure NotesDocument82 pagesHadoop N Lechure NotessaikrishnaNo ratings yet
- Big Data Analytics Comp Syllabus Sem7Document4 pagesBig Data Analytics Comp Syllabus Sem7Saprativa BhattacharjeeNo ratings yet
- Data Science and Big Data by IBM CE Allsoft Summer Training Final ReportDocument41 pagesData Science and Big Data by IBM CE Allsoft Summer Training Final Reportjohn pradeep100% (1)
- Big Data AnalyticsDocument3 pagesBig Data Analyticstirth_diwaniNo ratings yet
- Introduction to Big Data Analytics: Managing and Extracting Value from Large DatasetsDocument114 pagesIntroduction to Big Data Analytics: Managing and Extracting Value from Large Datasetsreenadh shaikNo ratings yet
- Syllabus E63 2018 Fall PDFDocument3 pagesSyllabus E63 2018 Fall PDFvinceRedNo ratings yet
- Data Warehouse On Hadoop Platform For Processing of Big Educational DataDocument4 pagesData Warehouse On Hadoop Platform For Processing of Big Educational DataPiyuSh AngRaNo ratings yet
- Research Paper On Big Data HadoopDocument5 pagesResearch Paper On Big Data Hadoopt1tos1z0t1d2100% (1)
- Pemanfaatan Big Data Dalam Riset 2023Document47 pagesPemanfaatan Big Data Dalam Riset 2023Nandha RahmasariNo ratings yet
- Artigo PingER SLACDocument7 pagesArtigo PingER SLACLeandro JustinoNo ratings yet
- AIADS 7th Sem Syllabus SignedDocument19 pagesAIADS 7th Sem Syllabus Signedhimanshu24ai018No ratings yet
- Training For Bigdata and Hadoop: #I Background and IntroductionDocument9 pagesTraining For Bigdata and Hadoop: #I Background and IntroductionRashtra BhushanNo ratings yet
- 113 Ce 74Document4 pages113 Ce 74boremshiva1201No ratings yet
- Gag PDFDocument15 pagesGag PDFGagan DhaliwalNo ratings yet
- Big Data Hadoop Certification Training GuideDocument40 pagesBig Data Hadoop Certification Training GuideAnims DccNo ratings yet
- Bigdata SyllabusDocument3 pagesBigdata SyllabusSankar TerliNo ratings yet
- A Comparative Study On Apache Spark and Map Reduce With Performance Analysis Using KNN and Page Rank AlgorithmDocument6 pagesA Comparative Study On Apache Spark and Map Reduce With Performance Analysis Using KNN and Page Rank AlgorithmEditor IJTSRDNo ratings yet
- CE441: Big Data Analytics Course OverviewDocument4 pagesCE441: Big Data Analytics Course Overviewpoojan thakkarNo ratings yet
- Day1 2Document110 pagesDay1 2patil_555No ratings yet
- 01 Unit-I Introduction To Big DataDocument11 pages01 Unit-I Introduction To Big DataKumarAdabalaNo ratings yet
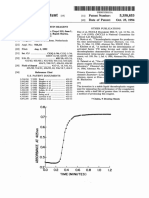
- Absorbance at 405Nm: United States PatentDocument20 pagesAbsorbance at 405Nm: United States Patentfelipe_fismed4429No ratings yet
- TP 6799Document84 pagesTP 6799Roberto Sanchez Zapata100% (1)
- A Teacher Education ModelDocument128 pagesA Teacher Education ModelMelinda LabianoNo ratings yet
- Slimline F96T12 DX Alto: Product Family Description T12 Single Pin Linear Fluorescent LampsDocument2 pagesSlimline F96T12 DX Alto: Product Family Description T12 Single Pin Linear Fluorescent LampsJon GosnellNo ratings yet
- DENR CC 2022 1st - Edition FIN 25 - March - 2022Document234 pagesDENR CC 2022 1st - Edition FIN 25 - March - 2022CENRO BANGUED PLANNINGNo ratings yet
- Pantangco DigestDocument2 pagesPantangco DigestChristine ZaldivarNo ratings yet
- DataSheet ULCAB300Document2 pagesDataSheet ULCAB300Yuri OliveiraNo ratings yet
- Joysticks For Hoist & Crane Control SystemsDocument5 pagesJoysticks For Hoist & Crane Control SystemsRunnTechNo ratings yet
- Engg Maths Sem 3 Curve FittingDocument13 pagesEngg Maths Sem 3 Curve FittingRonak Raju ParmarNo ratings yet
- Lab Manual 2 PrintDocument17 pagesLab Manual 2 Printmonikandakumar ramachandranNo ratings yet
- Altracs: A Superior Thread-Former For Light AlloysDocument8 pagesAltracs: A Superior Thread-Former For Light AlloysSquidwardNo ratings yet
- The Beatles Album Back CoverDocument1 pageThe Beatles Album Back CoverSophia AvraamNo ratings yet
- DAA UNIT-3 (Updated)Document33 pagesDAA UNIT-3 (Updated)pilli maheshchandraNo ratings yet
- United States v. Bueno-Hernandez, 10th Cir. (2012)Document3 pagesUnited States v. Bueno-Hernandez, 10th Cir. (2012)Scribd Government DocsNo ratings yet
- One SheetDocument1 pageOne Sheetadeel ghouseNo ratings yet
- Macalintal v. PETDocument5 pagesMacalintal v. PETJazem AnsamaNo ratings yet
- 4 - ASR9K XR Intro Routing and RPL PDFDocument42 pages4 - ASR9K XR Intro Routing and RPL PDFhem777No ratings yet
- Detection of Malicious Web Contents Using Machine and Deep Learning ApproachesDocument6 pagesDetection of Malicious Web Contents Using Machine and Deep Learning ApproachesInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Delphi28236381 20190611 112907Document2 pagesDelphi28236381 20190611 112907คุณชายธวัชชัย เจริญสุขNo ratings yet
- IsotopesDocument35 pagesIsotopesAddisu Amare Zena 18BML0104No ratings yet
- Oatey2021 CommercialCat LCS1146B 022421 WEB LR 1Document204 pagesOatey2021 CommercialCat LCS1146B 022421 WEB LR 1Pablo CINo ratings yet
- CHEM F313: Instrumental Methods of AnalysisDocument12 pagesCHEM F313: Instrumental Methods of AnalysisAYUSH SHARMANo ratings yet
- Lab Exercise 3 SoilScie Group4Document10 pagesLab Exercise 3 SoilScie Group4Jhunard Christian O. AsayasNo ratings yet
- Chapter 4 Earth WorkDocument39 pagesChapter 4 Earth WorkYitbarek BayieseNo ratings yet
- Application For Transmission of Shares / DebenturesDocument2 pagesApplication For Transmission of Shares / DebenturesCS VIJAY THAKURNo ratings yet
- MP Process Flow - MBA - MM - MHRMDocument2 pagesMP Process Flow - MBA - MM - MHRMKAVITHA A/P PARIMAL MoeNo ratings yet
- Ari Globe Valve SupraDocument26 pagesAri Globe Valve SupraAi-samaNo ratings yet
- 266DSH Differential Pressure TransmittersDocument36 pages266DSH Differential Pressure TransmittersSibabrata ChoudhuryNo ratings yet
- Odoo JS Framework Rewrite Brings New Views and TestingDocument68 pagesOdoo JS Framework Rewrite Brings New Views and TestingglobalknowledgeNo ratings yet
- Pangilinan, Zobel de Ayala, Sy Sr., Dangote, Rupert, Jameel - Power and influence of business leaders in Asia and AfricaDocument20 pagesPangilinan, Zobel de Ayala, Sy Sr., Dangote, Rupert, Jameel - Power and influence of business leaders in Asia and AfricaGwenNo ratings yet