You might also like
- Radial Basis Networks: Fundamentals and Applications for The Activation Functions of Artificial Neural NetworksFrom EverandRadial Basis Networks: Fundamentals and Applications for The Activation Functions of Artificial Neural NetworksNo ratings yet
- Dimensionality Reduction: Principal Component Analysis and SVDDocument16 pagesDimensionality Reduction: Principal Component Analysis and SVDRajachandra VoodigaNo ratings yet
- Lecture 12 - Probabilistic ML (4) - MAP Estimation and Bayesian Inference - PlainDocument15 pagesLecture 12 - Probabilistic ML (4) - MAP Estimation and Bayesian Inference - PlainRajachandra VoodigaNo ratings yet
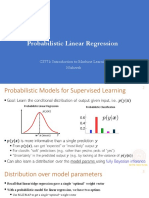
- Probabilistic Linear Regression: CS771: Introduction To Machine Learning NisheethDocument18 pagesProbabilistic Linear Regression: CS771: Introduction To Machine Learning NisheethRajaNo ratings yet
- Logistic and Softmax Regression: CS771: Introduction To Machine Learning NisheethDocument15 pagesLogistic and Softmax Regression: CS771: Introduction To Machine Learning NisheethRajaNo ratings yet
- Lecture 17 and 18Document29 pagesLecture 17 and 18shivna0809No ratings yet
- Perceptrons and SVMS: Cs771: Introduction To Machine Learning NisheethDocument18 pagesPerceptrons and SVMS: Cs771: Introduction To Machine Learning NisheethRajaNo ratings yet
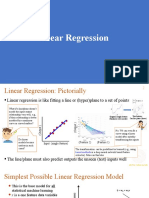
- Linear Regression: CS771: Introduction To Machine Learning NisheethDocument14 pagesLinear Regression: CS771: Introduction To Machine Learning NisheethRajaNo ratings yet
- Lecture 19 and 20Document27 pagesLecture 19 and 20shivna0809No ratings yet
- Linear RegressionDocument14 pagesLinear RegressionALINA SOYNo ratings yet
- Arima: Model Building BlocksDocument14 pagesArima: Model Building BlocksAniruddha GangopadhyayNo ratings yet
- Dimensionality Reduction (Contd) : CS771: Introduction To Machine Learning Piyush RaiDocument17 pagesDimensionality Reduction (Contd) : CS771: Introduction To Machine Learning Piyush RaiRajachandra VoodigaNo ratings yet
- Lecture 16 - Hyperplane Classifiers - Perceptron - PlainDocument9 pagesLecture 16 - Hyperplane Classifiers - Perceptron - PlainRajachandra VoodigaNo ratings yet
- Scikit Learn Org Stable Modules Kernel - Approximation HTMLDocument3 pagesScikit Learn Org Stable Modules Kernel - Approximation HTMLhatakekakashinrt2033No ratings yet
- Machine Learning Quick Start GuideDocument1 pageMachine Learning Quick Start GuideHammad RiazNo ratings yet
- Data Clustering (Contd) : CS771: Introduction To Machine Learning Piyush RaiDocument15 pagesData Clustering (Contd) : CS771: Introduction To Machine Learning Piyush RaiRajachandra VoodigaNo ratings yet
- 5634 Convolutional Neural Networks With Intra Layer Recurrent Connections For Scene LabelingDocument9 pages5634 Convolutional Neural Networks With Intra Layer Recurrent Connections For Scene LabelingheavywaterNo ratings yet
- Matrix Principal Component Analysis For Image Compression and RecognitionDocument6 pagesMatrix Principal Component Analysis For Image Compression and RecognitionSaetaNo ratings yet
- On Application of Omp and Cosamp Algorithms For Doa Estimation ProblemDocument5 pagesOn Application of Omp and Cosamp Algorithms For Doa Estimation ProblemehsanNo ratings yet
- Continuous OptimizationDocument23 pagesContinuous OptimizationPrashant JindalNo ratings yet
- Lecture 27 - Latent Variable Models (2) - P1 - PlainDocument11 pagesLecture 27 - Latent Variable Models (2) - P1 - PlainRajachandra VoodigaNo ratings yet
- 771 A18 Lec7Document120 pages771 A18 Lec7DUDEKULA VIDYASAGARNo ratings yet
- Learning Algebraic Multigrid Using Graph Neural NetworksDocument11 pagesLearning Algebraic Multigrid Using Graph Neural NetworksAman JalanNo ratings yet
- Lecture 09 - Calculus and Optimization Techniques (3) - PlainDocument15 pagesLecture 09 - Calculus and Optimization Techniques (3) - PlainRajaNo ratings yet
- CS771: Introduction To Machine Learning Piyush RaiDocument25 pagesCS771: Introduction To Machine Learning Piyush RaiRajachandra VoodigaNo ratings yet
- Lecture 28 - Latent Variable Models (2) - P2 - PlainDocument8 pagesLecture 28 - Latent Variable Models (2) - P2 - PlainRajachandra VoodigaNo ratings yet
- Multispectral Image Classification of Shaded and Non-Shaded Land-Cover PatternsDocument10 pagesMultispectral Image Classification of Shaded and Non-Shaded Land-Cover PatternsWanessa da SilvaNo ratings yet
- CS772 Lec10Document23 pagesCS772 Lec10juggernautjhaNo ratings yet
- Pre ImageDocument9 pagesPre ImageJIJINo ratings yet
- 771 A18 Lec15Document96 pages771 A18 Lec15DUDEKULA VIDYASAGARNo ratings yet
- Lecture 19 - Nonlinear Learning With Kernels (1) - PlainDocument15 pagesLecture 19 - Nonlinear Learning With Kernels (1) - PlainRajachandra VoodigaNo ratings yet
- Lecture 07 - Linear Regression - PlainDocument12 pagesLecture 07 - Linear Regression - PlainRajachandra VoodigaNo ratings yet
- Authorized Licensed Use Limited To: Shanghaitech University. Downloaded On December 04,2022 at 07:33:32 Utc From Ieee Xplore. Restrictions ApplyDocument2 pagesAuthorized Licensed Use Limited To: Shanghaitech University. Downloaded On December 04,2022 at 07:33:32 Utc From Ieee Xplore. Restrictions ApplyzywNo ratings yet
- Deep Learning QPDocument4 pagesDeep Learning QPGowri IlayarajaNo ratings yet
- GyuyuDocument11 pagesGyuyushivna0809No ratings yet
- NeuralProphet IntroductionDocument43 pagesNeuralProphet IntroductionSam TitusNo ratings yet
- Lecture 13 - Probabilistic Linear Regression - PlainDocument19 pagesLecture 13 - Probabilistic Linear Regression - PlainRajachandra VoodigaNo ratings yet
- Lecture 10 - Probabilistic ML (1) - Basics of Probability - PlainDocument12 pagesLecture 10 - Probabilistic ML (1) - Basics of Probability - PlainRajaNo ratings yet
- CAPL 3 CANNewsletter 201411 PressArticle enDocument2 pagesCAPL 3 CANNewsletter 201411 PressArticle endaourdiopNo ratings yet
- An Adaptation of The AAA-Interpolation Algorithm For Model Reduction of MIMO SystemsDocument7 pagesAn Adaptation of The AAA-Interpolation Algorithm For Model Reduction of MIMO SystemssdfasddfasdfasfdsafNo ratings yet
- A New Adaptive Algorithm For Joint Blind Equalization and Carrier RecoveryDocument5 pagesA New Adaptive Algorithm For Joint Blind Equalization and Carrier RecoveryShafayat AbrarNo ratings yet
- Online Network: G-CNN EncoderDocument1 pageOnline Network: G-CNN EncoderTedNo ratings yet
- Lecture 10 - Optimization Techniques (4) - PlainDocument6 pagesLecture 10 - Optimization Techniques (4) - PlainRajaNo ratings yet
- 4-14 - p18 - Tips-And-Tricks-For-The-Use-Of-Capl-Part 3 - Lobmeyer - MarktlDocument4 pages4-14 - p18 - Tips-And-Tricks-For-The-Use-Of-Capl-Part 3 - Lobmeyer - MarktlMohammad FaizanNo ratings yet
- Scikit-Learn: Library For Machine Learning and Data Science With PythonDocument11 pagesScikit-Learn: Library For Machine Learning and Data Science With PythonAmber Joy TingeyNo ratings yet
- ME233 Sp16 L19 Least Squares Parameter EstimationDocument49 pagesME233 Sp16 L19 Least Squares Parameter EstimationOmar Zeb KhanNo ratings yet
- 771 A18 Lec10Document164 pages771 A18 Lec10DUDEKULA VIDYASAGARNo ratings yet
- Skill DS. MLDocument5 pagesSkill DS. MLFahmi FathonyNo ratings yet
- The Unscented Kalman Filter For Nonlinear EstimationDocument6 pagesThe Unscented Kalman Filter For Nonlinear Estimationrouf johnNo ratings yet
- RNN Structure PDFDocument1 pageRNN Structure PDFVancho PecovskiNo ratings yet
- Practical CryptographyDocument4 pagesPractical CryptographyStefan CroitoruNo ratings yet
- Peak To Average Power Reduction Using Amplitude and Sign AdjustmentDocument5 pagesPeak To Average Power Reduction Using Amplitude and Sign AdjustmentHarshali ManeNo ratings yet
- Implementing A Randomized SVD Algorithm and Its Performance AnalysisDocument7 pagesImplementing A Randomized SVD Algorithm and Its Performance AnalysisInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- EM Algorithms For PCA and SPCADocument7 pagesEM Algorithms For PCA and SPCAMohamad NasrNo ratings yet
- Machine Learning Cheat SheetDocument1 pageMachine Learning Cheat SheetAntony FelixNo ratings yet
- Sparse Identification of Polynomial Models and Its Application To Nonlinear MPC ?Document6 pagesSparse Identification of Polynomial Models and Its Application To Nonlinear MPC ?Andres HernandezNo ratings yet
- A GAMP Based Low Complexity Sparse Bayesian Learning AlgorithmDocument15 pagesA GAMP Based Low Complexity Sparse Bayesian Learning AlgorithmShanmughanadha Reddy NimmanapalliNo ratings yet
- RnpregresskernelDocument24 pagesRnpregresskernelDaniel Redel SaavedraNo ratings yet
- Asec3 2020 Slides GLMDocument30 pagesAsec3 2020 Slides GLMamanu092No ratings yet
- Risk Convergence of Centered Kernel Ridge Regression With Large Dimensional DataDocument13 pagesRisk Convergence of Centered Kernel Ridge Regression With Large Dimensional DataDaniel Garcia MurilloNo ratings yet
- Chapter2-Timing and Profiling CodeDocument51 pagesChapter2-Timing and Profiling CodeRajachandra VoodigaNo ratings yet
- Chapter2-Timing and Profiling CodeDocument5 pagesChapter2-Timing and Profiling CodeRajachandra VoodigaNo ratings yet
- Chapter1-Foundations For EfficienciesDocument5 pagesChapter1-Foundations For EfficienciesRajachandra VoodigaNo ratings yet
- Chapter4-Basic Pandas OptimizationsDocument37 pagesChapter4-Basic Pandas OptimizationsRajachandra VoodigaNo ratings yet
- Chapter3 Gaining EfficienciesDocument58 pagesChapter3 Gaining EfficienciesRajachandra VoodigaNo ratings yet
- Chapter1-Foundations For EfficienciesDocument28 pagesChapter1-Foundations For EfficienciesRajachandra VoodigaNo ratings yet
- Reinforcement LearningDocument23 pagesReinforcement LearningRajachandra VoodigaNo ratings yet
- Uncertainity QuantificationDocument88 pagesUncertainity QuantificationRajachandra VoodigaNo ratings yet
- Time SeriesDocument91 pagesTime SeriesRajachandra VoodigaNo ratings yet
- Semi-: Supervised LearningDocument40 pagesSemi-: Supervised LearningRajachandra VoodigaNo ratings yet
- 2 Machine Learning GeneralDocument56 pages2 Machine Learning GeneralRajachandra VoodigaNo ratings yet
- Recommender SystemsDocument12 pagesRecommender SystemsRajachandra VoodigaNo ratings yet
- RNN LSTMDocument49 pagesRNN LSTMRajachandra VoodigaNo ratings yet
- Ensemble MethodDocument115 pagesEnsemble MethodRajachandra VoodigaNo ratings yet
- Supervised LearningDocument210 pagesSupervised LearningRajachandra VoodigaNo ratings yet
- Gurukul DataScience Jan2022Document34 pagesGurukul DataScience Jan2022Rajachandra VoodigaNo ratings yet
- RegressionDocument4 pagesRegressionRajachandra VoodigaNo ratings yet
- What To Do When It Is Not WorkingDocument7 pagesWhat To Do When It Is Not WorkingRajachandra VoodigaNo ratings yet
- Joining Data in SQL Cheat SheetDocument1 pageJoining Data in SQL Cheat SheetRajachandra VoodigaNo ratings yet
- 4 Selected Topics in Computer Vision & Deep LearningDocument78 pages4 Selected Topics in Computer Vision & Deep LearningRajachandra VoodigaNo ratings yet
- Strategic Data Science-PreviewDocument109 pagesStrategic Data Science-PreviewRajachandra VoodigaNo ratings yet
- Monthly Periodicals v2Document47 pagesMonthly Periodicals v2Rajachandra VoodigaNo ratings yet
- 20210501-ML Question BankDocument1 page20210501-ML Question BankRajachandra VoodigaNo ratings yet
- 1 Computer ScienceDocument60 pages1 Computer ScienceRajachandra VoodigaNo ratings yet
- 3 Fundamentals For Computer Vision & Deep LearningDocument56 pages3 Fundamentals For Computer Vision & Deep LearningRajachandra VoodigaNo ratings yet
- MachineLearning JDDocument90 pagesMachineLearning JDRajachandra VoodigaNo ratings yet
- Python Interview Preparation: February 2022Document36 pagesPython Interview Preparation: February 2022Rajachandra VoodigaNo ratings yet
- 08.time SeriesDocument1 page08.time SeriesRajachandra VoodigaNo ratings yet
- Week 1 DSDocument48 pagesWeek 1 DSRajachandra VoodigaNo ratings yet
- Ashish Tele: Data Scientist, Advanced AnalyticsDocument36 pagesAshish Tele: Data Scientist, Advanced AnalyticsRajachandra VoodigaNo ratings yet
- Affine Cipher: Project CodeDocument4 pagesAffine Cipher: Project CodeTariq MahmoodNo ratings yet
- Isye 6739 - Test 2 Solutions - Summer 2012Document9 pagesIsye 6739 - Test 2 Solutions - Summer 2012Iman Christin WirawanNo ratings yet
- CompressionDocument13 pagesCompressionnuredin abdellahNo ratings yet
- Robust Adaptive Control: The Search For The Holy GrailDocument45 pagesRobust Adaptive Control: The Search For The Holy GrailGilmar LeiteNo ratings yet
- Example:1: A.Circular Shift: All AllDocument28 pagesExample:1: A.Circular Shift: All AllJarin TasnimNo ratings yet
- 2ND Sem Syllabus PhysicsDocument5 pages2ND Sem Syllabus PhysicsVara PrasadNo ratings yet
- Quantum Sciam05Document6 pagesQuantum Sciam05J PabloNo ratings yet
- Multiple Choice QuestionsDocument8 pagesMultiple Choice QuestionsBan Le VanNo ratings yet
- Peng ProsDocument112 pagesPeng ProsWahyuSatyoTriadiNo ratings yet
- Proceedings of FTC ConferenceDocument948 pagesProceedings of FTC ConferenceMUIslamNo ratings yet
- PricingCMSSpreadOptionsAndDigitalCMSSpreadOptionsWithSmile Berrahoui PDFDocument7 pagesPricingCMSSpreadOptionsAndDigitalCMSSpreadOptionsWithSmile Berrahoui PDFshih_kaichihNo ratings yet
- Python Program For Dijkstra's Shortest Path Algorithm - Greedy Algo-7 - GeeksforGeeksDocument6 pagesPython Program For Dijkstra's Shortest Path Algorithm - Greedy Algo-7 - GeeksforGeeksmmorad aamraouyNo ratings yet
- Tutorial 11 - Z-Transform (Exercises)Document2 pagesTutorial 11 - Z-Transform (Exercises)Taylor Andres Amaya100% (1)
- DOQ117A - Quick Kaizen ModelDocument12 pagesDOQ117A - Quick Kaizen ModelShaimae ABOULMAJDNo ratings yet
- IGNOU AssignmentDocument2 pagesIGNOU AssignmentAjeet BainsNo ratings yet
- Weekly Summary2.1Document12 pagesWeekly Summary2.1Ambrish (gYpr.in)No ratings yet
- Class 06 07 Naive BayesDocument91 pagesClass 06 07 Naive BayesSumana BasuNo ratings yet
- Program 7-EM Algorithm-K Means AlgorithmDocument3 pagesProgram 7-EM Algorithm-K Means AlgorithmVijay Sathvika BNo ratings yet
- QP UpdatedDocument2 pagesQP Updatedsambhav raghuwanshiNo ratings yet
- Mirror Descent and Nonlinear Projected Subgradient Methods For Convex OptimizationDocument9 pagesMirror Descent and Nonlinear Projected Subgradient Methods For Convex OptimizationfurbyhaterNo ratings yet
- Nba Final ReportDocument25 pagesNba Final Reportapi-327567435No ratings yet
- Unit-11: Genetic: AlgorithmsDocument20 pagesUnit-11: Genetic: Algorithmsdemo dataNo ratings yet
- Essay 'Importance of Mathematics in The Modern World'Document1 pageEssay 'Importance of Mathematics in The Modern World'Sevilla Ernestdon100% (1)
- ChainerDocument3 pagesChainerava939No ratings yet
- Cns Manual No Source CodeDocument55 pagesCns Manual No Source CodeKumar JiNo ratings yet
- Problem Solving Through ProgrammingDocument2 pagesProblem Solving Through Programmingsaravanan chandrasekaranNo ratings yet
- 2a Davis PutnamDocument29 pages2a Davis PutnammelisnurverirNo ratings yet
- Garcia, Lab 2 FinalDocument31 pagesGarcia, Lab 2 Finalaccventure5No ratings yet
- ST1 4483 8995 Capstone PPT TemplateDocument10 pagesST1 4483 8995 Capstone PPT Template360mostafasaifNo ratings yet
- Poison Distribution TableDocument1 pagePoison Distribution TableKibet KiptooNo ratings yet