You might also like
- Le - Cpar Week 1Document3 pagesLe - Cpar Week 1Reniña Lucena CarpioNo ratings yet
- Palla: Vibrating MillDocument16 pagesPalla: Vibrating MillSanjeev AroraNo ratings yet
- Strategic Data Science-PreviewDocument109 pagesStrategic Data Science-PreviewRajachandra VoodigaNo ratings yet
- Ensemble MethodDocument115 pagesEnsemble MethodRajachandra VoodigaNo ratings yet
- Lecture 19 and 20Document27 pagesLecture 19 and 20shivna0809No ratings yet
- Lecture 11 - Probabilistic ML (3) - Parameter Estimation - PlainDocument8 pagesLecture 11 - Probabilistic ML (3) - Parameter Estimation - PlainRajachandra VoodigaNo ratings yet
- Lecture 16 - Hyperplane Classifiers - Perceptron - PlainDocument9 pagesLecture 16 - Hyperplane Classifiers - Perceptron - PlainRajachandra VoodigaNo ratings yet
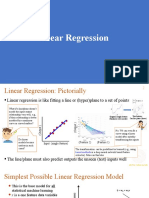
- Linear RegressionDocument14 pagesLinear RegressionALINA SOYNo ratings yet
- Logistic and Softmax Regression: CS771: Introduction To Machine Learning NisheethDocument15 pagesLogistic and Softmax Regression: CS771: Introduction To Machine Learning NisheethRajaNo ratings yet
- Linear Regression: CS771: Introduction To Machine Learning NisheethDocument14 pagesLinear Regression: CS771: Introduction To Machine Learning NisheethRajaNo ratings yet
- Lecture 29 - LVMs For Dimensionality Reduction - PlainDocument9 pagesLecture 29 - LVMs For Dimensionality Reduction - PlainRajachandra VoodigaNo ratings yet
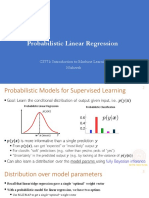
- Probabilistic Linear Regression: CS771: Introduction To Machine Learning NisheethDocument18 pagesProbabilistic Linear Regression: CS771: Introduction To Machine Learning NisheethRajaNo ratings yet
- Dimensionality Reduction: Principal Component Analysis and SVDDocument16 pagesDimensionality Reduction: Principal Component Analysis and SVDRajachandra VoodigaNo ratings yet
- Perceptrons and SVMS: Cs771: Introduction To Machine Learning NisheethDocument18 pagesPerceptrons and SVMS: Cs771: Introduction To Machine Learning NisheethRajaNo ratings yet
- Lecture 28 - Latent Variable Models (2) - P2 - PlainDocument8 pagesLecture 28 - Latent Variable Models (2) - P2 - PlainRajachandra VoodigaNo ratings yet
- Lecture 27 - Latent Variable Models (2) - P1 - PlainDocument11 pagesLecture 27 - Latent Variable Models (2) - P1 - PlainRajachandra VoodigaNo ratings yet
- Lecture 5Document18 pagesLecture 5coutyesNo ratings yet
- CS772 Lec10Document23 pagesCS772 Lec10juggernautjhaNo ratings yet
- Lecture 07 - Linear Regression - PlainDocument12 pagesLecture 07 - Linear Regression - PlainRajachandra VoodigaNo ratings yet
- Lecture 03 - Supervised Learning by Computing Distances - PlainDocument17 pagesLecture 03 - Supervised Learning by Computing Distances - PlainRajaNo ratings yet
- Lecture 13 - Probabilistic Linear Regression - PlainDocument19 pagesLecture 13 - Probabilistic Linear Regression - PlainRajachandra VoodigaNo ratings yet
- Optimization For ML: CS771: Introduction To Machine Learning NisheethDocument18 pagesOptimization For ML: CS771: Introduction To Machine Learning NisheethRajaNo ratings yet
- 771 A18 Lec7Document120 pages771 A18 Lec7DUDEKULA VIDYASAGARNo ratings yet
- Lecture 08 - Calculus and Optimization Techniques (1) - PlainDocument15 pagesLecture 08 - Calculus and Optimization Techniques (1) - PlainRajachandra VoodigaNo ratings yet
- Convolutional Neural Network - Aravind AriharasudhanDocument97 pagesConvolutional Neural Network - Aravind AriharasudhanAravind AriharasudhanNo ratings yet
- Lecture 17 and 18Document29 pagesLecture 17 and 18shivna0809No ratings yet
- 26-Probabilistic ML-Parameter EstimationDocument8 pages26-Probabilistic ML-Parameter Estimationbroken heartNo ratings yet
- Dimensionality Reduction (Contd) : CS771: Introduction To Machine Learning Piyush RaiDocument17 pagesDimensionality Reduction (Contd) : CS771: Introduction To Machine Learning Piyush RaiRajachandra VoodigaNo ratings yet
- GyuyuDocument11 pagesGyuyushivna0809No ratings yet
- CS771: Introduction To Machine Learning Piyush RaiDocument25 pagesCS771: Introduction To Machine Learning Piyush RaiRajachandra VoodigaNo ratings yet
- Lecture 19 and 20Document27 pagesLecture 19 and 20shivna0809No ratings yet
- Linear Models: CS771: Introduction To Machine Learning Piyush RaiDocument8 pagesLinear Models: CS771: Introduction To Machine Learning Piyush RaiRajachandra VoodigaNo ratings yet
- BNT HowtoDocument24 pagesBNT Howtoanu868No ratings yet
- NeuralProphet IntroductionDocument43 pagesNeuralProphet IntroductionSam TitusNo ratings yet
- Lecture 21 and 22Document28 pagesLecture 21 and 22shivna0809No ratings yet
- Lecture 10 - Probabilistic ML (1) - Basics of Probability - PlainDocument12 pagesLecture 10 - Probabilistic ML (1) - Basics of Probability - PlainRajaNo ratings yet
- Lecture 10 - Optimization Techniques (4) - PlainDocument6 pagesLecture 10 - Optimization Techniques (4) - PlainRajaNo ratings yet
- ML Summary PDFDocument5 pagesML Summary PDFJeevikaGoyalNo ratings yet
- Lecture 14 - Logistic and Softmax Regression - PlainDocument12 pagesLecture 14 - Logistic and Softmax Regression - PlainRajachandra VoodigaNo ratings yet
- CS 601 Machine Learning Unit 5Document18 pagesCS 601 Machine Learning Unit 5Priyanka BhateleNo ratings yet
- IntroDocument38 pagesIntroTran Kim ToaiNo ratings yet
- Variational BayesDocument38 pagesVariational BayeszNo ratings yet
- A Probabilistic Theory of Deep Learning: Unit 2Document17 pagesA Probabilistic Theory of Deep Learning: Unit 2HarshitNo ratings yet
- Homework 2: Lasso Regression: 1.1 Data Set and Programming Problem OverviewDocument11 pagesHomework 2: Lasso Regression: 1.1 Data Set and Programming Problem OverviewMayur AgrawalNo ratings yet
- La Places Demon TutorialDocument59 pagesLa Places Demon TutorialaaylmaoNo ratings yet
- 771 A18 Lec15Document96 pages771 A18 Lec15DUDEKULA VIDYASAGARNo ratings yet
- From Spreadsheet Thinking To R Thinking - BurnsDocument14 pagesFrom Spreadsheet Thinking To R Thinking - BurnsJhie EhefNo ratings yet
- DSC 190 Final ReportDocument10 pagesDSC 190 Final ReportHườngNo ratings yet
- Batch Reinforcement Learning: Alan FernDocument47 pagesBatch Reinforcement Learning: Alan FernRaghavendra M BhatNo ratings yet
- Lecture 09 - Calculus and Optimization Techniques (3) - PlainDocument15 pagesLecture 09 - Calculus and Optimization Techniques (3) - PlainRajaNo ratings yet
- Optimization For ML (2) : CS771: Introduction To Machine Learning Piyush RaiDocument14 pagesOptimization For ML (2) : CS771: Introduction To Machine Learning Piyush RaiRajaNo ratings yet
- Lecture 6Document41 pagesLecture 6Sher Afghan MalikNo ratings yet
- Cheat Sheet imputeTSDocument1 pageCheat Sheet imputeTSgugugagaNo ratings yet
- Lecture 15 - Generative Models For Supervised Learning - PlainDocument15 pagesLecture 15 - Generative Models For Supervised Learning - PlainRajachandra VoodigaNo ratings yet
- 7 Linear ModelDocument17 pages7 Linear ModelJiahong HeNo ratings yet
- Ds 8Document27 pagesDs 8Jglewd 2641No ratings yet
- cs188 sp23 Note25Document8 pagescs188 sp23 Note25sondosNo ratings yet
- Unit 5 - Machine Learning - WWW - Rgpvnotes.inDocument17 pagesUnit 5 - Machine Learning - WWW - Rgpvnotes.inASHOKA KUMARNo ratings yet
- Lecture 11 - Probabilistic ML (2) - Probability Basic Contd - PlainDocument8 pagesLecture 11 - Probabilistic ML (2) - Probability Basic Contd - PlainRajaNo ratings yet
- Demystifying Deep Learning2Document82 pagesDemystifying Deep Learning2Mario CordinaNo ratings yet
- Ds 12Document12 pagesDs 12Keerthana ChirumamillaNo ratings yet
- 771 A18 Lec6Document155 pages771 A18 Lec6DUDEKULA VIDYASAGARNo ratings yet
- Understanding Support Vector Machine Algorithm From Examples Along With CodeDocument11 pagesUnderstanding Support Vector Machine Algorithm From Examples Along With CodesurajdhunnaNo ratings yet
- Radial Basis Networks: Fundamentals and Applications for The Activation Functions of Artificial Neural NetworksFrom EverandRadial Basis Networks: Fundamentals and Applications for The Activation Functions of Artificial Neural NetworksNo ratings yet
- Chapter4-Basic Pandas OptimizationsDocument37 pagesChapter4-Basic Pandas OptimizationsRajachandra VoodigaNo ratings yet
- Chapter1-Foundations For EfficienciesDocument28 pagesChapter1-Foundations For EfficienciesRajachandra VoodigaNo ratings yet
- Chapter2-Timing and Profiling CodeDocument51 pagesChapter2-Timing and Profiling CodeRajachandra VoodigaNo ratings yet
- Chapter3 Gaining EfficienciesDocument58 pagesChapter3 Gaining EfficienciesRajachandra VoodigaNo ratings yet
- Chapter2-Timing and Profiling CodeDocument5 pagesChapter2-Timing and Profiling CodeRajachandra VoodigaNo ratings yet
- Reinforcement LearningDocument23 pagesReinforcement LearningRajachandra VoodigaNo ratings yet
- Recommender SystemsDocument12 pagesRecommender SystemsRajachandra VoodigaNo ratings yet
- Monthly Periodicals v2Document47 pagesMonthly Periodicals v2Rajachandra VoodigaNo ratings yet
- Chapter1-Foundations For EfficienciesDocument5 pagesChapter1-Foundations For EfficienciesRajachandra VoodigaNo ratings yet
- RNN LSTMDocument49 pagesRNN LSTMRajachandra VoodigaNo ratings yet
- Semi-: Supervised LearningDocument40 pagesSemi-: Supervised LearningRajachandra VoodigaNo ratings yet
- Time SeriesDocument91 pagesTime SeriesRajachandra VoodigaNo ratings yet
- Supervised LearningDocument210 pagesSupervised LearningRajachandra VoodigaNo ratings yet
- What To Do When It Is Not WorkingDocument7 pagesWhat To Do When It Is Not WorkingRajachandra VoodigaNo ratings yet
- Uncertainity QuantificationDocument88 pagesUncertainity QuantificationRajachandra VoodigaNo ratings yet
- Joining Data in SQL Cheat SheetDocument1 pageJoining Data in SQL Cheat SheetRajachandra VoodigaNo ratings yet
- 3 Fundamentals For Computer Vision & Deep LearningDocument56 pages3 Fundamentals For Computer Vision & Deep LearningRajachandra VoodigaNo ratings yet
- RegressionDocument4 pagesRegressionRajachandra VoodigaNo ratings yet
- Week 1 DSDocument48 pagesWeek 1 DSRajachandra VoodigaNo ratings yet
- Python Interview Preparation: February 2022Document36 pagesPython Interview Preparation: February 2022Rajachandra VoodigaNo ratings yet
- 2 Machine Learning GeneralDocument56 pages2 Machine Learning GeneralRajachandra VoodigaNo ratings yet
- Gurukul DataScience Jan2022Document34 pagesGurukul DataScience Jan2022Rajachandra VoodigaNo ratings yet
- 4 Selected Topics in Computer Vision & Deep LearningDocument78 pages4 Selected Topics in Computer Vision & Deep LearningRajachandra VoodigaNo ratings yet
- 20210501-ML Question BankDocument1 page20210501-ML Question BankRajachandra VoodigaNo ratings yet
- 08.time SeriesDocument1 page08.time SeriesRajachandra VoodigaNo ratings yet
- MachineLearning JDDocument90 pagesMachineLearning JDRajachandra VoodigaNo ratings yet
- 1 Computer ScienceDocument60 pages1 Computer ScienceRajachandra VoodigaNo ratings yet
- Ashish Tele: Data Scientist, Advanced AnalyticsDocument36 pagesAshish Tele: Data Scientist, Advanced AnalyticsRajachandra VoodigaNo ratings yet
- Ohmite Component Selector: Catalog 4000KDocument205 pagesOhmite Component Selector: Catalog 4000Klem abesamisNo ratings yet
- Soil Mechanics - Chapter 2 ExamplesDocument12 pagesSoil Mechanics - Chapter 2 ExamplesSelino CruzNo ratings yet
- CSR Paper ResearchDocument14 pagesCSR Paper ResearchJacqueline GalletoNo ratings yet
- Eng NHKDocument10 pagesEng NHKkiran smNo ratings yet
- 2014-Ogilvy, Nonaka, Konno-Toward Narrative StrategyDocument15 pages2014-Ogilvy, Nonaka, Konno-Toward Narrative StrategyMariana MendozaNo ratings yet
- Competitive Advantages RitelDocument15 pagesCompetitive Advantages RitelAsih ArumNo ratings yet
- Liquid Crystal Colloidal Structures For IncreasedDocument11 pagesLiquid Crystal Colloidal Structures For IncreasedCarlos Santos Bravo CcatamayoNo ratings yet
- Eligible Candidate List - RCCIIT - RAPIDD Technologies - WB - 2021 BatchDocument4 pagesEligible Candidate List - RCCIIT - RAPIDD Technologies - WB - 2021 BatchAbhishek DeyNo ratings yet
- Zener Diode As Voltage RegulatorDocument2 pagesZener Diode As Voltage RegulatorAMIT KUMAR SINGHNo ratings yet
- Ideal Gas Law NotesDocument4 pagesIdeal Gas Law NotesPrincess Jean GalabinNo ratings yet
- PCB Annual Report FormDocument6 pagesPCB Annual Report FormNimshi TorreNo ratings yet
- OI Calidades FinalesDocument8 pagesOI Calidades FinalesMarcelo VizcayaNo ratings yet
- CHM 222 Complexometric Titration PDFDocument38 pagesCHM 222 Complexometric Titration PDFGlory Usoro100% (1)
- Magnetic Field 2Document4 pagesMagnetic Field 2Yzabella Jhoy AlbertoNo ratings yet
- Optical Mineralogy: Use of The Petrographic MicroscopeDocument105 pagesOptical Mineralogy: Use of The Petrographic MicroscopeblablaNo ratings yet
- 4.2penjaminan Mutu Sediaan Farmasi - Oky YudiswaraDocument29 pages4.2penjaminan Mutu Sediaan Farmasi - Oky YudiswaraMUNIFRIZALNo ratings yet
- Some Guidelines and Guarantees For Common Random NumbersDocument25 pagesSome Guidelines and Guarantees For Common Random NumbersAditya TNo ratings yet
- Measures of Intellectualization of FilipinoDocument3 pagesMeasures of Intellectualization of Filipinolevine millanesNo ratings yet
- GODS Character SheetDocument4 pagesGODS Character SheetKerwan LE GOUILNo ratings yet
- Enginerring Room Resource Management Section III/1-2 and STCW Code Section A III/1 Paragraph 1-10Document1 pageEnginerring Room Resource Management Section III/1-2 and STCW Code Section A III/1 Paragraph 1-10Global Inovasi BersamaNo ratings yet
- RTP-LASG8Q3M5W5Document9 pagesRTP-LASG8Q3M5W5Atheena Johann VillaruelNo ratings yet
- Pedu 202Document44 pagesPedu 202Mejane MonterNo ratings yet
- De Writing 2020Document34 pagesDe Writing 2020leewuan1807No ratings yet
- 9701 s02 QP 5Document8 pages9701 s02 QP 5plant42No ratings yet
- Gravel Sealing: Prospects & ChallengesDocument29 pagesGravel Sealing: Prospects & ChallengesRajendra K KarkiNo ratings yet
- Structure 2 SoalDocument3 pagesStructure 2 SoalAgung WibowoNo ratings yet
- Artikel Ipk Jurnal RevisiDocument6 pagesArtikel Ipk Jurnal RevisiSRI BINTANG PAMUNGKASNo ratings yet
- 212 - VRV 5 Heat Recovery Product FlyerDocument35 pages212 - VRV 5 Heat Recovery Product Flyerbahiniy286No ratings yet