You might also like
- Multicore Software Development Techniques: Applications, Tips, and TricksFrom EverandMulticore Software Development Techniques: Applications, Tips, and TricksRating: 2.5 out of 5 stars2.5/5 (2)
- Parallel ProcessingDocument31 pagesParallel ProcessingSantosh SinghNo ratings yet
- Infiniband (Ib) Is A Computer Networking Communications Standard Used in High-PerformanceDocument7 pagesInfiniband (Ib) Is A Computer Networking Communications Standard Used in High-PerformanceMugabe DeogratiousNo ratings yet
- Operating Systems Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandOperating Systems Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- Unit VI Parallel Programming ConceptsDocument90 pagesUnit VI Parallel Programming ConceptsPrathameshNo ratings yet
- Parallel Computing Seminar ReportDocument35 pagesParallel Computing Seminar ReportAmeya Waghmare100% (3)
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedFrom EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedNo ratings yet
- Parallel Computing (Unit5)Document25 pagesParallel Computing (Unit5)Shriniwas YadavNo ratings yet
- Build Your Own Distributed Compilation Cluster: A Practical WalkthroughFrom EverandBuild Your Own Distributed Compilation Cluster: A Practical WalkthroughNo ratings yet
- 24-25 - Parallel Processing PDFDocument36 pages24-25 - Parallel Processing PDFfanna786No ratings yet
- Programação Paralela e DistribuídaDocument39 pagesProgramação Paralela e DistribuídaMarcelo AzevedoNo ratings yet
- Introduction To Parallel ProcessingDocument29 pagesIntroduction To Parallel ProcessingAzri Mohd KhanilNo ratings yet
- Lecture Week - 2 General Parallelism TermsDocument24 pagesLecture Week - 2 General Parallelism TermsimhafeezniaziNo ratings yet
- CS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesDocument47 pagesCS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesNehaNo ratings yet
- Parallel Processing: Breaking Complex Problems into Smaller PiecesDocument8 pagesParallel Processing: Breaking Complex Problems into Smaller PiecesToobaNo ratings yet
- 1 Overview, Models of Computation, Brent's TheoremDocument8 pages1 Overview, Models of Computation, Brent's TheoremDr P ChitraNo ratings yet
- IntroductionDocument34 pagesIntroductionjosephboyong542No ratings yet
- Data Parallel AlgorithmsDocument14 pagesData Parallel AlgorithmsmilhousevvpNo ratings yet
- Week1 - Parallel and Distributed ComputingDocument46 pagesWeek1 - Parallel and Distributed ComputingA NNo ratings yet
- Task Level Parallelization of All Pair Shortest Path Algorithm in Openmp 3.0Document4 pagesTask Level Parallelization of All Pair Shortest Path Algorithm in Openmp 3.0Hoàng VănNo ratings yet
- PCA Chapter 1: Flynn's Classification and Parallel Processing ModelsDocument61 pagesPCA Chapter 1: Flynn's Classification and Parallel Processing ModelsAYUSH KUMARNo ratings yet
- Parallel Computing: Charles KoelbelDocument12 pagesParallel Computing: Charles KoelbelSilvio DresserNo ratings yet
- Advanced Computer ArchitectureDocument28 pagesAdvanced Computer ArchitectureSameer KhudeNo ratings yet
- Multithreading Algorithms ExplainedDocument36 pagesMultithreading Algorithms ExplainedAsna TariqNo ratings yet
- ACA Assignment 4Document16 pagesACA Assignment 4shresth choudharyNo ratings yet
- M M M M: M M M M M MDocument28 pagesM M M M: M M M M M MAishwarya Pratap SinghNo ratings yet
- Chapter 9Document28 pagesChapter 9Hiywot yesufNo ratings yet
- A Presentation On Parallel Computing: - Ameya Waghmare (Rno 41, BE CSE) Guided by-Dr.R.P.Adgaonkar (HOD), CSE DeptDocument32 pagesA Presentation On Parallel Computing: - Ameya Waghmare (Rno 41, BE CSE) Guided by-Dr.R.P.Adgaonkar (HOD), CSE DeptShubhadip DindaNo ratings yet
- Parallel Computing: An Overview of Concepts, Approaches and ImplementationDocument32 pagesParallel Computing: An Overview of Concepts, Approaches and ImplementationaadrikaNo ratings yet
- Parallel Archtecture and ComputingDocument65 pagesParallel Archtecture and ComputingUmesh VatsNo ratings yet
- Unit 4Document7 pagesUnit 4tanuverma0215No ratings yet
- A Presentation On Parallel Computing: - Ameya Waghmare (Rno 41, BE CSE) Guided by-Dr.R.P.Adgaonkar (HOD), CSE DeptDocument32 pagesA Presentation On Parallel Computing: - Ameya Waghmare (Rno 41, BE CSE) Guided by-Dr.R.P.Adgaonkar (HOD), CSE DeptManish RavulaNo ratings yet
- Unit 7 - Parallel Processing ParadigmDocument26 pagesUnit 7 - Parallel Processing ParadigmMUHMMAD ZAID KURESHINo ratings yet
- Parallel Processors From Client To Cloud: Omputer Rganization and EsignDocument43 pagesParallel Processors From Client To Cloud: Omputer Rganization and EsignPavithra JanarthananNo ratings yet
- Cluster Computing: Dr. C. Amalraj 12/02/2021 The University of Moratuwa Amalraj@uom - LKDocument34 pagesCluster Computing: Dr. C. Amalraj 12/02/2021 The University of Moratuwa Amalraj@uom - LKNishshanka CJNo ratings yet
- Synopsis On "Massive Parallel Processing (MPP) "Document4 pagesSynopsis On "Massive Parallel Processing (MPP) "Jyoti PunhaniNo ratings yet
- Parallel Computing: "Parallelization" Redirects Here. For Parallelization of Manifolds, SeeDocument20 pagesParallel Computing: "Parallelization" Redirects Here. For Parallelization of Manifolds, SeeVaibhav RoyNo ratings yet
- Parallel AlgorithmDocument48 pagesParallel AlgorithmBipin SaraswatNo ratings yet
- Cs405-Computer System Architecture: Module - 1 Parallel Computer ModelsDocument91 pagesCs405-Computer System Architecture: Module - 1 Parallel Computer Modelsashji s rajNo ratings yet
- High Performance Computing-1 PDFDocument15 pagesHigh Performance Computing-1 PDFPriyanka JadhavNo ratings yet
- Parallel ComputingDocument28 pagesParallel ComputingGica SelyNo ratings yet
- Unit - IDocument20 pagesUnit - Isas100% (1)
- Mpi CourseDocument202 pagesMpi CourseKiarie Jimmy NjugunahNo ratings yet
- A Presentation On Parallel Computing: - Ameya Waghmare (Rno 41, BE CSE) Guided by-Dr.R.P.Adgaonkar (HOD), CSE DeptDocument32 pagesA Presentation On Parallel Computing: - Ameya Waghmare (Rno 41, BE CSE) Guided by-Dr.R.P.Adgaonkar (HOD), CSE DeptaadrikaNo ratings yet
- Unit 5Document29 pagesUnit 5kiran281196No ratings yet
- Serial and Parallel First 3 LectureDocument17 pagesSerial and Parallel First 3 LectureAsif KhanNo ratings yet
- Cs405-Computer System Architecture: Module - 1 Parallel Computer ModelsDocument72 pagesCs405-Computer System Architecture: Module - 1 Parallel Computer Modelsashji s rajNo ratings yet
- CS405- Parallel Computer ModelsDocument72 pagesCS405- Parallel Computer Modelsashji s rajNo ratings yet
- Assignment-2 Ami Pandat Parallel Processing: Time ComplexityDocument12 pagesAssignment-2 Ami Pandat Parallel Processing: Time ComplexityVICTBTECH SPUNo ratings yet
- Parallel Programming IntroductionDocument17 pagesParallel Programming IntroductionYang YiNo ratings yet
- Aca NotesDocument148 pagesAca NotesHanisha BavanaNo ratings yet
- Begin Parallel Programming With OpenMP - CodeProjectDocument8 pagesBegin Parallel Programming With OpenMP - CodeProjectManojSudarshanNo ratings yet
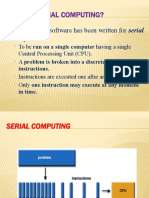
- What Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDocument22 pagesWhat Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDivya NigamNo ratings yet
- parallelDocument14 pagesparallelHAMDANI IbrahimNo ratings yet
- Assignment On: "Parallel Algorithm"Document4 pagesAssignment On: "Parallel Algorithm"Ashadul HoqueNo ratings yet
- PDC - Lecture - No. 3Document34 pagesPDC - Lecture - No. 3nauman tariqNo ratings yet
- CCP - Parallel ComputingDocument10 pagesCCP - Parallel ComputingNaveen SettyNo ratings yet
- ZeeshanDocument4 pagesZeeshannauman tariqNo ratings yet
- Caption WritingDocument2 pagesCaption Writingnauman tariqNo ratings yet
- How computers perform multi-taskingDocument4 pagesHow computers perform multi-taskingnauman tariqNo ratings yet
- Compiler ConstructionDocument19 pagesCompiler Constructionnauman tariqNo ratings yet
- PDC - Lecture - No. 3Document34 pagesPDC - Lecture - No. 3nauman tariqNo ratings yet
- Database Project Hospital Management SystemDocument91 pagesDatabase Project Hospital Management Systemnauman tariqNo ratings yet
- Database Project Hospital Management SystemDocument91 pagesDatabase Project Hospital Management Systemnauman tariqNo ratings yet
- CN The OSI Model ExplainedDocument4 pagesCN The OSI Model Explainednauman tariqNo ratings yet
- CN The OSI Model ExplainedDocument4 pagesCN The OSI Model Explainednauman tariqNo ratings yet
- CN-The OSI Model ExplainedDocument4 pagesCN-The OSI Model Explainednauman tariqNo ratings yet
- Postgraduate Tax Audit GuideDocument6 pagesPostgraduate Tax Audit Guidenauman tariqNo ratings yet
- Assignment-Cn: Syeda Pakiza ImranDocument5 pagesAssignment-Cn: Syeda Pakiza Imrannauman tariqNo ratings yet
- TRAN-102 - CMC Quiz 1 Spring 2020Document1 pageTRAN-102 - CMC Quiz 1 Spring 2020nauman tariqNo ratings yet
- CN-The OSI Model ExplainedDocument4 pagesCN-The OSI Model Explainednauman tariqNo ratings yet
- AlgoDocument1 pageAlgonauman tariqNo ratings yet
- Assignment-Cn: Syeda Pakiza ImranDocument5 pagesAssignment-Cn: Syeda Pakiza Imrannauman tariqNo ratings yet
- Essay WrittingDocument12 pagesEssay Writtingnauman tariqNo ratings yet
- Theories of Punishment in WestDocument2 pagesTheories of Punishment in Westnauman tariqNo ratings yet
- # Algorithm and Examples: Assignment #1Document5 pages# Algorithm and Examples: Assignment #1nauman tariqNo ratings yet
- Lab Task No. 5: 19011519-088 Nauman: Bs-Cs-ADocument6 pagesLab Task No. 5: 19011519-088 Nauman: Bs-Cs-Anauman tariqNo ratings yet
- Assignment No:1 Name: Waleed Tariq Submitted To: Sir Hamza Subject: TAX Assignment Topic: Audit Class: LLM Semester 2 Campus: University of LahoreDocument6 pagesAssignment No:1 Name: Waleed Tariq Submitted To: Sir Hamza Subject: TAX Assignment Topic: Audit Class: LLM Semester 2 Campus: University of Lahorenauman tariqNo ratings yet
- Submitted BY: Ali RazaDocument3 pagesSubmitted BY: Ali Razanauman tariqNo ratings yet
- Circular To Parents About S.ST AssessmentDocument1 pageCircular To Parents About S.ST Assessmentnauman tariqNo ratings yet
- Postgraduate Tax Audit GuideDocument6 pagesPostgraduate Tax Audit Guidenauman tariqNo ratings yet
- Check List Orientation Session Aug 2020Document1 pageCheck List Orientation Session Aug 2020nauman tariqNo ratings yet
- Topic: Lab Task 11Document2 pagesTopic: Lab Task 11nauman tariqNo ratings yet
- Multivariable Calculus is the Foundation of Computer ScienceDocument1 pageMultivariable Calculus is the Foundation of Computer Sciencenauman tariqNo ratings yet
- Lab Task No. 5: 19011519-088 Nauman: Bs-Cs-ADocument6 pagesLab Task No. 5: 19011519-088 Nauman: Bs-Cs-Anauman tariqNo ratings yet
- Essay WrittingDocument12 pagesEssay Writtingnauman tariqNo ratings yet
- 2 Performance MatiricesDocument22 pages2 Performance MatiricesAbhishek JindalNo ratings yet
- Pipeline HazardsDocument94 pagesPipeline HazardsMasud SarkerNo ratings yet
- Dca6105 - Computer ArchitectureDocument6 pagesDca6105 - Computer Architectureanshika mahajanNo ratings yet
- HPC MCQDocument3 pagesHPC MCQJayaprabha KanseNo ratings yet
- Lecture-13-14 Parallel and Distributed Systems Programming Models-JameelDocument70 pagesLecture-13-14 Parallel and Distributed Systems Programming Models-JameelAbdul BariiNo ratings yet
- Parallel and Distributed AlgorithmsDocument65 pagesParallel and Distributed AlgorithmsSergiu VolocNo ratings yet
- Aca Q-BankDocument3 pagesAca Q-BankAyan DasNo ratings yet
- An Open-Source Toolbox For Multiphase Flow in Porous MediaDocument26 pagesAn Open-Source Toolbox For Multiphase Flow in Porous MediaAndrés SalazarNo ratings yet
- Amdahl's Law ExplainedDocument2 pagesAmdahl's Law ExplainedShaikh AdnanNo ratings yet
- Real Time Programming CourseDocument124 pagesReal Time Programming CourseRomeoNo ratings yet
- pdc1: MODULE 1: PARALLELISM FUNDAMENTALSDocument42 pagespdc1: MODULE 1: PARALLELISM FUNDAMENTALSVandana M 19BCE1763No ratings yet
- Lecture Notes On Parallel Processing PipelineDocument12 pagesLecture Notes On Parallel Processing PipelineYowaraj ChhetriNo ratings yet
- Pepper PresentationDocument38 pagesPepper PresentationMohamed BalbaaNo ratings yet
- Unit No.4 Parallel DatabaseDocument32 pagesUnit No.4 Parallel DatabasePadre BhojNo ratings yet
- Unit 1 CloudDocument102 pagesUnit 1 CloudChetha SpNo ratings yet
- Implementation Issue For Super Instructions in GforthDocument9 pagesImplementation Issue For Super Instructions in GforthvijaymathewNo ratings yet
- Chapter 1 - Fundamentals of Computer DesignDocument40 pagesChapter 1 - Fundamentals of Computer Designarchumeenabalu100% (1)
- Computational foundations of cyber physical systems tutorial on pipelining and memory hierarchy problemsDocument13 pagesComputational foundations of cyber physical systems tutorial on pipelining and memory hierarchy problemsbrahma2deen2chaudharNo ratings yet
- Principles of Scalable PerformanceDocument7 pagesPrinciples of Scalable Performanceboreddyln0% (1)
- Quasar: Resource-Efficient and Qos-Aware Cluster Management: Christina Delimitrou and Christos KozyrakisDocument17 pagesQuasar: Resource-Efficient and Qos-Aware Cluster Management: Christina Delimitrou and Christos KozyrakisDeep PNo ratings yet
- Parallel CFD in CFDDocument25 pagesParallel CFD in CFDMohamed OudaNo ratings yet
- HW Problems Chapter-1Document3 pagesHW Problems Chapter-1William DoveNo ratings yet
- COAL LAb Manual 13Document8 pagesCOAL LAb Manual 13Zulqarnain FastNUNo ratings yet
- International Journal of Computer Science and Security (IJCSS), Volume (1), IssueDocument101 pagesInternational Journal of Computer Science and Security (IJCSS), Volume (1), IssueAI Coordinator - CSC JournalsNo ratings yet
- 7th ITDocument6 pages7th ITYashika JindalNo ratings yet
- Distributed Computing With Python - Sample ChapterDocument18 pagesDistributed Computing With Python - Sample ChapterPackt PublishingNo ratings yet
- TNavigator Modules Available 2019 ENGDocument26 pagesTNavigator Modules Available 2019 ENGVitor Azevedo Jr100% (1)
- How A Processor Can Permute N Bits in O (1) CyclesDocument12 pagesHow A Processor Can Permute N Bits in O (1) Cycleskaran007_mNo ratings yet
- Assignment - II: Udayapura, Kanakapura Road, Bengaluru-560082, KarnatakaDocument2 pagesAssignment - II: Udayapura, Kanakapura Road, Bengaluru-560082, KarnatakaashiNo ratings yet
- U K J C M M S: Sing Nowledge of OB Haracteristics IN Ultiprogrammed Ultiprocessor ChedulingDocument202 pagesU K J C M M S: Sing Nowledge of OB Haracteristics IN Ultiprogrammed Ultiprocessor Chedulingأبو أيوب تافيلالتNo ratings yet