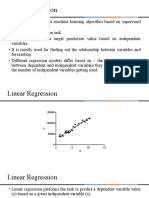
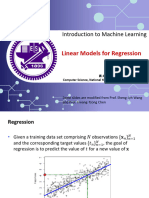
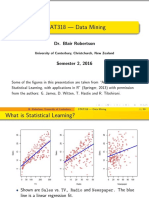
You might also like
- 11-Logistic RegressionDocument27 pages11-Logistic RegressionNaitik TyagiNo ratings yet
- Regularization 1704650055Document32 pagesRegularization 1704650055Vani agarwalNo ratings yet
- Logistic ClassificationDocument44 pagesLogistic ClassificationN Samhing100% (1)
- Lecture 8: Gradient Descent and Logistic RegressionDocument39 pagesLecture 8: Gradient Descent and Logistic RegressionAshish JainNo ratings yet
- Regression PPTDocument21 pagesRegression PPTRakesh bhukyaNo ratings yet
- Unit 7Document43 pagesUnit 7Yuvraj RanaNo ratings yet
- Supervised Learning 1 PDFDocument162 pagesSupervised Learning 1 PDFAlexanderNo ratings yet
- Regularization: Swetha V, Research ScholarDocument32 pagesRegularization: Swetha V, Research ScholarShanmuganathan V (RC2113003011029)No ratings yet
- 3 TrainingNetworkDocument65 pages3 TrainingNetworkSWAMYA RANJAN DASNo ratings yet
- Logistic RegressionDocument42 pagesLogistic RegressionCollins ChavhangaNo ratings yet
- Lecture 09 MLDocument26 pagesLecture 09 MLsaharabdoumaNo ratings yet
- Lecture 4Document33 pagesLecture 4Venkat ram ReddyNo ratings yet
- Exploring The ModelDocument13 pagesExploring The Modelsst sharunNo ratings yet
- I. Models and Cost Functions: ML NotationsDocument13 pagesI. Models and Cost Functions: ML Notationssst sharunNo ratings yet
- Theory in Machine LearningDocument47 pagesTheory in Machine LearningSreetam Ganguly100% (2)
- Regression in M.LDocument13 pagesRegression in M.LSaif JuttNo ratings yet
- SML Unit 4Document61 pagesSML Unit 4aryan kumarNo ratings yet
- Module 3Document35 pagesModule 32021.shreya.pawaskarNo ratings yet
- Unit VDocument27 pagesUnit V05Bala SaatvikNo ratings yet
- Linear RegressionDocument36 pagesLinear RegressionSiddharth DoshiNo ratings yet
- Lecture Slides-Week11Document32 pagesLecture Slides-Week11moazzam kianiNo ratings yet
- Supervised Algorithms-Regression: Linear & Logistic: Muhammad Bello AliyuDocument32 pagesSupervised Algorithms-Regression: Linear & Logistic: Muhammad Bello AliyuMohammed Danlami Yusuf100% (1)
- Lecture Slides Week11Document33 pagesLecture Slides Week11moazzam kianiNo ratings yet
- Gradient DescentDocument17 pagesGradient DescentJatin Kumar GargNo ratings yet
- Numerical Methods Chapter 1 3 4Document44 pagesNumerical Methods Chapter 1 3 4dsnNo ratings yet
- w4 GeneralisationDocument42 pagesw4 GeneralisationSwastik SindhaniNo ratings yet
- Logistic RegressionDocument14 pagesLogistic RegressionYogesh RaiNo ratings yet
- Introduction To Machine Learning Lecture 2: Linear RegressionDocument38 pagesIntroduction To Machine Learning Lecture 2: Linear RegressionDeepa DevarajNo ratings yet
- Regularization Strategies for Deep Learning ModelsDocument31 pagesRegularization Strategies for Deep Learning ModelsTarun GopalanNo ratings yet
- CS464 Ch9 LinearRegressionDocument43 pagesCS464 Ch9 LinearRegressionOnur Asım İlhan100% (1)
- W12_SVMDocument52 pagesW12_SVMprashantkr2698No ratings yet
- Lecture Slides-Week9Document46 pagesLecture Slides-Week9moazzam kianiNo ratings yet
- SVM Classifies Data Using Margins & KernelsDocument47 pagesSVM Classifies Data Using Margins & KernelsYASH GAIKWADNo ratings yet
- Unit-2: Logistic RegressionDocument30 pagesUnit-2: Logistic Regressionjas deepNo ratings yet
- MLA TAB Lecture3Document70 pagesMLA TAB Lecture3Lori GuerraNo ratings yet
- Linear Algebra & Its Application in ITDocument5 pagesLinear Algebra & Its Application in ITRaNa AhMaDNo ratings yet
- Linear RegressionDocument60 pagesLinear RegressionNaresha aNo ratings yet
- Pattern Recognition Machine Learning: Chapter 3: Linear Models For RegressionDocument48 pagesPattern Recognition Machine Learning: Chapter 3: Linear Models For RegressionHarish Kumar J100% (1)
- Lecture Slides-Week9,10Document66 pagesLecture Slides-Week9,10moazzam kianiNo ratings yet
- Notes 14Document18 pagesNotes 14Yash SirowaNo ratings yet
- Tutorial 7 Machine Learning AlgorithmsDocument30 pagesTutorial 7 Machine Learning AlgorithmsWenbo PanNo ratings yet
- GD in LRDocument23 pagesGD in LRPooja PatwariNo ratings yet
- CSO504 Machine Learning: Evaluation and Error Analysis Regularization Koustav Rudra 24/08/2022Document36 pagesCSO504 Machine Learning: Evaluation and Error Analysis Regularization Koustav Rudra 24/08/2022Being IITianNo ratings yet
- Lecture 02 (3hrs) Linear Regression and Logistic RegressionDocument42 pagesLecture 02 (3hrs) Linear Regression and Logistic RegressionEngr. Md. Borhan UddinNo ratings yet
- Feature Selection For SVMS: by J. Weston, S. Mukherjee, O. Chapelle, M. Pontil, T. Poggio, V. VapnikDocument19 pagesFeature Selection For SVMS: by J. Weston, S. Mukherjee, O. Chapelle, M. Pontil, T. Poggio, V. VapnikJoseph JoseNo ratings yet
- SVM RegressorDocument13 pagesSVM Regressorsrir93616No ratings yet
- Chapter 6 OptimizationDocument11 pagesChapter 6 OptimizationMark MagumbaNo ratings yet
- Lecture2 2013Document60 pagesLecture2 2013Fc KhanNo ratings yet
- Linear - RegressionDocument39 pagesLinear - Regressionhowgibaa100% (1)
- 2-Logistic RegressionDocument15 pages2-Logistic Regressionabdala sabryNo ratings yet
- Pro 10 TheoryDocument2 pagesPro 10 TheoryAnonymous qZP5Zyb2No ratings yet
- Logistic Regression (Autosaved)Document21 pagesLogistic Regression (Autosaved)Siddharth DoshiNo ratings yet
- ML NotesDocument14 pagesML NoteszomukozaNo ratings yet
- Unit 5Document28 pagesUnit 5Prathmesh Mane DeshmukhNo ratings yet
- Linear Regression With Gradient Descent MethodDocument10 pagesLinear Regression With Gradient Descent MethodnaralNo ratings yet
- Solving Systems of Linear Equations. Iterative MethodsDocument15 pagesSolving Systems of Linear Equations. Iterative MethodsJulija KaraliunaiteNo ratings yet
- 03 Linear ModelsDocument46 pages03 Linear Modelshmiida tfmNo ratings yet
- SVM Using PythonDocument24 pagesSVM Using PythonRavindra AmbilwadeNo ratings yet
- HhghiikkkDocument29 pagesHhghiikkkSamarth SharmaNo ratings yet
- Probability - Why Is $ - Bar X (1 - Bar X) + - Frac (S 2) (N) $ An Unbiased Estimator of $ - Mu (1 - Mu) $ - Mathematics Stack ExchangeDocument4 pagesProbability - Why Is $ - Bar X (1 - Bar X) + - Frac (S 2) (N) $ An Unbiased Estimator of $ - Mu (1 - Mu) $ - Mathematics Stack ExchangeScarfaceXXXNo ratings yet
- Tiket Masuk Print EkonmtrkaDocument11 pagesTiket Masuk Print EkonmtrkaEkaayu pratiwiNo ratings yet
- Quantitative Macroeconomics Ardl Model: 100403596@alumnos - Uc3m.esDocument10 pagesQuantitative Macroeconomics Ardl Model: 100403596@alumnos - Uc3m.esManuel FernandezNo ratings yet
- Simple Linear Regression and CorrelationDocument50 pagesSimple Linear Regression and CorrelationtesfuNo ratings yet
- Logistic RegressionDocument21 pagesLogistic RegressionDaneil RadcliffeNo ratings yet
- STAT318 - Data Mining: Dr. Blair RobertsonDocument39 pagesSTAT318 - Data Mining: Dr. Blair RobertsonCesilyNo ratings yet
- Latin Square DesignDocument8 pagesLatin Square DesignSerajum Monira MouriNo ratings yet
- Data Science Chapitre 2Document132 pagesData Science Chapitre 2Sadouli SaifNo ratings yet
- Estimating Population Mean When σ is Unknown LESSON PLANDocument3 pagesEstimating Population Mean When σ is Unknown LESSON PLANMichael Manipon Segundo100% (2)
- OLS Asymptotic Properties NotesDocument4 pagesOLS Asymptotic Properties Notesranjana kashyapNo ratings yet
- T-Test: Output Nomor 1Document10 pagesT-Test: Output Nomor 1Octavia OctaviaNo ratings yet
- Problema 6.20Document20 pagesProblema 6.20juanaNo ratings yet
- High-Resolution Direct Position Determination Using MVDRDocument13 pagesHigh-Resolution Direct Position Determination Using MVDRMostafa NaseriNo ratings yet
- MGSC 372Document9 pagesMGSC 372Naes NunssevatarNo ratings yet
- An Introduction To Robust RegressionDocument42 pagesAn Introduction To Robust RegressioncrcalubNo ratings yet
- Homework5 S23Document2 pagesHomework5 S23Janvi UdeshiNo ratings yet
- Slides Prepared by John S. Loucks St. Edward's University: 1 Slide © 2002 South-Western/Thomson LearningDocument33 pagesSlides Prepared by John S. Loucks St. Edward's University: 1 Slide © 2002 South-Western/Thomson LearningNajasyafaNo ratings yet
- Hausman - Hausman Specification TestDocument10 pagesHausman - Hausman Specification TestSaiganesh RameshNo ratings yet
- Curriculum Module 5 QuestionsDocument9 pagesCurriculum Module 5 QuestionsEmin SalmanovNo ratings yet
- 09.the Gauss-Markov Theorem and BLUE OLS Coefficient EstimatesDocument10 pages09.the Gauss-Markov Theorem and BLUE OLS Coefficient Estimatesmalanga.bangaNo ratings yet
- IEEE Standard 1366 - Classifying Reliability (SAIDI, SAIFI, CAIDI) Into Normal, Major Event and Catastrophic DaysDocument30 pagesIEEE Standard 1366 - Classifying Reliability (SAIDI, SAIFI, CAIDI) Into Normal, Major Event and Catastrophic DaysIvana RadićNo ratings yet
- Randomized Complete Block Design (RCBD) Description of The DesignDocument30 pagesRandomized Complete Block Design (RCBD) Description of The Designstatistics on tips 2020No ratings yet
- Statistical Methods For Economics 2020Document3 pagesStatistical Methods For Economics 2020Vineet AgrahariNo ratings yet
- Problem Set 1Document26 pagesProblem Set 1samir880100% (2)
- Stata ExcelDocument44 pagesStata ExcelchompoonootNo ratings yet
- Kajian Faktor-Faktor Yang Mempengaruhi Motivasi Belajar Geografi Di SMADocument7 pagesKajian Faktor-Faktor Yang Mempengaruhi Motivasi Belajar Geografi Di SMAPaulus Robert TuerahNo ratings yet
- Journal of Applied Statistics Volume 43 Issue 7 2016 (Doi 10.1080/02664763.2015.1094036) Caudill, Steven B. Mixon, Franklin G. - Estimating Class-Specific Parametric Models Using Finite MixDocument10 pagesJournal of Applied Statistics Volume 43 Issue 7 2016 (Doi 10.1080/02664763.2015.1094036) Caudill, Steven B. Mixon, Franklin G. - Estimating Class-Specific Parametric Models Using Finite MixrodrigoromoNo ratings yet
- Smple Linear RssionDocument10 pagesSmple Linear RssionSurvey_easyNo ratings yet