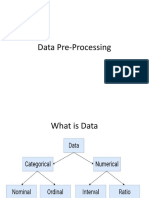
You might also like
- PreprocessingDocument62 pagesPreprocessingpoi.tamrakarNo ratings yet
- Data Mining and Predictive Modelling: Lecture 4: Data Pre-ProcessingDocument19 pagesData Mining and Predictive Modelling: Lecture 4: Data Pre-ProcessingMohitNo ratings yet
- Introduction Unit - Summary: Data MiningDocument62 pagesIntroduction Unit - Summary: Data MiningMeetNo ratings yet
- Knowledge Discovery and Data MiningDocument55 pagesKnowledge Discovery and Data MiningRupesh VNo ratings yet
- WINSEM2023-24 - BECE352E - ETH - VL2023240504409 - 2024-02-03 - Reference-Material-I 2Document16 pagesWINSEM2023-24 - BECE352E - ETH - VL2023240504409 - 2024-02-03 - Reference-Material-I 2Aditya Bonnerjee 21BEC0384No ratings yet
- JAVA Advanced 3Document19 pagesJAVA Advanced 3Lucky MahantoNo ratings yet
- Pre ProcessingDocument60 pagesPre Processingvani_V_prakashNo ratings yet
- Spatial and Temporal Data MiningDocument52 pagesSpatial and Temporal Data Miningamanpcte07No ratings yet
- Data PreprocessingDocument77 pagesData Preprocessing20bme094No ratings yet
- 03-Data Preprocessing 2021Document33 pages03-Data Preprocessing 2021Lakshmi Priya BNo ratings yet
- Data Preparation: KIT306/606: Data Analytics A/Prof. Quan Bai University of TasmaniaDocument49 pagesData Preparation: KIT306/606: Data Analytics A/Prof. Quan Bai University of TasmaniaJason ZengNo ratings yet
- Agenda: - Why Data Preprocessing?Document51 pagesAgenda: - Why Data Preprocessing?Lakshmi PrashanthNo ratings yet
- CIS664-Knowledge Discovery and Data MiningDocument52 pagesCIS664-Knowledge Discovery and Data MiningAkbar KushanoorNo ratings yet
- Week 4 - 5 - Data PreprocessingDocument67 pagesWeek 4 - 5 - Data PreprocessingHussain ASLNo ratings yet
- 3 RaviDocument82 pages3 RaviKrishna ChauhanNo ratings yet
- Data Pre-Processing: - Data Cleaning - Data Integration - Data Transformation - Data Reduction - Data DiscretizationDocument55 pagesData Pre-Processing: - Data Cleaning - Data Integration - Data Transformation - Data Reduction - Data DiscretizationChanda TestNo ratings yet
- Dwina DM 03 Persiapan 2018Document82 pagesDwina DM 03 Persiapan 2018Hanny Febrii ElizabethNo ratings yet
- 3 Persiapan Data MiningDocument83 pages3 Persiapan Data Miningicobes urNo ratings yet
- Romi DM 03 Persiapan Mar2016Document82 pagesRomi DM 03 Persiapan Mar2016Tri Indah SariNo ratings yet
- 03 PreprocessingDocument42 pages03 Preprocessinghawariya abelNo ratings yet
- 20210913115526D3708 - Session 02-04 Getting To Know Your Data Data Pre-ProcessingDocument64 pages20210913115526D3708 - Session 02-04 Getting To Know Your Data Data Pre-ProcessingAnthony HarjantoNo ratings yet
- Chapter 3 - Data Pre-Processing NotesDocument8 pagesChapter 3 - Data Pre-Processing Notestowsif.imran.dhkNo ratings yet
- Data PreprocessingDocument22 pagesData PreprocessingPrashant SharmaNo ratings yet
- DMW Mod2, AJSDocument63 pagesDMW Mod2, AJSRahul S.KumarNo ratings yet
- Lab 1Document21 pagesLab 1Lili WeiNo ratings yet
- COS10022 - Lecture 03 - Data Preparation PDFDocument61 pagesCOS10022 - Lecture 03 - Data Preparation PDFPapersdock TahaNo ratings yet
- Data PreprocessingDocument54 pagesData PreprocessingNEEL GHADIYANo ratings yet
- CSC 3301-Lecture06 Introduction To Machine LearningDocument56 pagesCSC 3301-Lecture06 Introduction To Machine LearningAmalienaHilmyNo ratings yet
- Down 2Document61 pagesDown 2pavunkumarNo ratings yet
- C11BD - W7 - Lecture 6Document66 pagesC11BD - W7 - Lecture 6chibyk okaforNo ratings yet
- CH 02 Data Preprocessing 2021Document47 pagesCH 02 Data Preprocessing 2021PRIYA RATHORENo ratings yet
- Data Pre ProcessingDocument48 pagesData Pre ProcessingjyothibellaryvNo ratings yet
- Prediction: All Topics in Scanned Copy "Adaptive Business Intelligence" by Zbigniewmichlewicz Martin Schmidt)Document46 pagesPrediction: All Topics in Scanned Copy "Adaptive Business Intelligence" by Zbigniewmichlewicz Martin Schmidt)rashNo ratings yet
- Chapter3 DataPreprocessingDocument50 pagesChapter3 DataPreprocessing01fe20bcs181No ratings yet
- Data Pre-Processing: Submitted By, R.Archana, 10ucs05 D.Gayathri, 10ucs11Document18 pagesData Pre-Processing: Submitted By, R.Archana, 10ucs05 D.Gayathri, 10ucs11subithaperiyasamyNo ratings yet
- 3 Data PreprocessingDocument33 pages3 Data PreprocessingMarcoNo ratings yet
- Final - Unit 3 Data Preprocessing - PhasesDocument42 pagesFinal - Unit 3 Data Preprocessing - PhasesJaydeep DodiyaNo ratings yet
- Data Pre-Processing Data CleaningDocument13 pagesData Pre-Processing Data CleaningTanish SaajanNo ratings yet
- Data PreparationDocument21 pagesData PreparationAbebe ChekolNo ratings yet
- Unit 2Document30 pagesUnit 2Dakshkohli31 KohliNo ratings yet
- Introduction To Data Mining: - Chapter 3Document39 pagesIntroduction To Data Mining: - Chapter 3Maya JoshiNo ratings yet
- DM 2Document41 pagesDM 2Aditya SrivastavaNo ratings yet
- L2 A Short PreprocDocument42 pagesL2 A Short PreprocShame BopeNo ratings yet
- Data Prep Roc EsDocument31 pagesData Prep Roc EsM sindhuNo ratings yet
- Class3 DataPreprocessing 21sept2020Document10 pagesClass3 DataPreprocessing 21sept2020Rajat GuptaNo ratings yet
- Lesson4 DataDocument31 pagesLesson4 DataHalah AftabNo ratings yet
- Lecture 9&10Document49 pagesLecture 9&10Steffen ColeNo ratings yet
- Jalali@mshdiua - Ac.ir Jalali - Mshdiau.ac - Ir: Machine LearningDocument35 pagesJalali@mshdiua - Ac.ir Jalali - Mshdiau.ac - Ir: Machine LearningMostafa HeidaryNo ratings yet
- Data IntegrationDocument31 pagesData IntegrationTanish SaajanNo ratings yet
- 4 - Finding and Fixing Data Quality IssuesDocument48 pages4 - Finding and Fixing Data Quality Issuesmkz01041No ratings yet
- Slide 2 - Data PreprocessingDocument39 pagesSlide 2 - Data PreprocessingLôny NêzNo ratings yet
- ML Unit-IiDocument100 pagesML Unit-IiSupriya alluriNo ratings yet
- Data Pre Processing - NGDocument43 pagesData Pre Processing - NGVatesh_Pasrija_9573No ratings yet
- DataMining SDocument103 pagesDataMining SBarsha RoyNo ratings yet
- Data Pre-Processing: Overview & Data Cleaning: Data Warehouse and MiningDocument20 pagesData Pre-Processing: Overview & Data Cleaning: Data Warehouse and MiningShubham SharmaNo ratings yet
- ICS 2408 - Lecture 2 - Data PreprocessingDocument29 pagesICS 2408 - Lecture 2 - Data Preprocessingpetergitagia9781No ratings yet
- Data PreprocessingDocument12 pagesData PreprocessingPrashant SahuNo ratings yet
- Unit 2: Data Warehousing & Data MiningDocument58 pagesUnit 2: Data Warehousing & Data MiningartemisNo ratings yet
- CortanaDocument5 pagesCortanaAseel JameelNo ratings yet
- Internet Gateway Best Practice Security PolicyDocument52 pagesInternet Gateway Best Practice Security Policyalways_redNo ratings yet
- BSC6900 Boards 3G PDFDocument10 pagesBSC6900 Boards 3G PDFSarimSomalyNo ratings yet
- InternshipDocument12 pagesInternshipmillenium sankhlaNo ratings yet
- Optimized Adec Genset 03.2007 eDocument49 pagesOptimized Adec Genset 03.2007 eFERNANDO INOCENTE TRINIDAD GUERRA100% (1)
- Sellos PDFDocument8 pagesSellos PDFchuylemalo1990No ratings yet
- DBMS Unit - 3Document46 pagesDBMS Unit - 3logunaathanNo ratings yet
- pcDuino+User+Guide+Rev +0 4Document35 pagespcDuino+User+Guide+Rev +0 4Lourival Ziviani JuniorNo ratings yet
- 3CX VoIP Telephone, Phone SystemDocument18 pages3CX VoIP Telephone, Phone SystemRob Bliss Telephone, Phone System SpecialistNo ratings yet
- Fallen London Tier-3 Cross-Conversion Action CalculatorDocument14 pagesFallen London Tier-3 Cross-Conversion Action Calculatorthrowaway-alt20No ratings yet
- Docker k8s LabDocument81 pagesDocker k8s Labbobwillmore100% (1)
- Itil v3 A Pocket GuideDocument23 pagesItil v3 A Pocket Guideiraguz1No ratings yet
- Ch15Crypto6e Userauth Nemo2Document43 pagesCh15Crypto6e Userauth Nemo2highway2prakasNo ratings yet
- Data MiningDocument55 pagesData Miningnehakumari55115No ratings yet
- Lab 3: EIGRP: TopologyDocument7 pagesLab 3: EIGRP: TopologyJair VelasquezNo ratings yet
- Camara Dahua Ip MODELO DH-IPC-HFW1100SN-0600BDocument6 pagesCamara Dahua Ip MODELO DH-IPC-HFW1100SN-0600BBellorin CesarNo ratings yet
- Flash Tutorial Falling StarsDocument12 pagesFlash Tutorial Falling Starspayeh89No ratings yet
- InteliMonitor-2.2 - ManualDocument50 pagesInteliMonitor-2.2 - ManualRODRIGO_RALONo ratings yet
- NAC2500 SOC User ManualDocument66 pagesNAC2500 SOC User ManualUlises Caiceros Caiceros100% (1)
- Cocoon HD Camera Pen Manual AV6185Document20 pagesCocoon HD Camera Pen Manual AV6185Apollo RajkumarNo ratings yet
- Sysmac Studio 3D Simulation Function Operation Manual 202208Document206 pagesSysmac Studio 3D Simulation Function Operation Manual 202208Nurdeny PribadiNo ratings yet
- 2022-01-01 How Much Longer Can Computing Power Drive Artificial Intelligence Progress (CSET)Document34 pages2022-01-01 How Much Longer Can Computing Power Drive Artificial Intelligence Progress (CSET)DDNo ratings yet
- Ultimate Guide Network Observability Kentik 083023Document36 pagesUltimate Guide Network Observability Kentik 083023ecrivezadanielNo ratings yet
- Unlock Hidden Menu in Phoenix BIOS Setup Menu TutorialDocument10 pagesUnlock Hidden Menu in Phoenix BIOS Setup Menu TutorialSuper-Senior Pranksters100% (1)
- Procedure For Law Enforcement RequestsDocument15 pagesProcedure For Law Enforcement RequestsWallaNo ratings yet
- Hands-On Automation Testing With Java For Beginner...Document148 pagesHands-On Automation Testing With Java For Beginner...Vijay AroraNo ratings yet
- MoaiProjectSetup PDFDocument14 pagesMoaiProjectSetup PDFsdfasdfkksfjNo ratings yet
- SRVCC Feature AUDIT - MSSDocument3 pagesSRVCC Feature AUDIT - MSSsinghal_shalendraNo ratings yet
- Python Theory QuestionsDocument2 pagesPython Theory QuestionsSandhya Rani ChagamreddyNo ratings yet
- Analytics - Magellan: An OverviewDocument25 pagesAnalytics - Magellan: An OverviewAditya Mohan GoelNo ratings yet