You might also like
- Introduction To Panel Data AnalysisDocument18 pagesIntroduction To Panel Data Analysissmazadamha sulaimanNo ratings yet
- Lec06 - Panel DataDocument160 pagesLec06 - Panel DataTung NguyenNo ratings yet
- Assignment QuantitativeDocument6 pagesAssignment Quantitativehoneyverma3010No ratings yet
- Panel Data StataDocument16 pagesPanel Data StataAneeza KhanNo ratings yet
- 04-16-Simple-RegressionDocument47 pages04-16-Simple-RegressionWAWAN HERMAWANNo ratings yet
- Intro EconometricsDocument64 pagesIntro Econometricswajidshahsw1No ratings yet
- Lecture NoteDocument77 pagesLecture Notehaile ethioNo ratings yet
- Ch11 SlidesDocument49 pagesCh11 SlidesFarah AliNo ratings yet
- Factor Analysis: Dr. R. RavananDocument22 pagesFactor Analysis: Dr. R. Ravananajay kalangiNo ratings yet
- Unit 4 Factor, Discriminant, Conjoint, Innovation-DiffusionDocument88 pagesUnit 4 Factor, Discriminant, Conjoint, Innovation-Diffusionkomalkataria2003No ratings yet
- Nature of Regression AnalysisDocument22 pagesNature of Regression Analysiswhoosh2008No ratings yet
- Regression Analysis in Business AnalyticsDocument14 pagesRegression Analysis in Business AnalyticsUsama NajamNo ratings yet
- By: Domodar N. Gujarati: Prof. M. El-SakkaDocument22 pagesBy: Domodar N. Gujarati: Prof. M. El-SakkaaraNo ratings yet
- Chapter 3-Numerical MeasuresDocument38 pagesChapter 3-Numerical MeasuresNadia TanzeemNo ratings yet
- Guj - Econometrics Ch01 The Nature of Regression AnalysisDocument22 pagesGuj - Econometrics Ch01 The Nature of Regression AnalysisHafiz Dzaky RadithyaNo ratings yet
- Factor Analysis 19-3-20Document21 pagesFactor Analysis 19-3-20Jim100% (1)
- Panel DataDocument5 pagesPanel Datasaeed meo100% (2)
- BCS-DS-602: Machine Learning: Dr. Sarika Chaudhary Associate Professor Fet-CseDocument18 pagesBCS-DS-602: Machine Learning: Dr. Sarika Chaudhary Associate Professor Fet-CseAnonmity worldNo ratings yet
- MIT Graduate Labor Economics 14.662 Spring 2015 Note 2: Job Loss and Job Search at The Micro and Macro LevelDocument19 pagesMIT Graduate Labor Economics 14.662 Spring 2015 Note 2: Job Loss and Job Search at The Micro and Macro Levelarati.kundu.1943No ratings yet
- SykesDocument5 pagesSykesAfifNo ratings yet
- Fixed and Random EffectsDocument23 pagesFixed and Random EffectsAzizNo ratings yet
- Irrational ExuberanceDocument6 pagesIrrational ExuberancehP6I4EM2CXNo ratings yet
- Conditional Logit ApplicabilityDocument5 pagesConditional Logit ApplicabilitySujit ChauhanNo ratings yet
- Chapter 1-Introduction To EconometricsDocument16 pagesChapter 1-Introduction To EconometricsMuliana SamsiNo ratings yet
- Data Science PresentationDocument113 pagesData Science PresentationDHEEVIKA SURESH100% (2)
- What Do Data on Millions of U.S. Workers Reveal about Life-Cycle Earnings RiskDocument71 pagesWhat Do Data on Millions of U.S. Workers Reveal about Life-Cycle Earnings RiskPippoNo ratings yet
- Chapter 14 Advanced Panel Data Methods: T T Derrorterm Complicate X yDocument13 pagesChapter 14 Advanced Panel Data Methods: T T Derrorterm Complicate X ydsmile1No ratings yet
- Econometrics ProjectDocument17 pagesEconometrics ProjectAkash ChoudharyNo ratings yet
- EconometricsDocument18 pagesEconometrics迪哎No ratings yet
- 4 - Initial Analysis - DimensionalityDocument70 pages4 - Initial Analysis - DimensionalityNavid GodilNo ratings yet
- Public Economics: Chikako Yamauchi Assistant Professor, GRIPS "Tools of Positive Analysis" Rosen & Gayer, Ch. 2Document42 pagesPublic Economics: Chikako Yamauchi Assistant Professor, GRIPS "Tools of Positive Analysis" Rosen & Gayer, Ch. 2Rabindra PaudyalNo ratings yet
- 7-Multiple RegressionDocument17 pages7-Multiple Regressionحاتم سلطانNo ratings yet
- By: Domodar N. Gujarati: Prof. M. El-SakkaDocument22 pagesBy: Domodar N. Gujarati: Prof. M. El-SakkaKashif KhurshidNo ratings yet
- Econometrics in Managerial EconomicsDocument160 pagesEconometrics in Managerial EconomicsMayank ChaturvediNo ratings yet
- Dadm Module 2Document11 pagesDadm Module 2aditya devaNo ratings yet
- Descriptive StatisticsDocument5 pagesDescriptive Statisticsapi-472656698No ratings yet
- Research What Is Research?Document72 pagesResearch What Is Research?arbab buttNo ratings yet
- Mathematical Modeling 4.1 Student PDFDocument118 pagesMathematical Modeling 4.1 Student PDFErikaNo ratings yet
- Factor AnalysisDocument32 pagesFactor AnalysisSapan AnandNo ratings yet
- Factor AnalysisDocument32 pagesFactor AnalysisSapan AnandNo ratings yet
- Ch10 Slides .Econometrics - MBADocument32 pagesCh10 Slides .Econometrics - MBABITEW MEKONNENNo ratings yet
- Cointegration & Error Correlation ModelDocument16 pagesCointegration & Error Correlation ModelVarun VaishnavNo ratings yet
- Final Paper Guide For PS, Spring : e Source File For This Document Is Not Yet Available atDocument13 pagesFinal Paper Guide For PS, Spring : e Source File For This Document Is Not Yet Available atjake bowersNo ratings yet
- Pension StudyDocument10 pagesPension StudyJon OrtizNo ratings yet
- ExamDocument3 pagesExampedromfr97No ratings yet
- How Much Should We Trust Differences in DifferenceDocument32 pagesHow Much Should We Trust Differences in Differencejayjam_scribdNo ratings yet
- Lesson 04Document5 pagesLesson 04kavishka ubeysekaraNo ratings yet
- Chapter2 FMLDocument33 pagesChapter2 FMLSaquibh ShaikhNo ratings yet
- Bien doc lap - The relationship between class size and educational outcomesDocument49 pagesBien doc lap - The relationship between class size and educational outcomesThương NguyễnNo ratings yet
- Introduction To Econometrics: Basics of Regression Analysis Anoop SasikumarDocument16 pagesIntroduction To Econometrics: Basics of Regression Analysis Anoop Sasikumaranoop sasiNo ratings yet
- ReportDocument5 pagesReport王大锤No ratings yet
- Returns-Earnings Regressions: An Integrated Approach: Ebartov@stern - Nyu.eduDocument58 pagesReturns-Earnings Regressions: An Integrated Approach: Ebartov@stern - Nyu.eduwirodihardjoNo ratings yet
- Analytics Roles - Possible Questions: Use CasesDocument13 pagesAnalytics Roles - Possible Questions: Use CasesShaikh Ahsan AliNo ratings yet
- Assumptions For Regression Analysis: MGMT 230: Introductory StatisticsDocument3 pagesAssumptions For Regression Analysis: MGMT 230: Introductory StatisticsPoonam NaiduNo ratings yet
- Chapter Four - Linear RegressionDocument17 pagesChapter Four - Linear Regressionismail adanNo ratings yet
- (2021) EC6041 Lecture 1 Intro NotesDocument9 pages(2021) EC6041 Lecture 1 Intro NotesG.Edward GarNo ratings yet
- Budgetind Concepts and Forecoasting TechniquesDocument26 pagesBudgetind Concepts and Forecoasting TechniquesajithsubramanianNo ratings yet
- Multiple Linear Regression ModelDocument99 pagesMultiple Linear Regression Modelbrianmfula2021No ratings yet
- Regression Analysis Explained in 40 StepsDocument39 pagesRegression Analysis Explained in 40 StepsT ShrinnityaNo ratings yet
- NoSQL Lab FatDocument46 pagesNoSQL Lab FatVarun VaishnavNo ratings yet
- Forecasting ModelsDocument13 pagesForecasting ModelsVarun VaishnavNo ratings yet
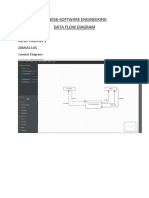
- 20mia1145 Cse3036 DFDDocument2 pages20mia1145 Cse3036 DFDVarun VaishnavNo ratings yet
- Time Series AnalysisDocument36 pagesTime Series AnalysisVinayakaNo ratings yet
- 20MIA1145 CSE3036 Labassign2Document1 page20MIA1145 CSE3036 Labassign2Varun VaishnavNo ratings yet
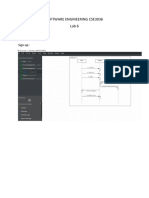
- 20mia1145 Cse3036 Lab6Document2 pages20mia1145 Cse3036 Lab6Varun VaishnavNo ratings yet
- 20MIA1145 CSE3036 Labassign1Document2 pages20MIA1145 CSE3036 Labassign1Varun VaishnavNo ratings yet
- ASSIGNMENT 4 LSMDocument5 pagesASSIGNMENT 4 LSMVarun VaishnavNo ratings yet
- Dbms Assignment: 20MIA1145 Varun VaishnavDocument19 pagesDbms Assignment: 20MIA1145 Varun VaishnavVarun VaishnavNo ratings yet
- Rabin Karp Algorithm: 20mia1145 Varun VaishnavDocument13 pagesRabin Karp Algorithm: 20mia1145 Varun VaishnavVarun VaishnavNo ratings yet
- Os Lab Test 4: Varun Vaishnav 20MIA1145 CodeDocument3 pagesOs Lab Test 4: Varun Vaishnav 20MIA1145 CodeVarun VaishnavNo ratings yet
- MBAS901 2 LectureDocument87 pagesMBAS901 2 LectureSabinaNo ratings yet
- Borges Et Al (2018)Document10 pagesBorges Et Al (2018)Edjane FreitasNo ratings yet
- GE 105 SyllabusDocument5 pagesGE 105 SyllabusJohn Paul BantaotaoNo ratings yet
- SMMD Credit Risk Project AnalysisDocument3 pagesSMMD Credit Risk Project AnalysisAmar ParulekarNo ratings yet
- Regression ANOVADocument42 pagesRegression ANOVAJamal AbdullahNo ratings yet
- Polyfit PDFDocument5 pagesPolyfit PDFdarafehNo ratings yet
- Econometria: exemplos Bário Wooldridge p.390Document14 pagesEconometria: exemplos Bário Wooldridge p.390Adriano Marcos Rodrigues FigueiredoNo ratings yet
- Oversikt ECN402Document40 pagesOversikt ECN402Mathias VindalNo ratings yet
- Repeatability Standard DeviationDocument6 pagesRepeatability Standard DeviationBalram JiNo ratings yet
- 2005 Proverbs TOM SchizophreniaDocument7 pages2005 Proverbs TOM SchizophreniaKatsiaryna HurbikNo ratings yet
- BBBCDocument12 pagesBBBCDenise Wu0% (2)
- ANOVA and Regression AnalysisDocument8 pagesANOVA and Regression Analysis21P410 - VARUN MNo ratings yet
- 7739 PDFDocument67 pages7739 PDFEmad EmadNo ratings yet
- Box, Wetz Technical Report PDFDocument95 pagesBox, Wetz Technical Report PDFluciaf_alves8542No ratings yet
- Cluster Analysis - Ward's MethodDocument6 pagesCluster Analysis - Ward's Methodraghu_sbNo ratings yet
- Lab Report Constant AcclerationDocument6 pagesLab Report Constant Acclerationacxyvb0% (1)
- Physics - Third EditionDocument584 pagesPhysics - Third EditionLujaina Hesham100% (2)
- A Rank-Invariant Method of Linear and Polynomial Regression AnalysisDocument37 pagesA Rank-Invariant Method of Linear and Polynomial Regression AnalysisY YNo ratings yet
- Final Term Paper 3Document21 pagesFinal Term Paper 3Stanley NgacheNo ratings yet
- Tutorial TheoryOfErrorsDocument4 pagesTutorial TheoryOfErrorsnaaventhenNo ratings yet
- 001Document17 pages001Husein NasutionNo ratings yet
- SSC201/202 Quantitative Analysis Statistics Data CollectionDocument163 pagesSSC201/202 Quantitative Analysis Statistics Data CollectionPippahNo ratings yet
- Heather Walen-Frederick SPSS HandoutDocument13 pagesHeather Walen-Frederick SPSS HandoutSamvedna ShirsatNo ratings yet
- Econ 251 PS3 Solutions v2Document18 pagesEcon 251 PS3 Solutions v2Peter ShangNo ratings yet
- Revisiting Feldstein-Horioka Puzzle: Evidence From SAARC EconomiesDocument21 pagesRevisiting Feldstein-Horioka Puzzle: Evidence From SAARC EconomiesDr. Pabitra Kumar MishraNo ratings yet
- The Influence of Celebrity Endorsers and Product Reviews On Shopee Consumers' Buying Interest in Palembang CityDocument7 pagesThe Influence of Celebrity Endorsers and Product Reviews On Shopee Consumers' Buying Interest in Palembang CityInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Annual Reviews in Control: Dominique Sauter, Mohamed Amine Sid, Samir Aberkane, Didier MaquinDocument12 pagesAnnual Reviews in Control: Dominique Sauter, Mohamed Amine Sid, Samir Aberkane, Didier MaquinsidamineNo ratings yet
- Six Sigma Tools in A Excel SheetDocument23 pagesSix Sigma Tools in A Excel SheetjohnavramNo ratings yet
- Marketing Research Report Group 1 Ib LjdivbDocument15 pagesMarketing Research Report Group 1 Ib LjdivbParv PandyaNo ratings yet