You might also like
- Argumentative Essay: QuickStudy Digital Reference Guide to Planning, Researching, and WritingFrom EverandArgumentative Essay: QuickStudy Digital Reference Guide to Planning, Researching, and WritingRating: 2 out of 5 stars2/5 (1)
- Testing of HypothesisDocument8 pagesTesting of HypothesisAnurag ChandelNo ratings yet
- Chapter 7 Single Sample TestingDocument110 pagesChapter 7 Single Sample TestingMobasher MessiNo ratings yet
- Intro To Hypothesis TestingDocument83 pagesIntro To Hypothesis TestingrahulrockonNo ratings yet
- Hypothesis Testing NotesDocument62 pagesHypothesis Testing NotesBu-Hilal Alsuwaidi89% (9)
- Hypothesis Testing NotesDocument62 pagesHypothesis Testing NotesmbapritiNo ratings yet
- Probability, Statistics and Random Processes: Hypothesis Testing-1Document58 pagesProbability, Statistics and Random Processes: Hypothesis Testing-1AjayMeenaNo ratings yet
- Hypothesis Testing & Decision Making under UncertaintyDocument3 pagesHypothesis Testing & Decision Making under UncertaintyBibek GiriNo ratings yet
- Chapter3 - 2Document54 pagesChapter3 - 2Hafzal Gani67% (3)
- Statistical Hypothesis Testing ExplainedDocument32 pagesStatistical Hypothesis Testing ExplainedAbhishekNo ratings yet
- Chapter Three - Hypothess TestingDocument20 pagesChapter Three - Hypothess TestingWasif ImranNo ratings yet
- CH 3Document14 pagesCH 3Wudneh AmareNo ratings yet
- Chapter 5 (Part I)Document79 pagesChapter 5 (Part I)Natasha GhazaliNo ratings yet
- Read Pages 537 - 551.: Section 9.1 Reading Guide: Significant Test The BasicsDocument5 pagesRead Pages 537 - 551.: Section 9.1 Reading Guide: Significant Test The BasicsGilbert Coolkid ReynoNo ratings yet
- Hypothesis Testing and Errors in Hypothesis: Dr. Abdur RasheedDocument29 pagesHypothesis Testing and Errors in Hypothesis: Dr. Abdur RasheedSafi SheikhNo ratings yet
- Test of HypothesisDocument31 pagesTest of HypothesisJaspreet KaurNo ratings yet
- Introduction to Hypothesis TestingDocument3 pagesIntroduction to Hypothesis Testingjonnydeep1970virgilio.itNo ratings yet
- de 6 Dca 404 CDocument31 pagesde 6 Dca 404 CFarrukh JamilNo ratings yet
- 8 Hypothesis Testing - Describing A Single PopulationDocument107 pages8 Hypothesis Testing - Describing A Single PopulationChuyên Mai TấtNo ratings yet
- MGMT 222 Ch. V-1Document30 pagesMGMT 222 Ch. V-1Asteway Mesfin100% (1)
- Unit 3 - Hypothesis TestingDocument17 pagesUnit 3 - Hypothesis TestingminalNo ratings yet
- Fundamental of Hypothesis Testing - Edited 2021Document23 pagesFundamental of Hypothesis Testing - Edited 2021Rodin PaspasanNo ratings yet
- AP SHAH ADS Notes Mod 2 p2Document50 pagesAP SHAH ADS Notes Mod 2 p2sabeveg221No ratings yet
- Hypothesis Testing ExplainedDocument16 pagesHypothesis Testing Explainedtemedebere100% (1)
- The Null Hypothesis Contains A Condition of Equality:, , orDocument3 pagesThe Null Hypothesis Contains A Condition of Equality:, , orDiksha JangidNo ratings yet
- Topic 5 - HypothesisDocument57 pagesTopic 5 - Hypothesisamedeuce lyatuuNo ratings yet
- ACCTY 312 - Lesson 4Document9 pagesACCTY 312 - Lesson 4shsNo ratings yet
- Lect Hypothesis TestingDocument29 pagesLect Hypothesis TestingDeepti GangwalNo ratings yet
- Types of Errors: Score ProjectDocument8 pagesTypes of Errors: Score ProjectJetonNo ratings yet
- Module Two: Measuring Uncertainty and Drawing Conclusions About Populations Based On Sample DataDocument39 pagesModule Two: Measuring Uncertainty and Drawing Conclusions About Populations Based On Sample DataRamesh paiNo ratings yet
- MIT15 075JF11 chpt06cDocument4 pagesMIT15 075JF11 chpt06cElyaas JanNo ratings yet
- Chapter 3=HTDocument20 pagesChapter 3=HTmuslim yasinNo ratings yet
- Lecture Note - Week 4Document18 pagesLecture Note - Week 4josephNo ratings yet
- Ba Lecture 9Document26 pagesBa Lecture 9sheikh.59265No ratings yet
- RM Unit3 SlidesDocument172 pagesRM Unit3 Slidesrheasudheer.19No ratings yet
- Lecture Notes 8A Testing of HypothesisDocument11 pagesLecture Notes 8A Testing of HypothesisFrendick Legaspi100% (1)
- QMMDocument54 pagesQMMgladwin thomasNo ratings yet
- Unit 7Document9 pagesUnit 7Adam wondwoseNo ratings yet
- Statistical Analysis in Finance Session 4: Hypothesis TestingDocument32 pagesStatistical Analysis in Finance Session 4: Hypothesis TestingPRIYADARSHI GOURAVNo ratings yet
- 30 - Hypothesis Testing Intro To T-Tests (Sep2018)Document59 pages30 - Hypothesis Testing Intro To T-Tests (Sep2018)Rahul JajuNo ratings yet
- Questions Decisions For Example: " " Hypothesis TestingDocument8 pagesQuestions Decisions For Example: " " Hypothesis TestingLaylaNo ratings yet
- Module 4 - Hypothesis Testing - Summary Concepts in Hypothesis Testing IDocument21 pagesModule 4 - Hypothesis Testing - Summary Concepts in Hypothesis Testing IshahadNo ratings yet
- Unit 2Document36 pagesUnit 2JuanNo ratings yet
- Research Methods ExplainedDocument17 pagesResearch Methods Explainedersaini83No ratings yet
- Lecture Notes - Hypothesis TestingDocument17 pagesLecture Notes - Hypothesis TestingSushant SumanNo ratings yet
- Introduction To Hypothesis TestingDocument36 pagesIntroduction To Hypothesis TestingRakesh Mohan SaxenaNo ratings yet
- Handout 12. Chapter 8.4: Testing Hypotheses About A Population Mean M (Large Samples)Document8 pagesHandout 12. Chapter 8.4: Testing Hypotheses About A Population Mean M (Large Samples)Cordel FernandoNo ratings yet
- Hypothesis TestingDocument65 pagesHypothesis TestingAdhy popzNo ratings yet
- Statistical Inference GuideDocument36 pagesStatistical Inference GuideSherlcok HolmesNo ratings yet
- Hypothesis Testing: Key Concepts, Examples and StepsDocument74 pagesHypothesis Testing: Key Concepts, Examples and StepsAmit Kumar AroraNo ratings yet
- SW Review - Inferential - Research-2Document112 pagesSW Review - Inferential - Research-2Naila DannNo ratings yet
- Chapter 2 Hypothesis TestingDocument43 pagesChapter 2 Hypothesis TestingMario M. Ramon100% (7)
- Fundamentals of Hypothesis TestingDocument27 pagesFundamentals of Hypothesis TestingMadhav SharmaNo ratings yet
- Hypothesis Testing Significance LectureDocument22 pagesHypothesis Testing Significance Lectureesraa m hassanNo ratings yet
- Hypothesis Testing-SharedDocument56 pagesHypothesis Testing-SharedVangara HarishNo ratings yet
- Hypothesis TestingDocument57 pagesHypothesis TestingDarling SelviNo ratings yet
- Understanding Statistical Hypothesis TestingDocument25 pagesUnderstanding Statistical Hypothesis TestingzaogamerNo ratings yet
- Hypothesis Testing - IDocument36 pagesHypothesis Testing - Isai revanthNo ratings yet
- ENGDATA (10) - Hypothesis TestingDocument87 pagesENGDATA (10) - Hypothesis TestingTereseAnchetaNo ratings yet
- Astm C11Document8 pagesAstm C11Fitria RindangNo ratings yet
- Transfer Taxes and Basic SuccessionDocument59 pagesTransfer Taxes and Basic SuccessionARC SVIORNo ratings yet
- Calculation of Drug Dosages A Work Text 10th Edition Ogden Test Bank DownloadDocument8 pagesCalculation of Drug Dosages A Work Text 10th Edition Ogden Test Bank Downloadupwindscatterf9ebp100% (26)
- Business Math - Interest QuizDocument1 pageBusiness Math - Interest QuizAi ReenNo ratings yet
- Man 040 0001Document42 pagesMan 040 0001arturo tuñoque effioNo ratings yet
- CS 70 Discrete Mathematics and Probability Theory Spring 2016 Rao and Walrand Note 2 1 ProofsDocument8 pagesCS 70 Discrete Mathematics and Probability Theory Spring 2016 Rao and Walrand Note 2 1 ProofsAyesha NayyerNo ratings yet
- China's Lenovo: A Case Study in Competitiveness and Global SuccessDocument3 pagesChina's Lenovo: A Case Study in Competitiveness and Global SuccessIlse Torres100% (2)
- Topics in English SyntaxDocument131 pagesTopics in English SyntaxPro GamerNo ratings yet
- National Drinking Water Quality StandardDocument26 pagesNational Drinking Water Quality Standardiffah nazira100% (2)
- CH 6 SandwichesDocument10 pagesCH 6 SandwichesKrishna ChaudharyNo ratings yet
- Install 13 SEER condensing unitDocument9 pagesInstall 13 SEER condensing unitalfredoNo ratings yet
- Terms of Reference: Mataasnakahoy Senior High SchoolDocument13 pagesTerms of Reference: Mataasnakahoy Senior High SchoolAngelica LindogNo ratings yet
- Membuat Kunci Identifikasi Tipe Perbandingan Kartu Berlubang (Body-Punched Card Key)Document4 pagesMembuat Kunci Identifikasi Tipe Perbandingan Kartu Berlubang (Body-Punched Card Key)Aditya SuryaNo ratings yet
- ZDocument6 pagesZDinesh SelvakumarNo ratings yet
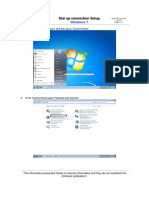
- Windows 7 Dial-Up Connection Setup GuideDocument7 pagesWindows 7 Dial-Up Connection Setup GuideMikeNo ratings yet
- 0809 KarlsenDocument5 pages0809 KarlsenprateekbaldwaNo ratings yet
- NTSE MAT Maharashtra 2011Document38 pagesNTSE MAT Maharashtra 2011Edward FieldNo ratings yet
- Adrenergic SystemDocument6 pagesAdrenergic SystemdocsNo ratings yet
- Dual Band DAB Pocket Radio: User Manual Manuel D'utilisation Manual Del Usuario Benutzerhandbuch GebruikershandleidingDocument21 pagesDual Band DAB Pocket Radio: User Manual Manuel D'utilisation Manual Del Usuario Benutzerhandbuch Gebruikershandleidingminerva_manNo ratings yet
- CBSE Class 8 Mathematics Ptactice WorksheetDocument1 pageCBSE Class 8 Mathematics Ptactice WorksheetArchi SamantaraNo ratings yet
- sr20 Switchingsystems080222Document20 pagessr20 Switchingsystems080222Daniel BholahNo ratings yet
- Upper Limb OrthosisDocument47 pagesUpper Limb OrthosisPraneethaNo ratings yet
- Criminal Law 2 - TreasonDocument408 pagesCriminal Law 2 - TreasonInna SalongaNo ratings yet
- Understanding Cash and Cash EquivalentsDocument6 pagesUnderstanding Cash and Cash EquivalentsNicole Anne Santiago SibuloNo ratings yet
- Tests On Educational Interest and Its ImpactDocument2 pagesTests On Educational Interest and Its ImpactSusan BenedictNo ratings yet
- Saipem - FdsDocument8 pagesSaipem - FdsWaldemar100% (1)
- Chapter OneDocument18 pagesChapter Oneحيدر محمدNo ratings yet
- Codex AlexandrinusDocument294 pagesCodex AlexandrinusHevel Cava100% (2)
- Seven Tips For Surviving R: John Mount Win Vector LLC Bay Area R Users Meetup October 13, 2009 Based OnDocument15 pagesSeven Tips For Surviving R: John Mount Win Vector LLC Bay Area R Users Meetup October 13, 2009 Based OnMarco A SuqorNo ratings yet
- "Disaster Readiness and Risk Reduction": Test 2 True or FalseDocument2 pages"Disaster Readiness and Risk Reduction": Test 2 True or FalseMiki AntonNo ratings yet