You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5814)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1092)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (844)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (348)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Econ 1000 - Test 3Document176 pagesEcon 1000 - Test 3Akram SaiyedNo ratings yet
- Top Linux Monitoring ToolsDocument38 pagesTop Linux Monitoring ToolsRutch ChintamasNo ratings yet
- Managerial Economics PDFDocument110 pagesManagerial Economics PDFSean Lester S. NombradoNo ratings yet
- PPP Book 2018Document176 pagesPPP Book 2018dyahlalitaNo ratings yet
- Getting Started Clock Repair-Dual-TranslatedDocument160 pagesGetting Started Clock Repair-Dual-Translatedgolin627No ratings yet
- Question Bank of Managerial Economics - 4 MarkDocument23 pagesQuestion Bank of Managerial Economics - 4 MarklakkuMS100% (4)
- Fuel Oil Operations and Bunkering Notification ProcedureDocument4 pagesFuel Oil Operations and Bunkering Notification ProcedureiomerkoNo ratings yet
- Undangan Seminar Internasional 2021-DikonversiDocument4 pagesUndangan Seminar Internasional 2021-DikonversiJandi PermadiNo ratings yet
- Skylab 3 Press Conferences and Briefings 4 of 4Document225 pagesSkylab 3 Press Conferences and Briefings 4 of 4Bob AndrepontNo ratings yet
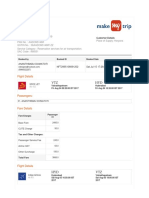
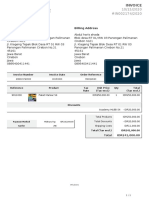
- NF72995106691202 InvoiceDocument3 pagesNF72995106691202 Invoicereddi.demullu007No ratings yet
- Material Safety Data SheetDocument31 pagesMaterial Safety Data SheetDito Anggriawan PrasetyoNo ratings yet
- CLASS 9 Computer BenevolenceDocument3 pagesCLASS 9 Computer BenevolenceFARHAN KAMALNo ratings yet
- Industrial Disputes Act, 1947Document83 pagesIndustrial Disputes Act, 1947Arjoo BakliwalNo ratings yet
- Pseudohypoparathyroidism-Literature Update 2018Document8 pagesPseudohypoparathyroidism-Literature Update 2018radu nicolaeNo ratings yet
- Htadd3w enDocument25 pagesHtadd3w enkivijakolaNo ratings yet
- Aa10 DS enDocument4 pagesAa10 DS enMuhammadRahadianBarnadibNo ratings yet
- User Manual C1KS-C3KSDocument35 pagesUser Manual C1KS-C3KSCong100% (1)
- Flowserve CV PDFDocument36 pagesFlowserve CV PDFAlvin SmithNo ratings yet
- EEE150 CHAPTER 1 Introduction To Occupational Safety and Health LegislationDocument59 pagesEEE150 CHAPTER 1 Introduction To Occupational Safety and Health LegislationMUHAMMAD LUKMAN ARSHADNo ratings yet
- Functions Polyfit (MATLAB®)Document3 pagesFunctions Polyfit (MATLAB®)zhee_pirateNo ratings yet
- Pesticide Spraying Agricultural RobotDocument5 pagesPesticide Spraying Agricultural RobotPremier Publishers100% (1)
- Spain FinalDocument20 pagesSpain Finalherman_j_tan8405No ratings yet
- Garden Trowel, A Tool With A Pointed, Scoop-Shaped Metal Blade and WoodenDocument2 pagesGarden Trowel, A Tool With A Pointed, Scoop-Shaped Metal Blade and WoodenCrisanta Marie100% (1)
- In002174 2020Document1 pageIn002174 2020Bagus DaraNo ratings yet
- MERC - Boxed Set (FGU 8301)Document50 pagesMERC - Boxed Set (FGU 8301)Gabriella Belt80% (5)
- Module 6Document3 pagesModule 6Jenn AmaroNo ratings yet
- Personal InformationDocument12 pagesPersonal InformationNetwork CrowdNo ratings yet
- Interview With Warren BuffettDocument2 pagesInterview With Warren BuffettAdii BoaaNo ratings yet
- Air Transportation PDFDocument60 pagesAir Transportation PDFKhải NguyễnNo ratings yet
- சோழர் வரலாறுDocument353 pagesசோழர் வரலாறுsenguvelanNo ratings yet