You might also like
- Top Secrets Of Excel Dashboards: Save Your Time With MS ExcelFrom EverandTop Secrets Of Excel Dashboards: Save Your Time With MS ExcelRating: 5 out of 5 stars5/5 (1)
- NNpredDocument74 pagesNNpredClaudio Zanotti100% (2)
- LinestDocument6 pagesLinestMayankNo ratings yet
- Minitab Simple Regression AnalysisDocument7 pagesMinitab Simple Regression AnalysisRadu VasileNo ratings yet
- Minitab DOE Tutorial PDFDocument32 pagesMinitab DOE Tutorial PDFnmukherjee20100% (3)
- Correlation and Simple Linear Regression Problems With Solutions PDFDocument34 pagesCorrelation and Simple Linear Regression Problems With Solutions PDFiqbaltaufiqur rochmanNo ratings yet
- Final Demo LPDocument7 pagesFinal Demo LPChebel LiedrugNo ratings yet
- The Practically Cheating Statistics Handbook TI-83 Companion GuideFrom EverandThe Practically Cheating Statistics Handbook TI-83 Companion GuideRating: 3.5 out of 5 stars3.5/5 (3)
- The Role of Planning and Forcasting in Business OrganizationDocument73 pagesThe Role of Planning and Forcasting in Business Organizationmuriski4live_174951087% (15)
- Data Science Vs Machine Learning Vs Data AnalyticsDocument13 pagesData Science Vs Machine Learning Vs Data AnalyticsSupraj Kumar100% (1)
- SPSS Estimating Percentile RanksDocument6 pagesSPSS Estimating Percentile RanksDonald StephenNo ratings yet
- S Pss Example T TestsDocument3 pagesS Pss Example T TestsEssenzo FerdiNo ratings yet
- Prism 6 - T TestDocument7 pagesPrism 6 - T TestoschlepNo ratings yet
- X Bar&RchartDocument9 pagesX Bar&RchartPramod AthiyarathuNo ratings yet
- Chapter 1 Fundamental Concepts SPSS - Descriptive StatisticsDocument4 pagesChapter 1 Fundamental Concepts SPSS - Descriptive StatisticsAvinash AmbatiNo ratings yet
- Calculating and Displaying Regression Statistics in ExcelDocument4 pagesCalculating and Displaying Regression Statistics in Exceldickson phiriNo ratings yet
- Preliminary Analysis: - Descriptive Statistics. - Checking The Reliability of A ScaleDocument92 pagesPreliminary Analysis: - Descriptive Statistics. - Checking The Reliability of A ScaleslezhummerNo ratings yet
- Prism 6 - Linear Standard CurveDocument7 pagesPrism 6 - Linear Standard CurveoschlepNo ratings yet
- Eviews TutorialDocument5 pagesEviews Tutoriallifeblue2No ratings yet
- Minitab CheatDocument9 pagesMinitab Cheatwaqas104No ratings yet
- Chapter 6 Normal Distibutions: Graphs of Normal Distributions (Section 6.1 of UnderstandableDocument8 pagesChapter 6 Normal Distibutions: Graphs of Normal Distributions (Section 6.1 of UnderstandableAsiongMartinez12No ratings yet
- SPSS Eda 16Document14 pagesSPSS Eda 16Irfan HussainNo ratings yet
- Presentation 2Document34 pagesPresentation 2Zeleke GeresuNo ratings yet
- Data: Excel Guide: Correlation & Regression ExampleDocument4 pagesData: Excel Guide: Correlation & Regression ExampleRehan ShinwariNo ratings yet
- SPSS 16.0 Tutorial To Develop A Regression ModelDocument12 pagesSPSS 16.0 Tutorial To Develop A Regression ModelSatwant SinghNo ratings yet
- Sas Notes Module 4-Categorical Data Analysis Testing Association Between Categorical VariablesDocument16 pagesSas Notes Module 4-Categorical Data Analysis Testing Association Between Categorical VariablesNISHITA MALPANI100% (1)
- SPSSDocument30 pagesSPSShimadri.roy8469No ratings yet
- Handout On Statistical Analysis in Excel 2 1Document16 pagesHandout On Statistical Analysis in Excel 2 1EJ GonzalesNo ratings yet
- Basic Correlation and RegressionDocument4 pagesBasic Correlation and RegressionSindh Jobs HelperNo ratings yet
- Quick and Dirty Regression TutorialDocument6 pagesQuick and Dirty Regression TutorialStefan Pius DsouzaNo ratings yet
- Mann-Whitney Rank Sum Test in SPSS: STAT 314Document3 pagesMann-Whitney Rank Sum Test in SPSS: STAT 314Daniela BadeaNo ratings yet
- Sensitivity Sample Model: Tornado, Spider and Sensitivity Charts (Nonlinear)Document6 pagesSensitivity Sample Model: Tornado, Spider and Sensitivity Charts (Nonlinear)cajimenezb8872No ratings yet
- Using MS-Excel To Analyze Data: Lab 2 - Chemical Properties in Water Phosphorus SulphurDocument5 pagesUsing MS-Excel To Analyze Data: Lab 2 - Chemical Properties in Water Phosphorus SulphurLaaiba IshaaqNo ratings yet
- Descriptive Statistics DeCastroRoseshel UntalanLezyl 1Document15 pagesDescriptive Statistics DeCastroRoseshel UntalanLezyl 1Cecille UntalanNo ratings yet
- Graphs and Charts PDFDocument8 pagesGraphs and Charts PDFAnonymous w5Hnew1rONo ratings yet
- Lesson 2Document22 pagesLesson 2camilleescote562No ratings yet
- SPSS Tutorial: - How To Do A Chi SquareDocument4 pagesSPSS Tutorial: - How To Do A Chi SquareJoe AndaNo ratings yet
- How To Calculate Descriptive Statistics For Variables in SPSS - StatologyDocument12 pagesHow To Calculate Descriptive Statistics For Variables in SPSS - Statologyvu thu thuong hoangNo ratings yet
- 2 DescriptiveDocument9 pages2 DescriptiveAli IshaqNo ratings yet
- Data Tutorial: Tutorial On Types of Graphs Used For Data Analysis, Along With How To Enter Them in MS ExcelDocument22 pagesData Tutorial: Tutorial On Types of Graphs Used For Data Analysis, Along With How To Enter Them in MS ExcelplantpowerNo ratings yet
- Two-Way ANOVA With Post Tests: Entering and Graphing The DataDocument6 pagesTwo-Way ANOVA With Post Tests: Entering and Graphing The DataThuý SmilerNo ratings yet
- Ref For Your Assig PDFDocument3 pagesRef For Your Assig PDFKit Meng LimNo ratings yet
- SPSS Brief GuideDocument7 pagesSPSS Brief GuideRubayath Namibur RazzakNo ratings yet
- Excel Directions For Cost Behavior ProjectDocument4 pagesExcel Directions For Cost Behavior ProjectSharif UsmanNo ratings yet
- Graphing How-To HelpDocument3 pagesGraphing How-To HelpAaronNo ratings yet
- Test For Two Relates SamplesDocument48 pagesTest For Two Relates SamplesMiqz ZenNo ratings yet
- Test For Two Relates SamplesDocument48 pagesTest For Two Relates SamplesMiqz ZenNo ratings yet
- Presentation of Data: Tables and Graphs: Table Construction Using WordDocument7 pagesPresentation of Data: Tables and Graphs: Table Construction Using WordJoseph AsisNo ratings yet
- Graphs and Tables 07 and 10Document7 pagesGraphs and Tables 07 and 10Joseph AsisNo ratings yet
- Use of SPSS For Two-Way TestsDocument4 pagesUse of SPSS For Two-Way TestsNurun NabiNo ratings yet
- Excel Regression Instructions 2010Document3 pagesExcel Regression Instructions 2010kim1003No ratings yet
- Descriptive Statistics Excel - StataDocument37 pagesDescriptive Statistics Excel - StataAnushrut MNo ratings yet
- Statistics: 1.3 The Chi-Squared Test For Two-Way Tables: Rosie Shier. 2004Document4 pagesStatistics: 1.3 The Chi-Squared Test For Two-Way Tables: Rosie Shier. 2004JJwilliamNo ratings yet
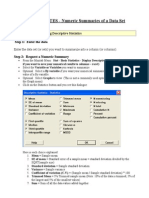
- Minitab HELP NOTES - Numeric Summaries of A Data Set: Step 1: Enter The DataDocument4 pagesMinitab HELP NOTES - Numeric Summaries of A Data Set: Step 1: Enter The DataBilly AnugrahNo ratings yet
- A New Graphic For One-Way ANOVA: Data-Based Contrasts. Indeed, There Appears To Be One Distinctive Approach ToDocument12 pagesA New Graphic For One-Way ANOVA: Data-Based Contrasts. Indeed, There Appears To Be One Distinctive Approach ToEdwin Johny Asnate SalazarNo ratings yet
- Graphing Data and Curve FittingDocument5 pagesGraphing Data and Curve Fittinggrp38No ratings yet
- HW1 ExcelBasicsDocument9 pagesHW1 ExcelBasicsShams ZubairNo ratings yet
- Using Matlab IdentDocument19 pagesUsing Matlab IdentneoflashNo ratings yet
- Instructions For Using WinplotDocument38 pagesInstructions For Using WinplotClaudia MuñozNo ratings yet
- SPSS Workshop: Utilizing and Implementing SPSS in Our OC-Math Statistics ClassesDocument11 pagesSPSS Workshop: Utilizing and Implementing SPSS in Our OC-Math Statistics Classesgura1999No ratings yet
- JMP Ttest Anova ExamplesDocument8 pagesJMP Ttest Anova ExamplesAjibola AladeNo ratings yet
- Chapter 11 - History MatchingDocument14 pagesChapter 11 - History MatchingBilal AmjadNo ratings yet
- Abuse 2Document8 pagesAbuse 2saravananNo ratings yet
- Vignesh Mhatre Competancy MappingDocument227 pagesVignesh Mhatre Competancy MappingVignesh MhatreNo ratings yet
- Discourse Analysis As Social Construction: Towards Greater Integration of Approaches and MethodsDocument27 pagesDiscourse Analysis As Social Construction: Towards Greater Integration of Approaches and MethodsRauhaa SalamNo ratings yet
- Ethnography in Accounting Research: Anis ChaririDocument55 pagesEthnography in Accounting Research: Anis ChaririSugiantoNo ratings yet
- BDM Curriculum 1665047518017Document2 pagesBDM Curriculum 1665047518017syedNo ratings yet
- TIC ++ BCG-Testing-Inspection-and-Certification-Go-Digital-Dec-2018 - tcm9-209878Document6 pagesTIC ++ BCG-Testing-Inspection-and-Certification-Go-Digital-Dec-2018 - tcm9-209878ugo_rossiNo ratings yet
- Demand Metrics Excel TemplateDocument14 pagesDemand Metrics Excel TemplateumeshjmangroliyaNo ratings yet
- A Review of Industrial Engineering Techn PDFDocument8 pagesA Review of Industrial Engineering Techn PDFHdzertos6156No ratings yet
- Module in Practical Research 2: Your Lesson For Today!Document20 pagesModule in Practical Research 2: Your Lesson For Today!Ana Kristelle Grace SyNo ratings yet
- Functions and ApplicationsDocument30 pagesFunctions and Applicationslala landNo ratings yet
- Session 1Document5 pagesSession 1PANDURU KRANTHI KUMAR ce16b007No ratings yet
- DAHILOG - Statistics Activity 1Document5 pagesDAHILOG - Statistics Activity 1Ybur Clieve Olsen DahilogNo ratings yet
- Slides Prepared by John S. Loucks St. Edward's UniversityDocument59 pagesSlides Prepared by John S. Loucks St. Edward's UniversityVũ NguyễnNo ratings yet
- Forecasting ProblemDocument5 pagesForecasting ProblemSamdeesh SinghNo ratings yet
- GROUP IV-Written ReportDocument21 pagesGROUP IV-Written ReportCarla Dela Rosa AbalosNo ratings yet
- ChemStation WorkflowDocument44 pagesChemStation WorkflowNarongchai PongpanNo ratings yet
- Mulusew Proposal 2Document20 pagesMulusew Proposal 2Kalkidan Daniel100% (1)
- OB Article Review assignment-ORDocument3 pagesOB Article Review assignment-ORkebede desalegnNo ratings yet
- MSW 1234 Sem Course October 2018 - FINAL CorrectedDocument90 pagesMSW 1234 Sem Course October 2018 - FINAL CorrectedAnanta Chalise100% (1)
- Simran Singh, Big Data End Term AssignmentDocument6 pagesSimran Singh, Big Data End Term AssignmentKARISHMA RAJNo ratings yet
- PROGRAMME: Bachelor Business Administration (Hons) SEMESTER: BADB3024 - Research Methods LECTURER: DR Sharrifah Binti AliDocument58 pagesPROGRAMME: Bachelor Business Administration (Hons) SEMESTER: BADB3024 - Research Methods LECTURER: DR Sharrifah Binti Aliyoyohoney singleNo ratings yet
- PVT - 3-Minute Smartphone-Based and Tablet-Based Psychomotor Vigilance Tests For The Assessment of Reduced Alertness Due To Sleep Deprivation PDFDocument10 pagesPVT - 3-Minute Smartphone-Based and Tablet-Based Psychomotor Vigilance Tests For The Assessment of Reduced Alertness Due To Sleep Deprivation PDFJosé Rafael CampinoNo ratings yet
- PR2 - DLL Week 1Document3 pagesPR2 - DLL Week 1Nimrod CabreraNo ratings yet
- AN004 - Data Analysis TechniquesDocument4 pagesAN004 - Data Analysis TechniquesPoomba TimmonNo ratings yet
- 2yj S4CLD2302 BPD en XXDocument13 pages2yj S4CLD2302 BPD en XXlukasDBNo ratings yet
- Data Analysis Qualitative ResearchDocument28 pagesData Analysis Qualitative ResearchCiedelle Honey Lou DimaligNo ratings yet