You might also like
- T24 Architecture: Libyan Qatari BankDocument34 pagesT24 Architecture: Libyan Qatari BankKrishna100% (1)
- Node.js Design Patterns - Second EditionFrom EverandNode.js Design Patterns - Second EditionRating: 3.5 out of 5 stars3.5/5 (2)
- Mobile Product ManagementDocument36 pagesMobile Product ManagementAmalia Pirvanescu100% (1)
- SST ManualDocument346 pagesSST ManualGtoi Gondang-watumalangNo ratings yet
- Service Oriented ArchitectureDocument86 pagesService Oriented ArchitectureAkshay BagdiNo ratings yet
- Java RMI, RMI Tunneling and Web Services Comparison and Performance AnalysisDocument8 pagesJava RMI, RMI Tunneling and Web Services Comparison and Performance AnalysisAman HirphoNo ratings yet
- 9ib DNSRVDocument51 pages9ib DNSRVapi-3831209No ratings yet
- WebservdesignDocument64 pagesWebservdesignapi-3829446No ratings yet
- Expose An Stateless Session Bean As A Web ServiceDocument20 pagesExpose An Stateless Session Bean As A Web Serviceviveksingh21csNo ratings yet
- Chapter16 Web Services - PublishDocument9 pagesChapter16 Web Services - PublishLinh LinhNo ratings yet
- Performance Evaluation of Java RmiDocument20 pagesPerformance Evaluation of Java RmiSamuel Streaming IdowuNo ratings yet
- Load Balancing Using Remote Method Invocation (JAVA RMI)Document6 pagesLoad Balancing Using Remote Method Invocation (JAVA RMI)surendiran123No ratings yet
- MCA Grid Computing NotesDocument6 pagesMCA Grid Computing NotesSathish kumarNo ratings yet
- Web Service CharacteristicsDocument2 pagesWeb Service CharacteristicsPercian Joseph BorjaNo ratings yet
- High Performance Java Remote Method Invocation For Parallel Computing On ClustersDocument7 pagesHigh Performance Java Remote Method Invocation For Parallel Computing On ClustersLuke NvnNo ratings yet
- SoaDocument79 pagesSoaMeghanagraj MeghaNo ratings yet
- Websphere Interview QuestionsDocument5 pagesWebsphere Interview Questions@vjNo ratings yet
- Web Service Mashup Middleware With Partitioning of XML PipelinesDocument8 pagesWeb Service Mashup Middleware With Partitioning of XML PipelinesShiny JosephineNo ratings yet
- Performance Study of Dispatching Algorithms in Multi-Tier Web ArchitecturesDocument11 pagesPerformance Study of Dispatching Algorithms in Multi-Tier Web Architecturesrakheep123No ratings yet
- Lecture4+ +Service+Oriented+ArchitectureDocument75 pagesLecture4+ +Service+Oriented+ArchitectureAmontos Edjie KentNo ratings yet
- Improving The Performance of Service-Based Applications by Dynamic Service ExecutionDocument9 pagesImproving The Performance of Service-Based Applications by Dynamic Service ExecutionLiu HongNo ratings yet
- Implementing Asynchronous Remote Method Invocation in JavaDocument11 pagesImplementing Asynchronous Remote Method Invocation in JavaPuspala ManojkumarNo ratings yet
- Documentation of Online Banking SystemDocument48 pagesDocumentation of Online Banking Systembapu230489% (9)
- SOA and Web ServicesDocument107 pagesSOA and Web ServicesAravind RadhakrishnanNo ratings yet
- 21 Privacy-Preserving and Truthful DetectionDocument12 pages21 Privacy-Preserving and Truthful DetectionahamadunnisaNo ratings yet
- Web Services SyllabusDocument3 pagesWeb Services Syllabussatish.sathya.a2012No ratings yet
- Webservice Interview QuestionsDocument5 pagesWebservice Interview QuestionsWaqar AhmedNo ratings yet
- SystemModels ds14Document49 pagesSystemModels ds14parassinghalNo ratings yet
- Architecture DesignDocument54 pagesArchitecture DesignBehind The SideNo ratings yet
- Distributed Systems Lab 1Document24 pagesDistributed Systems Lab 1Ferenc BondarNo ratings yet
- Intro To Tech StreamsDocument124 pagesIntro To Tech Streamsapi-3706175100% (1)
- Dev Articles 09/17/07 11:21:45Document5 pagesDev Articles 09/17/07 11:21:45Shraddha ModiNo ratings yet
- Oracle: Developer DayDocument16 pagesOracle: Developer DayUday KumarNo ratings yet
- What Are Web Services? Architecture, Types, ExampleDocument5 pagesWhat Are Web Services? Architecture, Types, ExampleSri Sai Degree College BobbiliNo ratings yet
- Lecture 12 (A) CSE 401Document8 pagesLecture 12 (A) CSE 401ziaul hoqNo ratings yet
- Web Design & DevelopmentDocument37 pagesWeb Design & Developmentghost 786No ratings yet
- Java Server BenchmarksDocument25 pagesJava Server BenchmarksHamid DadkhahNo ratings yet
- Q.2 Explain The Features of WCF in Detail?: List Advantage and Disadvantage of SoapDocument6 pagesQ.2 Explain The Features of WCF in Detail?: List Advantage and Disadvantage of Soapyagyesh trivediNo ratings yet
- Web Enabled Business Process - 1Document32 pagesWeb Enabled Business Process - 1Patel Rahul RajeshbhaiNo ratings yet
- Documentation Web ServicesDocument7 pagesDocumentation Web ServicessatyanarayanaNo ratings yet
- Research Report: Workload Characterization For Microservices Takanori Ueda, Takuya Nakaike, and Moriyoshi OharaDocument12 pagesResearch Report: Workload Characterization For Microservices Takanori Ueda, Takuya Nakaike, and Moriyoshi OharaEva WatiNo ratings yet
- Using OMG's Model Driven Architecture (MDA) To Integrate Web ServicesDocument9 pagesUsing OMG's Model Driven Architecture (MDA) To Integrate Web ServicesSuresh KumarNo ratings yet
- Protocols For Web Service Invocation: Christopher D. WaltonDocument6 pagesProtocols For Web Service Invocation: Christopher D. WaltontbaillysNo ratings yet
- Tuning FrmWEBDocument16 pagesTuning FrmWEBSupachai TaechapisitNo ratings yet
- Com Chapter - 5Document4 pagesCom Chapter - 5Haben etsayNo ratings yet
- Online Prediction For QoS - Zhu2017Document14 pagesOnline Prediction For QoS - Zhu2017amir.doudou07No ratings yet
- Java andDocument41 pagesJava andRavinder RajuNo ratings yet
- 1.dynamic Bandwidth Calculation:: Web ServerDocument16 pages1.dynamic Bandwidth Calculation:: Web ServerPoiod LeahdNo ratings yet
- SOAP vs. REST: Difference Between Web API ServicesDocument11 pagesSOAP vs. REST: Difference Between Web API ServicesSrikanth NalliNo ratings yet
- Web Services Quick GuideDocument13 pagesWeb Services Quick GuidefziwenNo ratings yet
- Web Services PDFDocument8 pagesWeb Services PDFSunlNo ratings yet
- Web Services: Marlon Pierce Indiana UniversityDocument23 pagesWeb Services: Marlon Pierce Indiana Universityomm123No ratings yet
- V3 Mail Server A Java ProjectDocument38 pagesV3 Mail Server A Java ProjectGurpreet SinghNo ratings yet
- Web Services RetrospectiveDocument3 pagesWeb Services RetrospectivesamirNo ratings yet
- Ryan MichaelDocument156 pagesRyan MichaelkatherineNo ratings yet
- WebsphereDocument113 pagesWebsphereragu9999No ratings yet
- Design So A With J2EEDocument8 pagesDesign So A With J2EEKeshav GuptaNo ratings yet
- 8 IJEAST Vol No.4 Issue No.1 A Clustered Web Application Server 081 088Document8 pages8 IJEAST Vol No.4 Issue No.1 A Clustered Web Application Server 081 088iserpNo ratings yet
- IBM WebSphere Portal 8: Web Experience Factory and the CloudFrom EverandIBM WebSphere Portal 8: Web Experience Factory and the CloudNo ratings yet
- R2DBC Revealed: Reactive Relational Database Connectivity for Java and JVM ProgrammersFrom EverandR2DBC Revealed: Reactive Relational Database Connectivity for Java and JVM ProgrammersNo ratings yet
- Written ExamDocument4 pagesWritten ExamNohemy Tocto100% (1)
- EDUC2220 - Lesson Plan - Aidan GarlingDocument9 pagesEDUC2220 - Lesson Plan - Aidan GarlingAidan GarlingNo ratings yet
- SAP Web IDE Personal Edition Setup and Create SAPUI5 Application For BeginnerDocument13 pagesSAP Web IDE Personal Edition Setup and Create SAPUI5 Application For BeginnerBalanathan VirupasanNo ratings yet
- Manual Placa Mae Ga 945gcmx-s2 6.6Document72 pagesManual Placa Mae Ga 945gcmx-s2 6.6luisb3toNo ratings yet
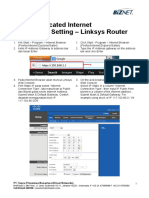
- Biznet Dedicated Internet - Connection Setting - Linksys Router PDFDocument4 pagesBiznet Dedicated Internet - Connection Setting - Linksys Router PDFIsmail AdNo ratings yet
- Presentation DCSDocument89 pagesPresentation DCSMohamed BalbaaNo ratings yet
- DH IPC HDBW2231R ZS S2 Datasheet 190910 PDFDocument3 pagesDH IPC HDBW2231R ZS S2 Datasheet 190910 PDFMelyssa MottaNo ratings yet
- Symantec™ Protection Engine For Cloud Services 8.1 Getting Started GuideDocument12 pagesSymantec™ Protection Engine For Cloud Services 8.1 Getting Started GuideRobertFeneaNo ratings yet
- Automation and Integration of SAP GUI For Users and DevelopersDocument2 pagesAutomation and Integration of SAP GUI For Users and Developersscribd_sucks_donkeydNo ratings yet
- Eapp Peta #2 - MortelDocument13 pagesEapp Peta #2 - MortelAna Carmela MortelNo ratings yet
- AD and DNSDocument22 pagesAD and DNSsmile2meguysNo ratings yet
- Bitdefender Total Security 2014 License Key Till 2016 - Picocent - Contribute With Less Than A Cent PDFDocument5 pagesBitdefender Total Security 2014 License Key Till 2016 - Picocent - Contribute With Less Than A Cent PDFNugiec13No ratings yet
- AOL Frequently Asked QuestionsDocument19 pagesAOL Frequently Asked QuestionsAbhinav GonuguntlaNo ratings yet
- Keterangan BebasidDocument2 pagesKeterangan BebasidRheeza ElhaqNo ratings yet
- Integrity AnnotatedDocument52 pagesIntegrity AnnotatedXantares OntarioNo ratings yet
- 11 170218032320Document65 pages11 170218032320Jessa EvangelistaNo ratings yet
- Huawei UMTS Parameter Most ImportantDocument495 pagesHuawei UMTS Parameter Most ImportantHarsha Nath Jha100% (2)
- A Brief History of FacebookDocument2 pagesA Brief History of FacebookraipereiNo ratings yet
- Murder For Hire REDACTEDDocument45 pagesMurder For Hire REDACTEDJ RohrlichNo ratings yet
- TSB 2012 009 O (Download)Document5 pagesTSB 2012 009 O (Download)david0young_2No ratings yet
- Base para SaulDocument7 pagesBase para Saulpaul pcNo ratings yet
- HiPath Xpressions Compact V3.0 DLI Administrator ManualDocument22 pagesHiPath Xpressions Compact V3.0 DLI Administrator ManualenjoythedocsNo ratings yet
- Organizational Behavior - Leadership in The Digital AgeDocument8 pagesOrganizational Behavior - Leadership in The Digital AgeVincent StuhlenNo ratings yet
- Kerberos Authentication With Oracle JDBC Thin Driver and Microsoft Active DirectoryDocument26 pagesKerberos Authentication With Oracle JDBC Thin Driver and Microsoft Active DirectoryEdwin VillaltaNo ratings yet
- Reading Comprehension Test 16Document5 pagesReading Comprehension Test 16mouchkilhadaNo ratings yet
- TR WMX 58 XX DatasheetDocument2 pagesTR WMX 58 XX DatasheetcristhianNo ratings yet
- S2750&S5700&S6700 V200R003 (C00&C02&C10) Log Reference 07Document1,287 pagesS2750&S5700&S6700 V200R003 (C00&C02&C10) Log Reference 07franc3No ratings yet
- ReleaseDocument5 pagesReleaseharshad12345No ratings yet