You might also like
- Microsoft Office 2010 Free Download Full VersionDocument1 pageMicrosoft Office 2010 Free Download Full Versionliznah100% (2)
- DSP Project2Document7 pagesDSP Project2Gunjan KhutNo ratings yet
- Some Simple Manipulations of Sound Using Digital Signal Processing Richard M. SternDocument14 pagesSome Simple Manipulations of Sound Using Digital Signal Processing Richard M. SternBensaad AbdellahNo ratings yet
- Modeling and SimulationDocument74 pagesModeling and SimulationdigibloodNo ratings yet
- InfThe Rev PDFDocument12 pagesInfThe Rev PDFAmol BhatkarNo ratings yet
- mc166 - Kompend - fp03 - e - DIAGR OPTIONALEDocument25 pagesmc166 - Kompend - fp03 - e - DIAGR OPTIONALEgryzzlyNo ratings yet
- Advanced DSP 1Document56 pagesAdvanced DSP 1Gajendran RaoNo ratings yet
- Filter DesignDocument8 pagesFilter DesignDONE AND DUSTEDNo ratings yet
- BSP Lab 2Document6 pagesBSP Lab 2Sameera WaseemNo ratings yet
- Laporan DSP Bab 8Document6 pagesLaporan DSP Bab 8RagaPradanaSetyawanNo ratings yet
- Obeticholic Acid FORM C-Crystaline Form XRDDocument3 pagesObeticholic Acid FORM C-Crystaline Form XRDmagugurgelNo ratings yet
- DC Error Correcting CodesDocument770 pagesDC Error Correcting CodesARAVINDNo ratings yet
- Coursera Instrumental Analysis: Linear Regression - Example 1Document19 pagesCoursera Instrumental Analysis: Linear Regression - Example 1ahmed ismailNo ratings yet
- By Samik Dutta, Somnath Chatterjee, Ranjan Sen CMERI DurgapurDocument15 pagesBy Samik Dutta, Somnath Chatterjee, Ranjan Sen CMERI DurgapurSamik DuttaNo ratings yet
- DC Lab Manual Cycle3Document11 pagesDC Lab Manual Cycle3Kavya M NayakNo ratings yet
- Lab Assignment 4 POCSDocument7 pagesLab Assignment 4 POCSZabeehullahmiakhailNo ratings yet
- Lab Assignment 4 POCSDocument7 pagesLab Assignment 4 POCSZabeehullahmiakhailNo ratings yet
- Exp 5 Hall EffectDocument7 pagesExp 5 Hall EffectKowsona ChakrabortyNo ratings yet
- Zone Nearest Fault Line Soil Profile Type Seismic Source TypeDocument6 pagesZone Nearest Fault Line Soil Profile Type Seismic Source TypeDaniel DichosoNo ratings yet
- TP AssociationDocument18 pagesTP AssociationDraw SmailNo ratings yet
- Features: WWW - Domin.co - Uk +44 (0) 1761 252650 Info@domin - Co.ukDocument4 pagesFeatures: WWW - Domin.co - Uk +44 (0) 1761 252650 Info@domin - Co.uk只要香菜No ratings yet
- CLIMATOL 3.1.1: Homogenization Graphic Output of Pmax 1980 2015Document16 pagesCLIMATOL 3.1.1: Homogenization Graphic Output of Pmax 1980 2015Cris Quea PomaNo ratings yet
- Metode Analisis Geofisika Ii: "Proses Filter Fir (Lowpass, Bandpass, Dan Highpass) Data Angin"Document20 pagesMetode Analisis Geofisika Ii: "Proses Filter Fir (Lowpass, Bandpass, Dan Highpass) Data Angin"wln_chanNo ratings yet
- Sound Level Meter - Conversion ChartDocument1 pageSound Level Meter - Conversion ChartBabak WSP GroupNo ratings yet
- 0 From: in (1) From: in (2) : Bode DiagramDocument9 pages0 From: in (1) From: in (2) : Bode DiagramAbhijeet BhagavatulaNo ratings yet
- Example:1: A.Circular Shift: All AllDocument28 pagesExample:1: A.Circular Shift: All AllJarin TasnimNo ratings yet
- AC Lab Manual PDFDocument55 pagesAC Lab Manual PDFShreyas S RNo ratings yet
- Reaction OrderDocument2 pagesReaction OrderAbdul Aziz TamamiNo ratings yet
- Session 13Document15 pagesSession 13PRIYADARSHI PANKAJNo ratings yet
- Sai Madhan. K: Mca - Semester 1 REGISTER NO: 190951144Document31 pagesSai Madhan. K: Mca - Semester 1 REGISTER NO: 190951144MadhanNo ratings yet
- Syauqi - Nano Silika - Sampel 5 - 1273.nsz Measurement ResultsDocument3 pagesSyauqi - Nano Silika - Sampel 5 - 1273.nsz Measurement ResultsAhmad FarhanNo ratings yet
- Digital Representation of Audio InformationDocument22 pagesDigital Representation of Audio InformationYuaris ArhamNo ratings yet
- B2 V3.TPDDocument11 pagesB2 V3.TPDMacp63 cpNo ratings yet
- Microammeter DesignDocument155 pagesMicroammeter DesignVictor Andres Medrano DiazNo ratings yet
- Implementation of 1-D Contourlet Transform in Matlab: BITS PilaniDocument14 pagesImplementation of 1-D Contourlet Transform in Matlab: BITS PilaniJai SidharthNo ratings yet
- Barra Simple TraccionadaDocument1 pageBarra Simple Traccionadawillys8No ratings yet
- ESSS Acceptance Report TU02531DDocument200 pagesESSS Acceptance Report TU02531DRavi KumarNo ratings yet
- Audio Coding: Ketan Mayer-PatelDocument35 pagesAudio Coding: Ketan Mayer-PatelArial96No ratings yet
- Sap DesignDocument1 pageSap DesignReza ErmawanNo ratings yet
- ETEK Modular Products 2021 1Document107 pagesETEK Modular Products 2021 10403DƯƠNG ĐỨC ĐẠMNo ratings yet
- Yum YumDocument2 pagesYum YumSurbhi KambojNo ratings yet
- Introduction To Telecommunication: Chris RoeloffzenDocument23 pagesIntroduction To Telecommunication: Chris Roeloffzenuma_maduraiNo ratings yet
- Exercises 2Document6 pagesExercises 2Dimitris JiannelisNo ratings yet
- Digital Signal ProcessingDocument2 pagesDigital Signal ProcessingKarthik SivaNo ratings yet
- PB Arang Aktif 11032020 BDocument2 pagesPB Arang Aktif 11032020 BSiti Sarifa YusuffNo ratings yet
- 2sa733lt1 PDFDocument6 pages2sa733lt1 PDFsamsul hadiNo ratings yet
- CrossoverDocument6 pagesCrossoverELECRONICA REDIMTCELNo ratings yet
- Technical Data Sheet 1206 Package Phototransistor With Inner LensDocument10 pagesTechnical Data Sheet 1206 Package Phototransistor With Inner LenschauNo ratings yet
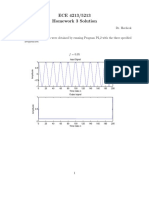
- ECE 4213/5213 Homework 3 Solution: Fall 2020 Dr. HavlicekDocument10 pagesECE 4213/5213 Homework 3 Solution: Fall 2020 Dr. Havliceksohail aminNo ratings yet
- Filter Pasif Harmonik: Z Z + Z (0 - j100) + (0 + j100) 0Document4 pagesFilter Pasif Harmonik: Z Z + Z (0 - j100) + (0 + j100) 0Fario Teje TillNo ratings yet
- Target Timer Count Target Frequency Input Frequency PrescalerDocument2 pagesTarget Timer Count Target Frequency Input Frequency PrescalerVane R. LermaNo ratings yet
- High Resolution Low Cost ADC. Made Possible by The Chips That Integrate Both Analog and Digital CircuitryDocument13 pagesHigh Resolution Low Cost ADC. Made Possible by The Chips That Integrate Both Analog and Digital Circuitrymhd kdaimatiNo ratings yet
- DSP manual-KIOTDocument62 pagesDSP manual-KIOTTalemaNo ratings yet
- AnalisaDocument6 pagesAnalisajokowisNo ratings yet
- SAPDesign - Barra Simplemente Sometida A FlexionDocument1 pageSAPDesign - Barra Simplemente Sometida A FlexionWilson ZeplinNo ratings yet
- Pulse ShappingDocument45 pagesPulse ShappingKarthik GowdaNo ratings yet
- Supplementary MaterialDocument7 pagesSupplementary MaterialInigo JohnsonNo ratings yet
- Soln StudyProblems MT IIDocument6 pagesSoln StudyProblems MT IIemirdurmaz200131No ratings yet
- Computer Graphics (CSE 4103)Document34 pagesComputer Graphics (CSE 4103)Atik Israk LemonNo ratings yet
- Quantitative Analysis - Ii Numericals Solution Using Tora & Ms ExcelDocument4 pagesQuantitative Analysis - Ii Numericals Solution Using Tora & Ms ExcelMax CharadvaNo ratings yet
- Essay Task Types: With Stephen WalkerDocument10 pagesEssay Task Types: With Stephen WalkerctadventuresinghNo ratings yet
- The Theory of Finite Dimensional Vector Spaces: 4.1 Some Basic ConceptsDocument29 pagesThe Theory of Finite Dimensional Vector Spaces: 4.1 Some Basic ConceptsctadventuresinghNo ratings yet
- Focus On Language: Describing Data: With Stephen WalkerDocument22 pagesFocus On Language: Describing Data: With Stephen WalkerctadventuresinghNo ratings yet
- Great Theoretical Ideas in Computer ScienceDocument62 pagesGreat Theoretical Ideas in Computer SciencectadventuresinghNo ratings yet
- Coding For Modern Distributed Storage Systems: Part 1.: Locally Repairable CodesDocument23 pagesCoding For Modern Distributed Storage Systems: Part 1.: Locally Repairable CodesctadventuresinghNo ratings yet
- Object-Oriented Design and High-Level Programming LanguagesDocument85 pagesObject-Oriented Design and High-Level Programming LanguagesctadventuresinghNo ratings yet
- Graphs With Tiny Vector Chromatic Numbers and Huge Chromatic NumbersDocument63 pagesGraphs With Tiny Vector Chromatic Numbers and Huge Chromatic NumbersctadventuresinghNo ratings yet
- Information Retrieval Models: Vector Space Models: Chengxiang ZhaiDocument30 pagesInformation Retrieval Models: Vector Space Models: Chengxiang ZhaictadventuresinghNo ratings yet
- Orthogonal Representations and Connectivity of GraphsDocument11 pagesOrthogonal Representations and Connectivity of GraphsctadventuresinghNo ratings yet
- HCI Lect 7-Brain-Computer Interfaces For Communication in Paralysis2Document30 pagesHCI Lect 7-Brain-Computer Interfaces For Communication in Paralysis2ctadventuresinghNo ratings yet
- Enumeration Algorithms: Problems. An Enumeration Algorithm Solves An Enumeration ProblemDocument24 pagesEnumeration Algorithms: Problems. An Enumeration Algorithm Solves An Enumeration ProblemctadventuresinghNo ratings yet
- Bipartite Index Coding: Arash Saber Tehrani Alexandros G. Dimakis Michael J. NeelyDocument20 pagesBipartite Index Coding: Arash Saber Tehrani Alexandros G. Dimakis Michael J. NeelyctadventuresinghNo ratings yet
- 107 SWL 107Document7 pages107 SWL 107Juan Daniel Garcia VeigaNo ratings yet
- Dbms Lab ManualDocument43 pagesDbms Lab Manualyash ghai 387No ratings yet
- Pasword Crack - TrinityDocument10 pagesPasword Crack - TrinityDebashish Nandan100% (1)
- Elementary Linux CommandsDocument11 pagesElementary Linux CommandsFaisal Sikander Khan100% (3)
- CT4 NotesDocument7 pagesCT4 Notessldkfjglskdjfg akdfjghNo ratings yet
- Excel FormulasDocument49 pagesExcel FormulasJorge Orozco ValverdeNo ratings yet
- Excerpt From "Radical Candor" by Kim Scott.Document5 pagesExcerpt From "Radical Candor" by Kim Scott.OnPointRadio100% (2)
- Strassen's Matrix MultiplicationDocument11 pagesStrassen's Matrix Multiplicationtncbabu100% (5)
- Geometric Modeling MortensonDocument534 pagesGeometric Modeling MortensonMadhava ReddyNo ratings yet
- Verification and Validation of CFD SimulationsDocument10 pagesVerification and Validation of CFD SimulationsEddieqNo ratings yet
- Sap Table ListDocument1,302 pagesSap Table Listd-fbuser-14463043350% (4)
- Mechanical Nonlin 13.0 WS 02A Large DeflDocument15 pagesMechanical Nonlin 13.0 WS 02A Large DeflJym Genson100% (1)
- Cisco MTTR e MTBFDocument81 pagesCisco MTTR e MTBFEdson Silva AquinoNo ratings yet
- Reflections - Blockchain HackathonDocument3 pagesReflections - Blockchain HackathonElmarie SwiegelaarNo ratings yet
- (GNSS)Document5 pages(GNSS)Bianca DeacNo ratings yet
- Apple Powerbook 190, 5300Document186 pagesApple Powerbook 190, 5300czakanNo ratings yet
- Training - Forms 6iDocument209 pagesTraining - Forms 6ivinnisharmaNo ratings yet
- Clauses of The New ISO 9001:2015 StandardDocument5 pagesClauses of The New ISO 9001:2015 Standardryan wardhanaNo ratings yet
- An Introduction To Programming For HackersDocument62 pagesAn Introduction To Programming For Hackerssaahil480No ratings yet
- E2120 90002Document644 pagesE2120 90002ixcanetNo ratings yet
- Data Acquisition System For A Formula SAE Race CarDocument43 pagesData Acquisition System For A Formula SAE Race CarRodrigo Bob100% (1)
- TDMADocument4 pagesTDMANani JNo ratings yet
- Oracle Discoverer Administrator's GuideDocument590 pagesOracle Discoverer Administrator's Guidemlucian73No ratings yet
- Pengertian PACDocument1 pagePengertian PACJuris Prasetya SimanjuntakNo ratings yet
- Transition 16949 April 2016Document11 pagesTransition 16949 April 2016Juan EgaraNo ratings yet
- Sport+-+Knockout+Draw+Generator+ (16+teams) +v0 02Document32 pagesSport+-+Knockout+Draw+Generator+ (16+teams) +v0 02Ryan WalkerNo ratings yet
- Work From HomeDocument8 pagesWork From Homeraviawasthi100% (2)
- Gvahim Assembly BookDocument318 pagesGvahim Assembly Bookאראל נחוםNo ratings yet
- CQE Academy 26 Week Study Plan 1 PDFDocument5 pagesCQE Academy 26 Week Study Plan 1 PDFSiva KumarNo ratings yet