You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Low Power Out Mack mp10 mp8 mp7Document5 pagesLow Power Out Mack mp10 mp8 mp7hamilton mirandaNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Caterpillar 236D, 242D, 246D, 262D, 257D, 277D, 287D, 289D Diagrama Electrico 29 PáginasDocument29 pagesCaterpillar 236D, 242D, 246D, 262D, 257D, 277D, 287D, 289D Diagrama Electrico 29 PáginasOscar Tello86% (14)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Standard Specification For FRP Composite Utility Poles: First EditionDocument15 pagesStandard Specification For FRP Composite Utility Poles: First EditionMojtaba Mohammad PourNo ratings yet
- Aw60 40leDocument2 pagesAw60 40leSnokeX100% (1)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Lab Report 4Document7 pagesLab Report 4Ha NguyenNo ratings yet
- Front Office and Guest Safety and Security PDFDocument11 pagesFront Office and Guest Safety and Security PDFPrabhjot SinghNo ratings yet
- Operation and Maintenance Manual-C140-18 PDFDocument271 pagesOperation and Maintenance Manual-C140-18 PDFYusroni Nainggolan0% (1)
- Servlets TutorialDocument97 pagesServlets TutorialThomas SilombaNo ratings yet
- Cooper Nova Manual S280421 Part1Document14 pagesCooper Nova Manual S280421 Part1Arliel John GarboNo ratings yet
- Planning and Design of Ports and Harbours - Code of PracticeDocument18 pagesPlanning and Design of Ports and Harbours - Code of Practicevishal kumar100% (1)
- PDF TestDocument1 pagePDF TestvenniiiiNo ratings yet
- Spotting The ErrorsDocument4 pagesSpotting The ErrorsManic Basha100% (1)
- Twitter Bootstrap 3 Tutorial - Mateed EslamyDocument12 pagesTwitter Bootstrap 3 Tutorial - Mateed Eslamykitten257No ratings yet
- JavaScript NotesDocument39 pagesJavaScript NotesvenniiiiNo ratings yet
- What Is A Collections Framework?Document2 pagesWhat Is A Collections Framework?venniiiiNo ratings yet
- What Is A Collections Framework?Document2 pagesWhat Is A Collections Framework?venniiiiNo ratings yet
- SQL Integrity ConstraintsDocument2 pagesSQL Integrity ConstraintsvenniiiiNo ratings yet
- SQL Create Database StatementDocument1 pageSQL Create Database StatementvenniiiiNo ratings yet
- SQL Create Database StatementDocument1 pageSQL Create Database StatementvenniiiiNo ratings yet
- SQL Joins: Product - Id Product - Name Supplier - Name Unit - PriceDocument3 pagesSQL Joins: Product - Id Product - Name Supplier - Name Unit - PricevenniiiiNo ratings yet
- SQL CommandsDocument3 pagesSQL CommandsvenniiiiNo ratings yet
- SQL Joins: Product - Id Product - Name Supplier - Name Unit - PriceDocument3 pagesSQL Joins: Product - Id Product - Name Supplier - Name Unit - PricevenniiiiNo ratings yet
- SQL Delete Statement: Syntax To TRUNCATE A TableDocument1 pageSQL Delete Statement: Syntax To TRUNCATE A TablevenniiiiNo ratings yet
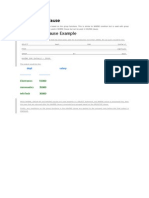
- SQL HAVING Clause ExampleDocument1 pageSQL HAVING Clause ExamplevenniiiiNo ratings yet
- HTML NotesDocument75 pagesHTML NotesvenniiiiNo ratings yet
- SQL CommandsDocument1 pageSQL CommandsvenniiiiNo ratings yet
- Syntax of SQL SELECT StatementDocument2 pagesSyntax of SQL SELECT StatementvenniiiiNo ratings yet
- SQL Views: Create View View - Name AS Select Column - List FROM Table - Name (WHERE Condition)Document1 pageSQL Views: Create View View - Name AS Select Column - List FROM Table - Name (WHERE Condition)venniiiiNo ratings yet
- SQL CommandsDocument2 pagesSQL CommandsvenniiiiNo ratings yet
- SQL CommandsDocument1 pageSQL CommandsvenniiiiNo ratings yet
- SQL CommandsDocument1 pageSQL CommandsvenniiiiNo ratings yet
- DiodeDocument2 pagesDiodevenniiiiNo ratings yet
- Use Full WebsitesDocument8 pagesUse Full WebsitesvenniiiiNo ratings yet
- Q&A ORACLE Interview Questions and AnswersDocument50 pagesQ&A ORACLE Interview Questions and AnswersvenniiiiNo ratings yet
- SQL Commands:: Syntax of SQL SELECT StatementDocument6 pagesSQL Commands:: Syntax of SQL SELECT StatementvenniiiiNo ratings yet
- Bulletin Lo 1-11Document11 pagesBulletin Lo 1-11nickopediaNo ratings yet
- 2011 Sasken Placement PaperDocument9 pages2011 Sasken Placement PapervenniiiiNo ratings yet
- HCL PaperDocument5 pagesHCL PapervenniiiiNo ratings yet
- Load ReportDocument77 pagesLoad ReportBimal DeyNo ratings yet
- CEH v8 Labs Module 02 Footprinting and ReconnaissanceDocument85 pagesCEH v8 Labs Module 02 Footprinting and ReconnaissancenazaNo ratings yet
- Quick Start - WireGuardDocument5 pagesQuick Start - WireGuardΚαωεη ΣηαδNo ratings yet
- P1568Document9 pagesP1568Luis BarretoNo ratings yet
- HMDA Building Guidelines Full Low ResDocument88 pagesHMDA Building Guidelines Full Low Resshoeb2007No ratings yet
- 3-Cable U-Ftp Cat 6a 4p X 23awg Lszh-3 500mts BARPADocument3 pages3-Cable U-Ftp Cat 6a 4p X 23awg Lszh-3 500mts BARPAMarco Antonio RubinaNo ratings yet
- Stair CalculatorDocument4 pagesStair CalculatorJun PangNo ratings yet
- Material Safety Data Sheet: 1 IdentificationDocument7 pagesMaterial Safety Data Sheet: 1 IdentificationAsad RazaNo ratings yet
- AEG HBS100 de PDFDocument32 pagesAEG HBS100 de PDFMaria MassanetNo ratings yet
- Elasticity of Solid, Liquid and Modulus of MaterialsDocument3 pagesElasticity of Solid, Liquid and Modulus of MaterialsHinata CosaNo ratings yet
- Pds 62-Sin Ds En-MeggerDocument2 pagesPds 62-Sin Ds En-MeggerAdhy PrastyoNo ratings yet
- Access - Catalog.805b.color - DP&Casing Tools-50Document1 pageAccess - Catalog.805b.color - DP&Casing Tools-50RICHARDNo ratings yet
- Scope CC 2559Document183 pagesScope CC 2559HOD Scitpl [Sands]No ratings yet
- Installation Instructions For Septic Tanks, Cesspools & Silage Tanks - Concrete SurroundDocument4 pagesInstallation Instructions For Septic Tanks, Cesspools & Silage Tanks - Concrete SurroundSteve Unwin-BoxNo ratings yet
- Intro To Inkscape Lesson 3Document6 pagesIntro To Inkscape Lesson 3api-234298405No ratings yet
- Lab Equipment Training SDocument176 pagesLab Equipment Training Sjoseph taliNo ratings yet
- Assignment TMDocument3 pagesAssignment TMBeesam Ramesh KumarNo ratings yet
- 1662 SMC Ds tcm228-701431635Document12 pages1662 SMC Ds tcm228-701431635cersanedNo ratings yet
- Lawal Habeeb Babatunde: A Seminar Report OnDocument21 pagesLawal Habeeb Babatunde: A Seminar Report OnAyinde AbiodunNo ratings yet
- Analisis de La Susmpension Con AdamsDocument18 pagesAnalisis de La Susmpension Con AdamscorsasportNo ratings yet
- 5 Heating SystemsDocument29 pages5 Heating Systemsventus13No ratings yet