You might also like
- OUTPUTDocument3 pagesOUTPUTsalekeen sakibNo ratings yet
- REGRESSION ANALYSISDocument80 pagesREGRESSION ANALYSISTerry ReynaldoNo ratings yet
- T 2 F D N: HE Actorial EsigDocument33 pagesT 2 F D N: HE Actorial EsigSaheed A BusuraNo ratings yet
- EAS Ganjil Analisis Regresi S1 2012Document1 pageEAS Ganjil Analisis Regresi S1 2012Yudisium SkuyNo ratings yet
- HW5S FL16-2Document7 pagesHW5S FL16-2alexNo ratings yet
- Regression Analysis: Model Building: Learning ObjectivesDocument38 pagesRegression Analysis: Model Building: Learning ObjectivesNayyab Alam TurjoNo ratings yet
- Sol - PQ220 6234F.Ch 11Document13 pagesSol - PQ220 6234F.Ch 11Sergio A. Florez BNo ratings yet
- Business Statistics, 5 Ed.: by Ken BlackDocument34 pagesBusiness Statistics, 5 Ed.: by Ken BlackRushabh VoraNo ratings yet
- EDADocument9 pagesEDALos BastardosNo ratings yet
- NSU Assignment AnalysisDocument9 pagesNSU Assignment AnalysisSafat ArafatNo ratings yet
- EAS Ganjil Analisis Regresi S1 2012Document1 pageEAS Ganjil Analisis Regresi S1 2012Yudisium SkuyNo ratings yet
- Decision ScienceDocument8 pagesDecision ScienceHimanshi YadavNo ratings yet
- HW 4 A 1Document11 pagesHW 4 A 1draconnoxNo ratings yet
- Student Name: Zainab Kashani Student ID: 63075: Date of Submission: Sep 16, 2020Document10 pagesStudent Name: Zainab Kashani Student ID: 63075: Date of Submission: Sep 16, 2020Zainab KashaniNo ratings yet
- General Linear Model Do MinitabDocument48 pagesGeneral Linear Model Do MinitabJose MadymeNo ratings yet
- CH 11Document76 pagesCH 11Mhmd AlKhreisatNo ratings yet
- Session - 20-Problem Set-Solution - PKDocument43 pagesSession - 20-Problem Set-Solution - PKPANKAJ PAHWANo ratings yet
- Apollo Hospital Specializes in Outpatient Surgeries For Relatively Minor ProceduresDocument3 pagesApollo Hospital Specializes in Outpatient Surgeries For Relatively Minor ProceduresElliot Richard100% (1)
- Advanced Managerial Statistics: Multiple Linear Regression Model AnalysisDocument37 pagesAdvanced Managerial Statistics: Multiple Linear Regression Model Analysisfayz_mtjkNo ratings yet
- Regression Analysis of y versus ln x1, ln x2, ln x4Document5 pagesRegression Analysis of y versus ln x1, ln x2, ln x4Willz CcorimanyaNo ratings yet
- Solution HW3Document16 pagesSolution HW3mrezzaNo ratings yet
- CH 11Document44 pagesCH 11Phía trước là bầu trờiNo ratings yet
- Ejercicio Página 16 Econometría A Través de STATADocument10 pagesEjercicio Página 16 Econometría A Través de STATAFelix MartinezNo ratings yet
- Forecasting Supply Chain Requirements: Forecast Error Squared ErrorDocument20 pagesForecasting Supply Chain Requirements: Forecast Error Squared ErrorFiorela RiveraNo ratings yet
- Econometrics Hina NazDocument17 pagesEconometrics Hina NazHina Naz (F-Name :Khadim Hussain)No ratings yet
- Capítulo 1 - Modelo Lineal de Regresión Múltiple. Hipótesis, Estimación, Inferencia y PredicciónDocument13 pagesCapítulo 1 - Modelo Lineal de Regresión Múltiple. Hipótesis, Estimación, Inferencia y PredicciónFelix MartinezNo ratings yet
- 332 4 SimpleDocument12 pages332 4 SimpleS HWNo ratings yet
- Practice Exercise RMIIDocument1 pagePractice Exercise RMIIKemale ZamanliNo ratings yet
- Solutions For Homework 4: Two-Way ANOVA: Response Versus Solution, DaysDocument13 pagesSolutions For Homework 4: Two-Way ANOVA: Response Versus Solution, DaysVIKRAM KUMARNo ratings yet
- Regression Analysis: Yi Versus XiDocument5 pagesRegression Analysis: Yi Versus XiMoner AL MgerbeNo ratings yet
- Week 2 Multiple RegressionDocument24 pagesWeek 2 Multiple Regressionafifah masromNo ratings yet
- Minitab Practical Manual 02Document6 pagesMinitab Practical Manual 02oblex99No ratings yet
- Week Two Assignment, EconometricsDocument4 pagesWeek Two Assignment, EconometricsGarimaNo ratings yet
- Business Case On Pronto PizzaDocument5 pagesBusiness Case On Pronto PizzashrutiNo ratings yet
- Regression Statistics: Output of Rocinante 36Document5 pagesRegression Statistics: Output of Rocinante 36prakhar jainNo ratings yet
- Regression Analysis: Y Versus X1, X2, X3, X4Document10 pagesRegression Analysis: Y Versus X1, X2, X3, X4deer xxxNo ratings yet
- Solutions On Stoch Inventory CH 5. (Nahmias)Document9 pagesSolutions On Stoch Inventory CH 5. (Nahmias)Jarid Medina100% (4)
- Regression Analysis: Predicting Outcomes & Interpreting ResultsDocument3 pagesRegression Analysis: Predicting Outcomes & Interpreting ResultsnoviNo ratings yet
- Metode Linear BergandaDocument16 pagesMetode Linear BergandaEka Fatihatul HikmahNo ratings yet
- Regression AnalysisDocument4 pagesRegression AnalysiskhochakNo ratings yet
- Regression Analysis of Distance with Factors A, B, C, DDocument2 pagesRegression Analysis of Distance with Factors A, B, C, DMuhammad Fauzan Ansari Bin AzizNo ratings yet
- Week 5 Multiple Regression: Busa3500 Statistics For Business Ii Piedmont CollegeDocument57 pagesWeek 5 Multiple Regression: Busa3500 Statistics For Business Ii Piedmont CollegeAlex KovalNo ratings yet
- Correlation and Regression Analysis of y, x1, x2Document2 pagesCorrelation and Regression Analysis of y, x1, x2amriNo ratings yet
- ISOM2500 Spring 2019 Assignment 4 Suggested Solution: Regression StatisticsDocument4 pagesISOM2500 Spring 2019 Assignment 4 Suggested Solution: Regression StatisticsChing Yin HoNo ratings yet
- Assignment 2 Business Statistics (BBA) Aleem Hasan & Mohib SheikhDocument8 pagesAssignment 2 Business Statistics (BBA) Aleem Hasan & Mohib SheikhAleem HasanNo ratings yet
- ZakaDocument8 pagesZakaLena HerlinaNo ratings yet
- Essentials of Chemical Reaction Engineering 1st Edition Fogler Solutions Manual Full Chapter PDFDocument42 pagesEssentials of Chemical Reaction Engineering 1st Edition Fogler Solutions Manual Full Chapter PDFJulieMorrisfazg100% (11)
- Econometric Analysis of GDP and Savings ModelsDocument2 pagesEconometric Analysis of GDP and Savings ModelsSNo ratings yet
- Data Uji Model Regresi Linier BergandaDocument6 pagesData Uji Model Regresi Linier Bergandaviki rajamudaNo ratings yet
- Time Series Analysis and ForecastingDocument5 pagesTime Series Analysis and ForecastingMusa KhanNo ratings yet
- AssignmentDocument6 pagesAssignmentakshay patriNo ratings yet
- Statistics - HighlightedDocument7 pagesStatistics - HighlightedBenNo ratings yet
- Chapter 1 Number Systems and CodesDocument57 pagesChapter 1 Number Systems and CodesJester JuarezNo ratings yet
- Des Criptive Statis TicsDocument4 pagesDes Criptive Statis TicspramantoNo ratings yet
- Business Stats Exam Review ProblemsDocument6 pagesBusiness Stats Exam Review ProblemssafNo ratings yet
- Solution Assig# 1w 08Document6 pagesSolution Assig# 1w 08mehdiNo ratings yet
- Econometrics Homework on HeteroskedasticityDocument8 pagesEconometrics Homework on HeteroskedasticityPhuong Nguyen MinhNo ratings yet
- Analysis Pre FinalDocument64 pagesAnalysis Pre FinalAbhishek ModiNo ratings yet
- Retention Debate WhitePaper UKDocument8 pagesRetention Debate WhitePaper UKAdam KhaleelNo ratings yet
- Tools of InterviewDocument7 pagesTools of InterviewXahRa MirNo ratings yet
- Enthusiasm and AttitudeDocument21 pagesEnthusiasm and AttitudeluckiemanNo ratings yet
- Proposal 02Document20 pagesProposal 02Adam KhaleelNo ratings yet
- Tools of InterviewDocument7 pagesTools of InterviewXahRa MirNo ratings yet
- Corporate Finance AssignmentDocument5 pagesCorporate Finance AssignmentJason LohNo ratings yet
- Methods TableDocument2 pagesMethods TableAdam KhaleelNo ratings yet
- Employee RetentionDocument18 pagesEmployee RetentionMunish NagarNo ratings yet
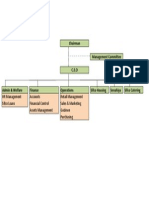
- StructureDocument1 pageStructureAdam KhaleelNo ratings yet
- Maldives SME Development ProjectDocument109 pagesMaldives SME Development ProjectAdam KhaleelNo ratings yet
- Event Sponsorship Proposal PDFDocument12 pagesEvent Sponsorship Proposal PDFRJ Zeshan AwanNo ratings yet
- Enthusiasm and AttitudeDocument21 pagesEnthusiasm and AttitudeluckiemanNo ratings yet
- Corporate Finance, Home AssignmentDocument17 pagesCorporate Finance, Home Assignmentsyedsuhail20014u8724100% (9)
- Assignments 2006Document4 pagesAssignments 2006Adam KhaleelNo ratings yet
- Ac102 ch11Document19 pagesAc102 ch11Yenny Torro100% (1)
- Ch06 In-Class Problems, - StudentDocument8 pagesCh06 In-Class Problems, - StudentAdam KhaleelNo ratings yet
- Doctor of Philosophy Rules: 1 InterpretationDocument12 pagesDoctor of Philosophy Rules: 1 InterpretationAdam KhaleelNo ratings yet
- Selected Exercises in Preparation of Question 1 On BA 6601 (Section 9) Compressive ExamDocument4 pagesSelected Exercises in Preparation of Question 1 On BA 6601 (Section 9) Compressive ExamAdam Khaleel0% (1)
- Obm PP Questions Topic Wise 2)Document4 pagesObm PP Questions Topic Wise 2)Adam KhaleelNo ratings yet
- Texas Instruments BAII PLUS Calculator TutorialDocument13 pagesTexas Instruments BAII PLUS Calculator TutorialRWS789No ratings yet
- Busi Law Ch06Document33 pagesBusi Law Ch06Adam KhaleelNo ratings yet
- Annual Report Financials 2011Document120 pagesAnnual Report Financials 2011zalNo ratings yet
- GlobalizationDocument8 pagesGlobalizationSana SiddiquiNo ratings yet
- Clean Air Asia Senior Project Coordinator Tor June2014Document3 pagesClean Air Asia Senior Project Coordinator Tor June2014Adam KhaleelNo ratings yet
- F4mys 2008 Jun ADocument9 pagesF4mys 2008 Jun AAdam KhaleelNo ratings yet
- BizDocument8 pagesBizAdam KhaleelNo ratings yet
- SOP Anti Fraud PolicyDocument14 pagesSOP Anti Fraud PolicyAdam KhaleelNo ratings yet
- Far AhDocument13 pagesFar AhFarrahh FarrahNo ratings yet
- Topic 3 - PartnershipDocument49 pagesTopic 3 - PartnershipAdam KhaleelNo ratings yet
- BizDocument10 pagesBizAdam KhaleelNo ratings yet
- Pioneer XC-L11Document52 pagesPioneer XC-L11adriangtamas1983No ratings yet
- Motor GraderDocument24 pagesMotor GraderRafael OtuboguatiaNo ratings yet
- IEEE T&D Insulators 101 Design CriteriaDocument84 pagesIEEE T&D Insulators 101 Design Criteriasachin HUNo ratings yet
- Pharmacokinetics and Drug EffectsDocument11 pagesPharmacokinetics and Drug Effectsmanilyn dacoNo ratings yet
- TILE QUOTEDocument3 pagesTILE QUOTEHarsh SathvaraNo ratings yet
- ML AiDocument2 pagesML AiSUYASH SHARTHINo ratings yet
- APLICACIONES PARA AUTOS Y CARGA LIVIANADocument50 pagesAPLICACIONES PARA AUTOS Y CARGA LIVIANApancho50% (2)
- PC3 The Sea PeopleDocument100 pagesPC3 The Sea PeoplePJ100% (4)
- Canon imageFORMULA DR-X10CDocument208 pagesCanon imageFORMULA DR-X10CYury KobzarNo ratings yet
- LKC CS Assignment2Document18 pagesLKC CS Assignment2Jackie LeongNo ratings yet
- Casio AP-80R Service ManualDocument41 pagesCasio AP-80R Service ManualEngkiong Go100% (1)
- Chain Surveying InstrumentsDocument5 pagesChain Surveying InstrumentsSachin RanaNo ratings yet
- DR-M260 User Manual ENDocument87 pagesDR-M260 User Manual ENMasa NourNo ratings yet
- Uhf Leaky Feeder Rev CDocument4 pagesUhf Leaky Feeder Rev CLuis Isaac PadillaNo ratings yet
- House Designs, QHC, 1950Document50 pagesHouse Designs, QHC, 1950House Histories100% (8)
- Elements of ClimateDocument18 pagesElements of Climateእኔ እስጥፍNo ratings yet
- 9600 DocumentDocument174 pages9600 Documentthom38% (13)
- Traffic Violation Monitoring with RFIDDocument59 pagesTraffic Violation Monitoring with RFIDShrëyãs NàtrájNo ratings yet
- Who will buy electric vehicles Segmenting the young Indian buyers using cluster analysisDocument12 pagesWho will buy electric vehicles Segmenting the young Indian buyers using cluster analysisbhasker sharmaNo ratings yet
- Chapter 10 AP GP PDFDocument3 pagesChapter 10 AP GP PDFGeorge ChooNo ratings yet
- Cost Analysis and Financial Projections for Gerbera Cultivation ProjectDocument26 pagesCost Analysis and Financial Projections for Gerbera Cultivation ProjectshroffhardikNo ratings yet
- Product ListDocument4 pagesProduct ListyuvashreeNo ratings yet
- Man Instructions PDFDocument4 pagesMan Instructions PDFAleksandar NikolovskiNo ratings yet
- Clean Milk ProductionDocument19 pagesClean Milk ProductionMohammad Ashraf Paul100% (3)
- Smart Grid Standards GuideDocument11 pagesSmart Grid Standards GuideKeyboardMan19600% (1)
- RPG-7 Rocket LauncherDocument3 pagesRPG-7 Rocket Launchersaledin1100% (3)
- Interactive Architecture Adaptive WorldDocument177 pagesInteractive Architecture Adaptive Worldhoma massihaNo ratings yet
- Concept Page - Using Vagrant On Your Personal Computer - Holberton Intranet PDFDocument7 pagesConcept Page - Using Vagrant On Your Personal Computer - Holberton Intranet PDFJeffery James DoeNo ratings yet
- Digital Communication QuestionsDocument14 pagesDigital Communication QuestionsNilanjan BhattacharjeeNo ratings yet
- SB Z Audio2Document2 pagesSB Z Audio2api-151773256No ratings yet