You might also like
- Amazing Origami Dinosaurs: Paper Dinosaurs Are Fun to Fold! (instructions for 10 Dinosaur Models + 5 Bonus Projects)From EverandAmazing Origami Dinosaurs: Paper Dinosaurs Are Fun to Fold! (instructions for 10 Dinosaur Models + 5 Bonus Projects)Shufunotomo Co. Ltd.No ratings yet
- Origami - Origami Fun!Document21 pagesOrigami - Origami Fun!ClericzNo ratings yet
- (BOS Booklets 35) Dave Venables (Editor) - Neal Elias. Miscellaneous Folds - II (Origami Book) (1990, British Origami Society) PDFDocument48 pages(BOS Booklets 35) Dave Venables (Editor) - Neal Elias. Miscellaneous Folds - II (Origami Book) (1990, British Origami Society) PDFAnonymous lmAvFvUqKNo ratings yet
- Origami GeometryDocument1 pageOrigami Geometryparisdessie0% (1)
- The Origami BookDocument45 pagesThe Origami Bookonur100% (1)
- 2 International Origami Internet Olympiad 2018 1 PDFDocument19 pages2 International Origami Internet Olympiad 2018 1 PDFRicardo IsidroNo ratings yet
- Dragon OrigamiDocument30 pagesDragon OrigamiAnonymous Jly34FNo ratings yet
- Eric Joisel The Magician of Origami PDFDocument2 pagesEric Joisel The Magician of Origami PDFAdarshNo ratings yet
- LaFosse & Alexander's Dollar Origami: Convert Your Ordinary Cash into Extraordinary Art!: Origami Book with 20 Projects & Downloadable Instructional VideoFrom EverandLaFosse & Alexander's Dollar Origami: Convert Your Ordinary Cash into Extraordinary Art!: Origami Book with 20 Projects & Downloadable Instructional VideoRating: 4.5 out of 5 stars4.5/5 (2)
- BIG-Images Ipod Origami InstructionsDocument5 pagesBIG-Images Ipod Origami InstructionsEngel ChaconNo ratings yet
- Picture Index under 40 charactersDocument6 pagesPicture Index under 40 charactersHữu TríNo ratings yet
- Origami PapiroflexiaDocument6 pagesOrigami PapiroflexiaBraulio RomeroNo ratings yet
- Ornithopter: Eileen Tan Etan@physics - Cornell.edu 17 February 2003Document8 pagesOrnithopter: Eileen Tan Etan@physics - Cornell.edu 17 February 2003987haziqNo ratings yet
- The Fold 17 Heart Puzzle by Garibi 0Document2 pagesThe Fold 17 Heart Puzzle by Garibi 0Ezra BlatzNo ratings yet
- Enterprise OrigamiDocument11 pagesEnterprise OrigamiZhenlei JiNo ratings yet
- 7A20 - Hydralisk InstructionsDocument36 pages7A20 - Hydralisk Instructionsjunkiebox101No ratings yet
- Chuka Ryu DiagramsDocument19 pagesChuka Ryu DiagramsAjit VishwakarmaNo ratings yet
- WWF Together SharkOrigamiDocument6 pagesWWF Together SharkOrigamiPPedrito123No ratings yet
- Origami Angel PDFDocument20 pagesOrigami Angel PDFewanthotNo ratings yet
- Origami SlidesDocument15 pagesOrigami Slidesdavid bernalNo ratings yet
- Origami Number & Symbol: Paper Folding Number 0 to 9 and SymbolsFrom EverandOrigami Number & Symbol: Paper Folding Number 0 to 9 and SymbolsNo ratings yet
- Origami: A Brief History of Folding PaperDocument15 pagesOrigami: A Brief History of Folding PaperEmmanuel GarcíaNo ratings yet
- Squirrel by Gen Hagiwara - Spirits of Origami PDFDocument6 pagesSquirrel by Gen Hagiwara - Spirits of Origami PDFAlfredo Giunta0% (1)
- Fluffy: by Marc Kirschenbaum (NY) ©1994Document7 pagesFluffy: by Marc Kirschenbaum (NY) ©1994gerard100% (1)
- Origami OwlDocument4 pagesOrigami Owllebalam_azhvn0% (1)
- Origami English Alphabets: Paper Folding English Alphabets Capital Letters Style 2From EverandOrigami English Alphabets: Paper Folding English Alphabets Capital Letters Style 2Rating: 5 out of 5 stars5/5 (1)
- Air and Space Origami Ebook: Paper Rockets, Airplanes, Spaceships and More! [Origami eBook]From EverandAir and Space Origami Ebook: Paper Rockets, Airplanes, Spaceships and More! [Origami eBook]No ratings yet
- Flying Dragons Paper Airplane Ebook: 48 Paper Airplanes, 64 Page Instruction Book, 12 Original Designs, YouTube Video TutorialsFrom EverandFlying Dragons Paper Airplane Ebook: 48 Paper Airplanes, 64 Page Instruction Book, 12 Original Designs, YouTube Video TutorialsNo ratings yet
- Paper Airplane Book : Learn How To Create Paper Airplanes Step By Step With This Origami Book For Kids: InterWorld Origami, #2From EverandPaper Airplane Book : Learn How To Create Paper Airplanes Step By Step With This Origami Book For Kids: InterWorld Origami, #2No ratings yet
- Origami Jungle Ebook: Create Exciting Paper Models of Exotic Animals and Tropical Plants: Origami Book with 42 Projects: Great for Kids and AdultsFrom EverandOrigami Jungle Ebook: Create Exciting Paper Models of Exotic Animals and Tropical Plants: Origami Book with 42 Projects: Great for Kids and AdultsNo ratings yet
- Ankylosaurus: by Ronald Koh (Singapore)Document7 pagesAnkylosaurus: by Ronald Koh (Singapore)angryhamstaNo ratings yet
- Fantastic Origami Sea Creatures: 20 Incredible Paper ModelsFrom EverandFantastic Origami Sea Creatures: 20 Incredible Paper ModelsRating: 2.5 out of 5 stars2.5/5 (3)
- Thefold60 Red Crowned Crane Jatusriptak 1Document5 pagesThefold60 Red Crowned Crane Jatusriptak 1Ezra Blatz100% (1)
- Origami BookDocument52 pagesOrigami BookTerrific FoldsNo ratings yet
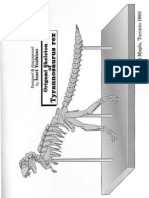
- Skeleton of Tyrannosaurus Rex - Issei YoshinoDocument74 pagesSkeleton of Tyrannosaurus Rex - Issei YoshinoDedu IonutNo ratings yet
- 2 Cranespt 1Document1 page2 Cranespt 1Djoe6897No ratings yet
- Yuka Rose Diagram 2015Document4 pagesYuka Rose Diagram 2015Alexander DimitrichenkoNo ratings yet
- Origami LightsDocument2 pagesOrigami LightsTatjana Valčić VuksanovićNo ratings yet
- Origami Instructions Com Origami Kawasaki RoseDocument3 pagesOrigami Instructions Com Origami Kawasaki RoseKaio Roberto0% (1)
- WWF Together TigerOrigami PDFDocument6 pagesWWF Together TigerOrigami PDFEsthi FebrianiNo ratings yet
- Mind-Blowing Kusudama Origami: The Art of Modular Paper FoldingFrom EverandMind-Blowing Kusudama Origami: The Art of Modular Paper FoldingNo ratings yet
- Origami Mathematics 3Document18 pagesOrigami Mathematics 3api-481408821No ratings yet
- Origami Book for Beginners 5: A Step-by-Step Introduction to the Japanese Art of Paper Folding for Kids & Adults: Origami Book For Beginners, #5From EverandOrigami Book for Beginners 5: A Step-by-Step Introduction to the Japanese Art of Paper Folding for Kids & Adults: Origami Book For Beginners, #5No ratings yet
- Easy Origami Star Christmas OrnamentDocument2 pagesEasy Origami Star Christmas OrnamentJuanNo ratings yet
- Origami Toy Monsters Kit Ebook: Easy-To-Assemble Paper Toys That Shudder, Shake, Lurch and Amaze!: Includes Origami Book with 11 Fun ProjectsFrom EverandOrigami Toy Monsters Kit Ebook: Easy-To-Assemble Paper Toys That Shudder, Shake, Lurch and Amaze!: Includes Origami Book with 11 Fun ProjectsNo ratings yet
- Roosevelt Elk: Designed by Robert J. LangDocument13 pagesRoosevelt Elk: Designed by Robert J. LangKarina Astucuri FishNo ratings yet
- Dollar Camera DIY Origami InstructionsDocument3 pagesDollar Camera DIY Origami InstructionsJuan David BermúdezNo ratings yet
- Owls CompilationDocument35 pagesOwls CompilationSirWeigel100% (1)
- Dollar Butterfly by Won Park V0.02Document3 pagesDollar Butterfly by Won Park V0.02KuteSing PittNo ratings yet
- Roman Diaz - Sparrow (Advanced) PDFDocument8 pagesRoman Diaz - Sparrow (Advanced) PDFsmelter273No ratings yet
- Baby Elephant, by Ben WalleyDocument3 pagesBaby Elephant, by Ben WalleypopakNo ratings yet
- Scaffold Origami Newsletter Vol 1 No 3Document11 pagesScaffold Origami Newsletter Vol 1 No 3jacgarperNo ratings yet
- Stag Beetle CP - Flickr - Photo Sharing!Document2 pagesStag Beetle CP - Flickr - Photo Sharing!LeonVelasquezRestrepoNo ratings yet
- Manual Yokogawa AwxDocument2 pagesManual Yokogawa Awxalexiel1806No ratings yet
- CETE 543 Earthquake Engineering Assignment RatingsDocument2 pagesCETE 543 Earthquake Engineering Assignment RatingsJenny ValderramaNo ratings yet
- Sand Dune Video Prediction Using CNNsDocument1 pageSand Dune Video Prediction Using CNNsJeffersson Ramos CamposNo ratings yet
- 1200 Buildings Program BMS Seminar 2Document39 pages1200 Buildings Program BMS Seminar 2HayanJanakat71% (7)
- Is 13365 Part4 DraftDocument15 pagesIs 13365 Part4 DraftPalak Shivhare0% (1)
- Space and Spatial Analysis in Archaeology-AnnotatedDocument433 pagesSpace and Spatial Analysis in Archaeology-AnnotatedDiofenrirNo ratings yet
- Optimization Basic ConceptsDocument5 pagesOptimization Basic Conceptsjyothis_joy8315No ratings yet
- Bourdieu FoucaultDocument33 pagesBourdieu FoucaultChristie DanielsNo ratings yet
- Grundfos Hydro MPC e Cre 32-5-2 Articulo 96941373 Motor MobDocument6 pagesGrundfos Hydro MPC e Cre 32-5-2 Articulo 96941373 Motor MobRicardo Ostos LopezNo ratings yet
- ID Analisi Framing Pemberitaan Sidang KasusDocument12 pagesID Analisi Framing Pemberitaan Sidang KasusL ANo ratings yet
- ME FinalDocument81 pagesME FinalAnkit DahiyaNo ratings yet
- Skype QRC RevisedDocument2 pagesSkype QRC RevisedJennNo ratings yet
- Mayer, Et Al (1996)Document10 pagesMayer, Et Al (1996)David John LemayNo ratings yet
- Chapter 4 and 5: Bivariate Analysis of VariablesDocument19 pagesChapter 4 and 5: Bivariate Analysis of VariablesMarta MuletNo ratings yet
- Problem 2197 64Document3 pagesProblem 2197 64Alok ChitnisNo ratings yet
- Howlings From The Pit Journal Volume I Number IV, Feb (1) - 2008, Joseph Lisiewski, 8th Matrix Press, Evocation, Old System Magic, OSMDocument34 pagesHowlings From The Pit Journal Volume I Number IV, Feb (1) - 2008, Joseph Lisiewski, 8th Matrix Press, Evocation, Old System Magic, OSMtroy_basilisk100% (6)
- 4 1 e A SoftwaremodelingintroductionvideoDocument7 pages4 1 e A Softwaremodelingintroductionvideoapi-291536844No ratings yet
- Product Presentation PowerPoint TemplatesDocument19 pagesProduct Presentation PowerPoint TemplatesTuyet PhamNo ratings yet
- SantaclaracaDocument12 pagesSantaclaracaapi-345566077No ratings yet
- BROAD CRESTED WEIR LABORATORY EXPERIMENTDocument12 pagesBROAD CRESTED WEIR LABORATORY EXPERIMENTSyafiq Roslan75% (4)
- Supervision and LeadershipDocument30 pagesSupervision and LeadershipAnonymous CeyseSDBqNo ratings yet
- Clarisse A. CVDocument2 pagesClarisse A. CVerturghsdyfilyhsaNo ratings yet
- Classical Reports in Sap ABAPDocument14 pagesClassical Reports in Sap ABAPSaswat Raysamant0% (1)
- Evolution of Kiran Mazumdar ShawDocument4 pagesEvolution of Kiran Mazumdar ShawvaithegiNo ratings yet
- Add Field in COOIS 2 SAPDocument12 pagesAdd Field in COOIS 2 SAPaprian100% (1)
- Patterns of Persuasion in The Civil Rights Struggle: Temple UniversityDocument4 pagesPatterns of Persuasion in The Civil Rights Struggle: Temple UniversityErika PhillipsNo ratings yet
- Guide to Compile JNI Code in Android StudioDocument3 pagesGuide to Compile JNI Code in Android StudioRavi BhanNo ratings yet
- Philippine MAPEH Lesson Log for Grade 4 StudentsDocument4 pagesPhilippine MAPEH Lesson Log for Grade 4 StudentsEmman Pataray CudalNo ratings yet
- Chemistry Thesis Infographics by SlidesgoDocument35 pagesChemistry Thesis Infographics by SlidesgobabithyNo ratings yet
- Astrodienst - Understanding Astrology - Advanced Astrology ArticlesDocument13 pagesAstrodienst - Understanding Astrology - Advanced Astrology ArticlesFrancesca BerettaNo ratings yet




























![Air and Space Origami Ebook: Paper Rockets, Airplanes, Spaceships and More! [Origami eBook]](https://imgv2-2-f.scribdassets.com/img/word_document/393672338/149x198/b483f9de24/1712147600?v=1)