You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- DW Olap1Document60 pagesDW Olap1jyothibellaryvNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Dice GameDocument3 pagesDice Gamejyothibellaryv100% (1)
- Solutions To DM I MID (B)Document18 pagesSolutions To DM I MID (B)jyothibellaryv100% (1)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Solutions To IV II Mid II NLP Set ADocument11 pagesSolutions To IV II Mid II NLP Set AjyothibellaryvNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Solutions To DM I MID (A)Document19 pagesSolutions To DM I MID (A)jyothibellaryv100% (1)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Solutions To IV II Mid II NLP Set BDocument10 pagesSolutions To IV II Mid II NLP Set BjyothibellaryvNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Key For Mid IDocument11 pagesKey For Mid Ijyothibellaryv100% (1)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Solutions To IV II NLP Set BDocument8 pagesSolutions To IV II NLP Set BjyothibellaryvNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- OLAP2Document53 pagesOLAP2jyothibellaryvNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Key For II Mid Dbms ADocument14 pagesKey For II Mid Dbms Ajyothibellaryv100% (1)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Solutions To NLP I Mid Set ADocument8 pagesSolutions To NLP I Mid Set Ajyothibellaryv100% (1)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Co Gate ExamDocument4 pagesCo Gate ExamjyothibellaryvNo ratings yet
- Data Pre ProcessingDocument48 pagesData Pre ProcessingjyothibellaryvNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Key For II Mid DBMS BDocument13 pagesKey For II Mid DBMS BjyothibellaryvNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Solutions To DBMS Assignment II R13Document14 pagesSolutions To DBMS Assignment II R13jyothibellaryvNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- 03 Lesson Plan DBMSDocument8 pages03 Lesson Plan DBMSjyothibellaryv100% (1)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Key For II Mid DBMS BDocument13 pagesKey For II Mid DBMS BjyothibellaryvNo ratings yet
- DBMS Book Special Notes PDFDocument68 pagesDBMS Book Special Notes PDFkvg3venu7329No ratings yet
- 03 Lesson Plan DBMS PDFDocument32,767 pages03 Lesson Plan DBMS PDFjyothibellaryvNo ratings yet
- 03 Lesson Plan DBMS PDFDocument32,767 pages03 Lesson Plan DBMS PDFjyothibellaryvNo ratings yet
- AbstractDocument1 pageAbstractjyothibellaryvNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Written TestDocument3 pagesWritten TestjyothibellaryvNo ratings yet
- DBMS 2nd CompleteDocument31 pagesDBMS 2nd CompletejyothibellaryvNo ratings yet
- 03 Lesson Plan DBMS PDFDocument32,767 pages03 Lesson Plan DBMS PDFjyothibellaryvNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- ADSA Lab ManualDocument225 pagesADSA Lab ManualjyothibellaryvNo ratings yet
- USP Unit IDocument7 pagesUSP Unit Ijyothibellaryv100% (1)
- What Is An Operating System (OS) ?: Abstract WayDocument6 pagesWhat Is An Operating System (OS) ?: Abstract WayjyothibellaryvNo ratings yet
- Welcome TO Parent Teacher AssociationDocument11 pagesWelcome TO Parent Teacher AssociationjyothibellaryvNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- CS 143 Introduction To Computer VisionDocument6 pagesCS 143 Introduction To Computer VisionjyothibellaryvNo ratings yet
- VRF Mv6R: Heat Recovery Outdoor UnitsDocument10 pagesVRF Mv6R: Heat Recovery Outdoor UnitsTony NguyenNo ratings yet
- Introductions and Basic Personal Information (In/Formal Communication)Document6 pagesIntroductions and Basic Personal Information (In/Formal Communication)juan morenoNo ratings yet
- EPA NCP Technical Notebook PDFDocument191 pagesEPA NCP Technical Notebook PDFlavrikNo ratings yet
- Applied Computational AerodynamicsDocument15 pagesApplied Computational AerodynamicsjoereisNo ratings yet
- C305 - QTO Workshop PDFDocument90 pagesC305 - QTO Workshop PDFJason SecretNo ratings yet
- Syllabus - Building Rehabilitation Anfd Forensic en - 220825 - 181244Document3 pagesSyllabus - Building Rehabilitation Anfd Forensic en - 220825 - 181244M O H A N A V E LNo ratings yet
- 234567890Document37 pages234567890erppibuNo ratings yet
- Federal Government Employees Housing FoundationDocument2 pagesFederal Government Employees Housing FoundationMuhammad Shakil JanNo ratings yet
- Day 1 Training Material FlowDocument200 pagesDay 1 Training Material FlowGhazouani AymenNo ratings yet
- Lecture 5: Triangulation Adjustment Triangulation: in This Lecture We Focus On The Second MethodDocument5 pagesLecture 5: Triangulation Adjustment Triangulation: in This Lecture We Focus On The Second MethodXogr BargarayNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- GCG Damri SurabayaDocument11 pagesGCG Damri SurabayaEndang SusilawatiNo ratings yet
- Pesud Abadi Mahakam Company Profile Abdul Basith-DikonversiDocument48 pagesPesud Abadi Mahakam Company Profile Abdul Basith-DikonversiAndi HafizNo ratings yet
- Quizlet Table 7Document1 pageQuizlet Table 7JosielynNo ratings yet
- 7273X 47 ITOW Mozart PDFDocument3 pages7273X 47 ITOW Mozart PDFAdrian KranjcevicNo ratings yet
- 95 935 Dowsil Acp 3990 Antifoam CompDocument2 pages95 935 Dowsil Acp 3990 Antifoam CompZhan FangNo ratings yet
- Job Sheet 1Document5 pagesJob Sheet 1Sue AzizNo ratings yet
- 7 ApportionmentDocument46 pages7 Apportionmentsass sofNo ratings yet
- No Experience ResumeDocument2 pagesNo Experience ResumeNatalia PantojaNo ratings yet
- Sample Spec For AWWA HDPE Pipe Fittings 6.02revDocument6 pagesSample Spec For AWWA HDPE Pipe Fittings 6.02revmg4myNo ratings yet
- DPP On Mole Concept (Ncert)Document47 pagesDPP On Mole Concept (Ncert)Raju SinghNo ratings yet
- Faculty Vitae 1. Name: C.TamilselviDocument2 pagesFaculty Vitae 1. Name: C.Tamilselvisadeeskumar.dNo ratings yet
- Appendicitis Case StudyDocument6 pagesAppendicitis Case StudyKimxi Chiu LimNo ratings yet
- Reaction Paper DementiaDocument1 pageReaction Paper DementiaElla MejiaNo ratings yet
- Englis 123Document39 pagesEnglis 123Cindy EysiaNo ratings yet
- Digital ThermometerDocument12 pagesDigital Thermometershahpatel19No ratings yet
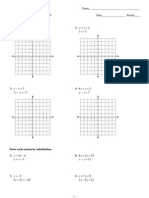
- Review Systems of Linear Equations All MethodsDocument4 pagesReview Systems of Linear Equations All Methodsapi-265647260No ratings yet
- Astm D2265-00 PDFDocument5 pagesAstm D2265-00 PDFOGINo ratings yet
- Combat Storm - Shipping ContainerDocument6 pagesCombat Storm - Shipping ContainermoiNo ratings yet
- Glossary of Terms 2nd PartDocument2 pagesGlossary of Terms 2nd Part2DJoyce D.N CapacieteNo ratings yet
- Esp Kelompok 2Document19 pagesEsp Kelompok 2Taufiq DiNo ratings yet
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveFrom EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNo ratings yet
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessFrom EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNo ratings yet
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindFrom EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNo ratings yet
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldFrom EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldRating: 4.5 out of 5 stars4.5/5 (55)
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepFrom EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepRating: 4.5 out of 5 stars4.5/5 (19)
- Generative AI: The Insights You Need from Harvard Business ReviewFrom EverandGenerative AI: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (2)