You might also like
- How To Build Your Own Neural Network From Scratch inDocument6 pagesHow To Build Your Own Neural Network From Scratch inBrian Ramiro Oporto QuispeNo ratings yet
- Problem SolvingDocument23 pagesProblem Solvingsreenu_pes0% (1)
- An Efficient Hybrid by Partitioning Approach For Extracting Maximal Gradual Patterns in Large Databases (MPSGrite)Document15 pagesAn Efficient Hybrid by Partitioning Approach For Extracting Maximal Gradual Patterns in Large Databases (MPSGrite)BOHR International Journal of Computer Science (BIJCS)No ratings yet
- A Distinct Method To Find The Critical Path and Total Float Under Fuzzy EnvironmentDocument5 pagesA Distinct Method To Find The Critical Path and Total Float Under Fuzzy EnvironmentijsretNo ratings yet
- Succinct Posets PDFDocument15 pagesSuccinct Posets PDFanant_nimkar9243No ratings yet
- On Infinite-Horizon Probabilistic Properties and Stochastic Bisimulation FunctionsDocument6 pagesOn Infinite-Horizon Probabilistic Properties and Stochastic Bisimulation FunctionsIlya TkachevNo ratings yet
- Mat CDZ EnumerateDocument8 pagesMat CDZ EnumerateEMellaNo ratings yet
- Hashing Methods For Temporal Data: George Kollios, Member, IEEE, and Vassilis J. TsotrasDocument19 pagesHashing Methods For Temporal Data: George Kollios, Member, IEEE, and Vassilis J. TsotrasEdisonChimueloNo ratings yet
- C Modeling and Prediction Using Seasonal ARIMA: Wireless Tra ModelsDocument8 pagesC Modeling and Prediction Using Seasonal ARIMA: Wireless Tra ModelsMalik harisNo ratings yet
- 13 GravesDocument12 pages13 Gravesroenavega2014No ratings yet
- AB-wavelet Frames in L (R) : Hari M. Srivastava, Firdous A. ShahDocument11 pagesAB-wavelet Frames in L (R) : Hari M. Srivastava, Firdous A. ShahAyyubi AhmadNo ratings yet
- Dynamic Algorithms in Computational GeometryDocument49 pagesDynamic Algorithms in Computational Geometrysolrak_07No ratings yet
- A New Approach To Find Roots of Nonlinear Equations by Hybrid Algorithm To Bisection and Newton-Raphson AlgorithmsDocument8 pagesA New Approach To Find Roots of Nonlinear Equations by Hybrid Algorithm To Bisection and Newton-Raphson AlgorithmsAhmed adelNo ratings yet
- Closet - An Efficient Algorithm For Mining FrequentDocument8 pagesCloset - An Efficient Algorithm For Mining Frequentapi-19799369No ratings yet
- Myers O ND DiferenceDocument16 pagesMyers O ND DiferenceObelix1789No ratings yet
- DSA 15 - Compre - Question Paper PDFDocument2 pagesDSA 15 - Compre - Question Paper PDFsrirams007No ratings yet
- Hierarchical Bin Buffering: Online Local Moments For Dynamic External Memory ArraysDocument32 pagesHierarchical Bin Buffering: Online Local Moments For Dynamic External Memory ArraysDaniel LemireNo ratings yet
- A A T F M F C T I: N Dvanced OOL OR Anaging Uzzy Omplex Emporal NformationDocument20 pagesA A T F M F C T I: N Dvanced OOL OR Anaging Uzzy Omplex Emporal NformationCS & ITNo ratings yet
- WWW - Manaresults.Co - In: S Xs SsDocument3 pagesWWW - Manaresults.Co - In: S Xs SsmushahedNo ratings yet
- Comparison of Systems Using Diffusion MapsDocument6 pagesComparison of Systems Using Diffusion MapsAndrew FongNo ratings yet
- 2DI F D A D S E S: Mage Eatures Etector ND Escriptor Election Xpert YstemDocument11 pages2DI F D A D S E S: Mage Eatures Etector ND Escriptor Election Xpert YstemIbon MerinoNo ratings yet
- TARJANDocument20 pagesTARJANTomiro YisajorNo ratings yet
- Reducing The Time Needed To Solve A Traveling Salesman Problem by Clustering With A Hierarchy-Based AlgorithmDocument9 pagesReducing The Time Needed To Solve A Traveling Salesman Problem by Clustering With A Hierarchy-Based AlgorithmIAES IJAINo ratings yet
- BakaDocument85 pagesBakaM NarendranNo ratings yet
- Power Load Forecasting Based On Multi-Task Gaussian ProcessDocument6 pagesPower Load Forecasting Based On Multi-Task Gaussian ProcessKhalid AlHashemiNo ratings yet
- Mining Temporal Patterns For Interval-Based and Point-Based EventsDocument6 pagesMining Temporal Patterns For Interval-Based and Point-Based EventsInternational Journal of computational Engineering research (IJCER)No ratings yet
- A New Numerical Approach of Solving Fractional Mobile-Immobile Transport Equation Using Atangana-Baleanu DerivativeDocument23 pagesA New Numerical Approach of Solving Fractional Mobile-Immobile Transport Equation Using Atangana-Baleanu Derivativerashmi.sharma.rs.mat18No ratings yet
- Power Load Forecasting Based On Multi Task Gaussia - 2014 - IFAC Proceedings VolDocument6 pagesPower Load Forecasting Based On Multi Task Gaussia - 2014 - IFAC Proceedings VolKhalid AlHashemiNo ratings yet
- El Moufatich PapemjhjlklkllllllllrDocument9 pagesEl Moufatich PapemjhjlklkllllllllrNeerav AroraNo ratings yet
- CSD - Reviews09-HashingDocument25 pagesCSD - Reviews09-HashingNguyen Dang Minh Thuan (K13HCM)No ratings yet
- 002 DcproblemsDocument8 pages002 DcproblemsTayyab UsmanNo ratings yet
- W1-3 Application of Linear SystemsDocument56 pagesW1-3 Application of Linear SystemsEmanuel JheadNo ratings yet
- Research Article: Efficient 3D Volume Reconstruction From A Point Cloud Using A Phase-Field MethodDocument10 pagesResearch Article: Efficient 3D Volume Reconstruction From A Point Cloud Using A Phase-Field MethodAYUSH KUMARNo ratings yet
- Improvements of TLAESA Nearest Neighbour Search Algorithm and Extension To Approximation SearchDocument7 pagesImprovements of TLAESA Nearest Neighbour Search Algorithm and Extension To Approximation SearchGonzalo René Ccama RamosNo ratings yet
- 1 Preliminaries: Data Structures and AlgorithmsDocument21 pages1 Preliminaries: Data Structures and AlgorithmsPavan RsNo ratings yet
- Jntuk 2 1 RV&SP Nov 2017 Q.PDocument8 pagesJntuk 2 1 RV&SP Nov 2017 Q.PSANDEEPC9100% (1)
- An O (ND) Difference Algorithm and Its VariationsDocument15 pagesAn O (ND) Difference Algorithm and Its VariationsdensimfNo ratings yet
- Fuzzy Fault Tree Analysis Using Resolution Identity: January 1993Document14 pagesFuzzy Fault Tree Analysis Using Resolution Identity: January 1993Ercan YüksekyıldızNo ratings yet
- Adityo 2020 J. Phys. Conf. Ser. 1511 012074Document11 pagesAdityo 2020 J. Phys. Conf. Ser. 1511 012074HendratoNo ratings yet
- Al Manja Hie 2018Document4 pagesAl Manja Hie 2018Proba10 StatNo ratings yet
- Parallel Association Rule Mining by Data De-Clustering To Support Grid ComputingDocument14 pagesParallel Association Rule Mining by Data De-Clustering To Support Grid Computingsoda1206No ratings yet
- Time Series Practice P2Document4 pagesTime Series Practice P2Aa Hinda no AriaNo ratings yet
- On Nabla Conformable Fractional Hardy-Type Inequalities On Arbitrary Time ScalesDocument23 pagesOn Nabla Conformable Fractional Hardy-Type Inequalities On Arbitrary Time ScalesCarlos TavaresNo ratings yet
- Vaidyanathan 1987Document13 pagesVaidyanathan 1987Tseng KweiwenNo ratings yet
- IJPAMBulgaria Paper PublishedDocument19 pagesIJPAMBulgaria Paper Publishedsubha lakshmiNo ratings yet
- Prony PaperDocument10 pagesProny PaperAnkit BhattNo ratings yet
- Linearizability PDFDocument30 pagesLinearizability PDFSachin ChaudharyNo ratings yet
- Approximate Data Structures With ApplicationsDocument8 pagesApproximate Data Structures With ApplicationsAbdirazak MuftiNo ratings yet
- Suzuki 1991Document9 pagesSuzuki 1991Kevin IglesiasNo ratings yet
- Estimation Methods of The Parameters in Fuzzy Pareto DistributionDocument9 pagesEstimation Methods of The Parameters in Fuzzy Pareto DistributionIJRASETPublicationsNo ratings yet
- Comparison of Common AlgorithmsDocument3 pagesComparison of Common AlgorithmsZAIN ABBASNo ratings yet
- Parallel Hybrid Algorithm of Bisection and Newton-Raphson Methods To Find Non-Linear Equations RootsDocument5 pagesParallel Hybrid Algorithm of Bisection and Newton-Raphson Methods To Find Non-Linear Equations RootsIOSRjournalNo ratings yet
- Algos Cs Cmu EduDocument15 pagesAlgos Cs Cmu EduRavi Chandra Reddy MuliNo ratings yet
- Tagged PDFDocument6 pagesTagged PDFklopakNo ratings yet
- AnalysisOf The MG1Document8 pagesAnalysisOf The MG1sugiantowellyNo ratings yet
- Characterizations of Strong and Balanced Neutrosophic Complex GraphsDocument5 pagesCharacterizations of Strong and Balanced Neutrosophic Complex GraphsScience DirectNo ratings yet
- 1975 - General Context-Free Recognition in Less Than Cubic TimeDocument15 pages1975 - General Context-Free Recognition in Less Than Cubic TimeJiye QianNo ratings yet
- Image Signature: Highlighting Sparse Salient Regions: Xiaodi Hou, Jonathan Harel, and Christof KochDocument8 pagesImage Signature: Highlighting Sparse Salient Regions: Xiaodi Hou, Jonathan Harel, and Christof KochSiddharth ShirodkarNo ratings yet
- ADA PPTs (Merged) A2 BatchDocument319 pagesADA PPTs (Merged) A2 BatchAayushNo ratings yet
- BIRCH Cluster For Time SeriesDocument5 pagesBIRCH Cluster For Time SeriesyurimazurNo ratings yet
- COL106 Problems PDFDocument10 pagesCOL106 Problems PDFgNo ratings yet
- IJETR033013Document8 pagesIJETR033013erpublicationNo ratings yet
- IJETR033069Document6 pagesIJETR033069erpublicationNo ratings yet
- IJETR033043Document6 pagesIJETR033043erpublicationNo ratings yet
- IJETR033040Document3 pagesIJETR033040erpublicationNo ratings yet
- IJETR033060Document6 pagesIJETR033060erpublicationNo ratings yet
- IJETR033082Document4 pagesIJETR033082erpublicationNo ratings yet
- IJETR033079Document4 pagesIJETR033079erpublicationNo ratings yet
- IJETR033049Document5 pagesIJETR033049erpublicationNo ratings yet
- IJETR033063Document3 pagesIJETR033063erpublicationNo ratings yet
- IJETR033077Document6 pagesIJETR033077erpublicationNo ratings yet
- IJETR033053Document4 pagesIJETR033053erpublicationNo ratings yet
- IJETR033062Document2 pagesIJETR033062erpublicationNo ratings yet
- IJETR033055Document9 pagesIJETR033055erpublicationNo ratings yet
- Matlab and Simulink Based Simulation of Wideband Code Division Multiple Access (WCDMA)Document6 pagesMatlab and Simulink Based Simulation of Wideband Code Division Multiple Access (WCDMA)erpublicationNo ratings yet
- IJETR033050Document6 pagesIJETR033050erpublicationNo ratings yet
- IJETR033012Document7 pagesIJETR033012erpublicationNo ratings yet
- IJETR032923Document5 pagesIJETR032923erpublicationNo ratings yet
- Thermal Analysis of Motor Controller For Electric Vehicle: Jian-Ping Wen, Chao XuDocument3 pagesThermal Analysis of Motor Controller For Electric Vehicle: Jian-Ping Wen, Chao XuerpublicationNo ratings yet
- IJETR033051Document2 pagesIJETR033051erpublicationNo ratings yet
- IJETR033035Document5 pagesIJETR033035erpublicationNo ratings yet
- IJETR033047Document4 pagesIJETR033047erpublicationNo ratings yet
- IJETR033033Document4 pagesIJETR033033erpublicationNo ratings yet
- Charts For Cofficents of Moments For Continous BeamsDocument19 pagesCharts For Cofficents of Moments For Continous Beamsfat470No ratings yet
- IJETR032922Document6 pagesIJETR032922erpublicationNo ratings yet
- Recognition of Heterogeneous Faces Using Kernel Principal Component AnalysisDocument4 pagesRecognition of Heterogeneous Faces Using Kernel Principal Component AnalysiserpublicationNo ratings yet
- IJETR033011Document3 pagesIJETR033011erpublicationNo ratings yet
- IJETR032918Document12 pagesIJETR032918erpublicationNo ratings yet
- IJETR032909Document11 pagesIJETR032909erpublicationNo ratings yet
- The Effect of Focus On Spectral Emphasis For Disyllabic Words in ChineseDocument4 pagesThe Effect of Focus On Spectral Emphasis For Disyllabic Words in ChineseerpublicationNo ratings yet
- ADRC Speed Control of IPMSM With Current Regulator: Wen Jianping, Zhang XuhuiDocument3 pagesADRC Speed Control of IPMSM With Current Regulator: Wen Jianping, Zhang XuhuierpublicationNo ratings yet
- Payshield 9000 Payshield 9000 and DUKPT Application Note PWPR April 2013Document25 pagesPayshield 9000 Payshield 9000 and DUKPT Application Note PWPR April 2013Mario NấmNo ratings yet
- Algorithms Exam HelpDocument19 pagesAlgorithms Exam HelpProgramming Exam HelpNo ratings yet
- Chapter 01Document28 pagesChapter 01Shafique AhmedNo ratings yet
- Purpose of Curve FittingDocument6 pagesPurpose of Curve Fittingابریزہ احمدNo ratings yet
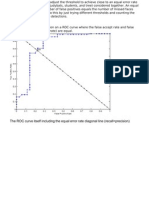
- The ROC Curve Itself Including The Equal Error Rate Diagonal Line (Recall Precision)Document3 pagesThe ROC Curve Itself Including The Equal Error Rate Diagonal Line (Recall Precision)OndelettaNo ratings yet
- Study of Page Replacement Algorithm Based On Experiment: Wang HongDocument5 pagesStudy of Page Replacement Algorithm Based On Experiment: Wang HongvinjamurisivaNo ratings yet
- End-Term Exam - Quantitative Techniques IIDocument3 pagesEnd-Term Exam - Quantitative Techniques IIAshish TiwariNo ratings yet
- Topic Scan Conversion: CSE5280 - Computer GraphicsDocument21 pagesTopic Scan Conversion: CSE5280 - Computer GraphicsabNo ratings yet
- Hash Table: Didih Rizki ChandranegaraDocument33 pagesHash Table: Didih Rizki Chandranegaraset ryzenNo ratings yet
- Robotic ManipulatorsDocument4 pagesRobotic Manipulatorsshaik roshanNo ratings yet
- IandF CT4 201509 ExamDocument10 pagesIandF CT4 201509 ExamHaganNo ratings yet
- Robust Feature-Based Automated Multi-View Human Action Recognition SystemDocument3 pagesRobust Feature-Based Automated Multi-View Human Action Recognition SystemedigikaveriNo ratings yet
- Tutorial III Root Locus DesignDocument25 pagesTutorial III Root Locus Designapi-3856083100% (3)
- Credit Card Fraud DetectDocument19 pagesCredit Card Fraud DetectVikas BankarNo ratings yet
- SyllabusDocument2 pagesSyllabusBhavana NagarajNo ratings yet
- Collection FrameworkDocument4 pagesCollection FrameworkSaurabh KothariNo ratings yet
- (2016 DeepMind) AsynchronousMethodsforDeepReinforcementLearning PDFDocument10 pages(2016 DeepMind) AsynchronousMethodsforDeepReinforcementLearning PDFAnis MehrabNo ratings yet
- Topic 4 Describing Function PDFDocument101 pagesTopic 4 Describing Function PDFMeet VasaniNo ratings yet
- Quantum MechanicsDocument21 pagesQuantum MechanicsBiswajit PaulNo ratings yet
- Aut7.1.4 Recognise The Difference Between Linear and Non Linear SequencesDocument39 pagesAut7.1.4 Recognise The Difference Between Linear and Non Linear SequencesKesiyaNo ratings yet
- Modeling and Analysis: Heuristic Search Methods and SimulationDocument16 pagesModeling and Analysis: Heuristic Search Methods and SimulationVikram KumarNo ratings yet
- 1 Schrdinger Wave EquationDocument4 pages1 Schrdinger Wave EquationHi HelloNo ratings yet
- FEM 2d Lect1Document138 pagesFEM 2d Lect1Murali ReddyNo ratings yet
- CS 731: Blockchain Technology and Applications: Sandeep K. Shukla IIT KanpurDocument51 pagesCS 731: Blockchain Technology and Applications: Sandeep K. Shukla IIT KanpurVijayalakshmi JNo ratings yet
- Sample 1Document20 pagesSample 1davNo ratings yet
- LG2 CryptographyDocument19 pagesLG2 CryptographyDr Patrick CernaNo ratings yet
- Midterm Probset RelationsDocument2 pagesMidterm Probset RelationsJericho QuitilNo ratings yet
- Q1. Identification of Significant Features and Data Mining Techniques in Predicting Heart DiseaseDocument12 pagesQ1. Identification of Significant Features and Data Mining Techniques in Predicting Heart DiseaseFahmiNo ratings yet