You might also like
- SolidWorks 2016 Learn by doing 2016 - Part 3From EverandSolidWorks 2016 Learn by doing 2016 - Part 3Rating: 3.5 out of 5 stars3.5/5 (3)
- Quantitative Methods in Economics Linear Predictor: Maximilian KasyDocument19 pagesQuantitative Methods in Economics Linear Predictor: Maximilian KasyWazzupWorldNo ratings yet
- Chap 016Document59 pagesChap 016BG Monty 1No ratings yet
- Multiple Regression PDFDocument19 pagesMultiple Regression PDFSachen KulandaivelNo ratings yet
- Nur Syuhada Binti Safaruddin - Rba2403a - 2020819322Document6 pagesNur Syuhada Binti Safaruddin - Rba2403a - 2020819322syuhadasafar000No ratings yet
- Stat 252-Practice Final-Greg-SolutionsDocument14 pagesStat 252-Practice Final-Greg-Solutionsdeep81204No ratings yet
- ASQ MSA An Alternative Method For Estimating Percentage Tolerance 20120418Document78 pagesASQ MSA An Alternative Method For Estimating Percentage Tolerance 20120418solmaz MOVAFAGHINo ratings yet
- Multiple Regression in SPSS: X X X y X X y X X yDocument13 pagesMultiple Regression in SPSS: X X X y X X y X X yRohit SikriNo ratings yet
- Sta Chương15Document4 pagesSta Chương15Nguyễn Thu HươngNo ratings yet
- Sagarmatha College For Higher Studies Probability LabDocument20 pagesSagarmatha College For Higher Studies Probability LabrajeshNo ratings yet
- Example For Multiple Linear RegressionDocument10 pagesExample For Multiple Linear Regressionm210192No ratings yet
- Multiple RegressionDocument29 pagesMultiple Regressionpriy14100% (1)
- Report Has Prepared by Kamran Selimli and Sahil MesimovDocument14 pagesReport Has Prepared by Kamran Selimli and Sahil MesimovsahilNo ratings yet
- Edu6950 Multiple RegressionDocument24 pagesEdu6950 Multiple RegressionSa'adah JamaluddinNo ratings yet
- Homework Solutions For Chapter 13Document17 pagesHomework Solutions For Chapter 13api-234237296No ratings yet
- 0feaf24f-6a96-4279-97a1-86708e467593 (1)Document7 pages0feaf24f-6a96-4279-97a1-86708e467593 (1)simandharNo ratings yet
- Normal Distribution Tolerance Sample Size CalculatorDocument9 pagesNormal Distribution Tolerance Sample Size Calculatoryoge1130No ratings yet
- Sta - Chap 14Document4 pagesSta - Chap 14凱儀No ratings yet
- Reasons For Adopting Stochiastic Operation Method: (Diferencial Evolution)Document11 pagesReasons For Adopting Stochiastic Operation Method: (Diferencial Evolution)Sandip PurnapatraNo ratings yet
- Regression & Correlation Assingment 1Document6 pagesRegression & Correlation Assingment 1irfanrizviNo ratings yet
- Regn & Marketing ResearchDocument23 pagesRegn & Marketing ResearchsandeepbannaNo ratings yet
- QM-II Midterm OCT 2014 SolutionDocument19 pagesQM-II Midterm OCT 2014 SolutionsandeeptirukotiNo ratings yet
- BusStat 2023 HW13 Chapter 13Document3 pagesBusStat 2023 HW13 Chapter 13Friscilia OrlandoNo ratings yet
- Minitab Simple Regression AnalysisDocument7 pagesMinitab Simple Regression AnalysisRadu VasileNo ratings yet
- MonteCarlo Simulations Using ADE XLDocument7 pagesMonteCarlo Simulations Using ADE XLDuc DucNo ratings yet
- Toledo GasDocument5 pagesToledo GasRongor10No ratings yet
- Tutorial For MarketingDocument10 pagesTutorial For MarketingNandkumar KhachaneNo ratings yet
- 7 QC ToolsDocument14 pages7 QC ToolsshashikantjoshiNo ratings yet
- Econometic AnalysisDocument29 pagesEconometic AnalysisNikhil PuvvallaNo ratings yet
- Analysis of Two Level DesignsDocument11 pagesAnalysis of Two Level Designsjuan vidalNo ratings yet
- SPAD7 Data Miner Guide PDFDocument176 pagesSPAD7 Data Miner Guide PDFPabloAPachecoNo ratings yet
- Regression ExcelDocument5 pagesRegression ExcelniichauhanNo ratings yet
- Gage R&RDocument28 pagesGage R&RParimal100% (1)
- Slides Marked As Extra Study Are Not As A Part of Syllabus. Those Are Provided For Add-On KnowledgeDocument45 pagesSlides Marked As Extra Study Are Not As A Part of Syllabus. Those Are Provided For Add-On KnowledgeVerendraNo ratings yet
- RSM Part1 IntroDocument61 pagesRSM Part1 Introksheikh777No ratings yet
- University of Engineering and Technology Peshawar Jalozai CampusDocument17 pagesUniversity of Engineering and Technology Peshawar Jalozai CampusShafi UllahNo ratings yet
- Stat 252-Practice Final-Greg-Questions OnlyDocument14 pagesStat 252-Practice Final-Greg-Questions Onlydeep81204No ratings yet
- Output DataDocument19 pagesOutput DatajelantikdarmaNo ratings yet
- MGS3100: Exercises - ForecastingDocument8 pagesMGS3100: Exercises - ForecastingJabir ArifNo ratings yet
- AMDA Regression SolutionDocument12 pagesAMDA Regression SolutionParambrahma PandaNo ratings yet
- Decision Science June 2022 Unique Set4 WiDocument14 pagesDecision Science June 2022 Unique Set4 WiManoj KumarNo ratings yet
- Stat 401B Exam 2 Key F16Document10 pagesStat 401B Exam 2 Key F16juanEs2374pNo ratings yet
- 12CVDocument3 pages12CVAakash FatnaniNo ratings yet
- Introductory Statistics (STA101) Memo Class TestDocument3 pagesIntroductory Statistics (STA101) Memo Class TestLumkaNo ratings yet
- TitanInsuranceCaseStudy Group8Document17 pagesTitanInsuranceCaseStudy Group8BISHNUDEV DEYNo ratings yet
- Simple Regression With SPSSDocument19 pagesSimple Regression With SPSSlikeme2fewNo ratings yet
- STAT 252 2018 Fall HW4 Solutions PDFDocument11 pagesSTAT 252 2018 Fall HW4 Solutions PDFdeep81204No ratings yet
- 02 Introduction To Statistics JDocument12 pages02 Introduction To Statistics JSagitarius SagitariaNo ratings yet
- Lab 9 ReportDocument5 pagesLab 9 ReportMaira SulaimanovaNo ratings yet
- FRA Business ReportDocument21 pagesFRA Business ReportSurabhi Kulkarni100% (1)
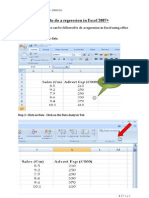
- How To Do A Regression in Excel 2007Document10 pagesHow To Do A Regression in Excel 2007Minh ThangNo ratings yet
- Data AnalysisDocument28 pagesData AnalysisDotRev Ibs100% (1)
- Ch26 ExercisesDocument14 pagesCh26 Exercisesamisha2562585No ratings yet
- Number of Parts and Operators For A Gage R&R Study - MinitabDocument12 pagesNumber of Parts and Operators For A Gage R&R Study - Minitabtehky63No ratings yet
- How To Design, Analyze and Interpret The Results of An Expanded Gage R&R StudyDocument10 pagesHow To Design, Analyze and Interpret The Results of An Expanded Gage R&R Studymassman02143No ratings yet
- Chapter 15Document43 pagesChapter 15mannsahil72No ratings yet
- Worksheet 9 SolutionDocument3 pagesWorksheet 9 Solutionkhadijah shabanNo ratings yet
- Multilinear ProblemStatementDocument132 pagesMultilinear ProblemStatementSBS MoviesNo ratings yet
- Tutorial 2Document8 pagesTutorial 2Bharti ChauhanNo ratings yet
- SolidWorks 2015 Learn by doing-Part 3 (DimXpert and Rendering)From EverandSolidWorks 2015 Learn by doing-Part 3 (DimXpert and Rendering)Rating: 4.5 out of 5 stars4.5/5 (5)
- Solidworks 2018 Learn by Doing - Part 3: DimXpert and RenderingFrom EverandSolidworks 2018 Learn by Doing - Part 3: DimXpert and RenderingNo ratings yet
- The Framework of Contemporary BusinessDocument19 pagesThe Framework of Contemporary BusinessKami4038No ratings yet
- Introduction To TaxationDocument33 pagesIntroduction To TaxationKami4038No ratings yet
- An Introduction To Taxation and Understanding The Federal Tax LawDocument55 pagesAn Introduction To Taxation and Understanding The Federal Tax LawKami4038No ratings yet
- Anti-Money Laundring Act 2010: Abid H. ShabanDocument53 pagesAnti-Money Laundring Act 2010: Abid H. ShabanKami4038No ratings yet
- OrthDocument18 pagesOrthHassan Ali KhanNo ratings yet
- CO3 Session 14Document15 pagesCO3 Session 14Devalla Bhaskar GaneshNo ratings yet
- 18MAB303T - RegressionDocument97 pages18MAB303T - RegressionJEMINA J (RA2011037010010)No ratings yet
- Excel'S NPV FunctionDocument41 pagesExcel'S NPV FunctionSyed Ameer Ali ShahNo ratings yet
- PDF 3Document1 pagePDF 3abhay pandeyNo ratings yet
- GridDataReport KEL 2Document7 pagesGridDataReport KEL 2Anisa Noor HidayahNo ratings yet
- Mid Term PaperDocument1 pageMid Term PaperHadia Azhar2558100% (1)
- Analisis CFA by LisrelDocument8 pagesAnalisis CFA by LisrelAtoillah IsvandiaryNo ratings yet
- 02-2021 - Quant Advanced 2Document71 pages02-2021 - Quant Advanced 2Mahardhika Harry NugrahaNo ratings yet
- Capstone Project - Final SubmissionDocument36 pagesCapstone Project - Final Submissionanoop kNo ratings yet
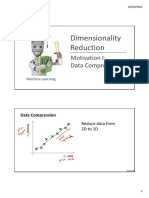
- Dimensionality Reduction: Motivation I: Data CompressionDocument35 pagesDimensionality Reduction: Motivation I: Data CompressionAli NasirNo ratings yet
- Analysis of Variance (Anova) Part 3 Two-Way Anova Replication (Factorial Experiment)Document21 pagesAnalysis of Variance (Anova) Part 3 Two-Way Anova Replication (Factorial Experiment)Farrukh JamilNo ratings yet
- Chapter 12 - Logistic Regression For Classification and PredictionDocument13 pagesChapter 12 - Logistic Regression For Classification and Predictionalfin luanmasaNo ratings yet
- Powerpoint Presentation - Analysis of Variance (ANOVA)Document10 pagesPowerpoint Presentation - Analysis of Variance (ANOVA)Vivay SalazarNo ratings yet
- LC 50Document3 pagesLC 50Wilson Gomarga100% (1)
- Minggu 1 - Pengantar Analisis Multivariate PDFDocument51 pagesMinggu 1 - Pengantar Analisis Multivariate PDFHAFIDZ NUR SHAFWANNo ratings yet
- Chapter IIDocument31 pagesChapter IIAnmut YeshuNo ratings yet
- ANCOVA Analysis in Excel TutorialDocument7 pagesANCOVA Analysis in Excel TutorialROJI BINTI LINANo ratings yet
- SVM Assignment ABA Course To Be Returned With Your AnswersDocument10 pagesSVM Assignment ABA Course To Be Returned With Your AnswersNabeel MohammadNo ratings yet
- Parameter Lower 95.0% Confidence Limit Point Estimate Upper 95.0% Confidence LimitDocument5 pagesParameter Lower 95.0% Confidence Limit Point Estimate Upper 95.0% Confidence LimitJoseNo ratings yet
- RegressionDocument3 pagesRegressionSundas SaikhuNo ratings yet
- ML0101EN Reg Simple Linear Regression Co2 Py v1Document4 pagesML0101EN Reg Simple Linear Regression Co2 Py v1Muhammad RaflyNo ratings yet
- Sentiment Analysis On TweetsDocument2 pagesSentiment Analysis On TweetsvikibytesNo ratings yet
- Learn Machine Learning: ReferenceDocument9 pagesLearn Machine Learning: ReferenceUzùmákî Nägäto TenshøûNo ratings yet
- Categorical Data AnalysisDocument11 pagesCategorical Data Analysisishwar12173No ratings yet
- 2.1972 Generalized Linear Models Nelder WedderburnDocument16 pages2.1972 Generalized Linear Models Nelder WedderburnsssNo ratings yet
- Accounting Research Center, Booth School of Business, University of ChicagoDocument19 pagesAccounting Research Center, Booth School of Business, University of Chicagokazia laturetteNo ratings yet
- STAT 3008 OutlineDocument4 pagesSTAT 3008 OutlineEmerald LamNo ratings yet
- Quit Spreadsheet - Completed - Wharton - Business Analytics - Week 6Document28 pagesQuit Spreadsheet - Completed - Wharton - Business Analytics - Week 6GgarivNo ratings yet