You might also like
- Advanced Algorithms Course. Lecture Notes. Part 2: Set CoverDocument3 pagesAdvanced Algorithms Course. Lecture Notes. Part 2: Set CoverKasapaNo ratings yet
- EedyDocument15 pagesEedyvedantlfcNo ratings yet
- MIT NoteDocument140 pagesMIT NoteWidmungNo ratings yet
- MIT18 102s21 Lec1Document7 pagesMIT18 102s21 Lec1vladimirNo ratings yet
- MIT18 102s21 Full LecDocument125 pagesMIT18 102s21 Full LecProNo ratings yet
- Lec 17Document3 pagesLec 17aung zaw moeNo ratings yet
- Name 1: - Drexel Username 1Document4 pagesName 1: - Drexel Username 1Bao DangNo ratings yet
- Dynamic Programming Algorithms: Last Updated: 10/21/2022Document38 pagesDynamic Programming Algorithms: Last Updated: 10/21/2022TameneNo ratings yet
- Week 7 1 Network Flow: 1.1 Dual AlgorithmsDocument5 pagesWeek 7 1 Network Flow: 1.1 Dual AlgorithmsmkhawarbashirNo ratings yet
- MIT18 102s21 Lec5Document5 pagesMIT18 102s21 Lec5vladimirNo ratings yet
- Lectures On Optimization: A. BanerjiDocument49 pagesLectures On Optimization: A. BanerjiSumit SharmaNo ratings yet
- Anal II 2019 PostDocument63 pagesAnal II 2019 PostNico ShermanNo ratings yet
- Cdmtcs Research Series: Ludwig StaigerDocument4 pagesCdmtcs Research Series: Ludwig StaigerFais AbdulNo ratings yet
- Lecture 5Document6 pagesLecture 5Tony AbhishekNo ratings yet
- 1.4 The Hahn Banach TheoremDocument9 pages1.4 The Hahn Banach TheoremEDU CIPANANo ratings yet
- Kolmogorov Complexity: Lance FortnowDocument14 pagesKolmogorov Complexity: Lance FortnowAzmi AbdulbaqiNo ratings yet
- SQ Multiobjective Programming ProblemDocument8 pagesSQ Multiobjective Programming ProblemKhang Trương TuấnNo ratings yet
- Lecture2 PDFDocument9 pagesLecture2 PDFTamal BrNo ratings yet
- Advanced Algorithms Course. Lecture Notes. Part 4: Using Linear Programming For Approximation AlgorithmsDocument5 pagesAdvanced Algorithms Course. Lecture Notes. Part 4: Using Linear Programming For Approximation AlgorithmsKasapaNo ratings yet
- Combinatorial Optimization: Sheet 1Document5 pagesCombinatorial Optimization: Sheet 1Subhash KorumilliNo ratings yet
- Dirac NotationDocument7 pagesDirac NotationDavidNo ratings yet
- Calculation of Stability Radii For Combinatorial Optimization ProblemsDocument14 pagesCalculation of Stability Radii For Combinatorial Optimization ProblemsZuhair AnwarNo ratings yet
- Knapsack +Document49 pagesKnapsack +pehe SmartTechNo ratings yet
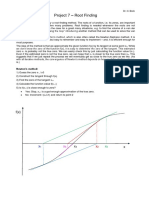
- Project 7 - Root Finding: Newton's MethodDocument4 pagesProject 7 - Root Finding: Newton's Methodhannan1993No ratings yet
- Primal DualDocument20 pagesPrimal DualPritish PradhanNo ratings yet
- Dirac Notation and Basic Linear Algebra For Quantum ComputingDocument4 pagesDirac Notation and Basic Linear Algebra For Quantum ComputingsarhahhNo ratings yet
- Discrete Optimization Lecture Notes 3Document2 pagesDiscrete Optimization Lecture Notes 3BertvdvenNo ratings yet
- OptimizationDocument5 pagesOptimizationsweetie05No ratings yet
- Introduction To Approximation Algorithms: Proximation Ratio. Informally, For A Minimization Problem Such As The VDocument15 pagesIntroduction To Approximation Algorithms: Proximation Ratio. Informally, For A Minimization Problem Such As The VPritish PradhanNo ratings yet
- Hahn Banach Theorem - by Ben J. GreenDocument4 pagesHahn Banach Theorem - by Ben J. GreenGeovaneJúnior100% (1)
- The Minimum Volume Covering Ellipsoid Estimation in Kernel-Defined Feature SpacesDocument8 pagesThe Minimum Volume Covering Ellipsoid Estimation in Kernel-Defined Feature SpacesilincaNo ratings yet
- Practice Apx PDocument4 pagesPractice Apx PballechaseNo ratings yet
- MIT18 102s21 Lec3Document5 pagesMIT18 102s21 Lec3vladimirNo ratings yet
- Lecture 04Document8 pagesLecture 04calismahesabimNo ratings yet
- Clustering With Gradient Descent: 1 PerformanceDocument4 pagesClustering With Gradient Descent: 1 PerformanceChristine StraubNo ratings yet
- Math 114 PSet 1 PDFDocument5 pagesMath 114 PSet 1 PDFCheryl FoxNo ratings yet
- Jason Preszler: G (X) H (X)Document10 pagesJason Preszler: G (X) H (X)dmtri100% (1)
- Babai Linear Algebra 1Document3 pagesBabai Linear Algebra 1Chris NatoliNo ratings yet
- 1 Cauchy Sequences: N N J N MDocument3 pages1 Cauchy Sequences: N N J N Maarthi100No ratings yet
- Finalreview Nosolutions PDFDocument5 pagesFinalreview Nosolutions PDFWilliam PruittNo ratings yet
- Correlation and Full Surplus Extraction: Debasis MishraDocument22 pagesCorrelation and Full Surplus Extraction: Debasis MishraankushsemaltiNo ratings yet
- Set Cover ProblemDocument5 pagesSet Cover ProblemJose guiteerrzNo ratings yet
- Linear AlgebraDocument27 pagesLinear AlgebraVicenta RobanteNo ratings yet
- EE 605: Error Correcting CodesDocument2 pagesEE 605: Error Correcting CodesRotem HorowitzNo ratings yet
- Number Theory and AlgebraDocument43 pagesNumber Theory and AlgebraDileep AalamuriNo ratings yet
- Linear Programming: Simplex Method. SolutionDocument5 pagesLinear Programming: Simplex Method. SolutionAnaNo ratings yet
- Greedy AlgorithmsDocument10 pagesGreedy AlgorithmsZhichaoWangNo ratings yet
- Beamer Presentation For The P Adic IntegersDocument71 pagesBeamer Presentation For The P Adic IntegersAnjali SinghNo ratings yet
- Thuat Toan WinowsDocument4 pagesThuat Toan WinowsCNSNo ratings yet
- Thuat Toan WinowDocument4 pagesThuat Toan WinowCNSNo ratings yet
- Assignment 5 SolutionsDocument9 pagesAssignment 5 SolutionsNengke Lin100% (1)
- Homework 1Document4 pagesHomework 1Bilal Yousaf0% (1)
- Theorist's Toolkit Lecture 12: Semindefinite Programs and Tightening RelaxationsDocument4 pagesTheorist's Toolkit Lecture 12: Semindefinite Programs and Tightening RelaxationsJeremyKunNo ratings yet
- MA4254 Discrete OptimizationDocument69 pagesMA4254 Discrete OptimizationmengsiongNo ratings yet
- Proof of The Spectral Decomposition Theorem in Finite Dimension Using Induction MethodDocument5 pagesProof of The Spectral Decomposition Theorem in Finite Dimension Using Induction MethodSamNo ratings yet
- AlgcombDocument6 pagesAlgcombSanjeev Kumar DasNo ratings yet
- 5 - Algo Mittal Basic QADocument11 pages5 - Algo Mittal Basic QADUNG VAN LUNo ratings yet
- Typeset by AMS-TEXDocument2 pagesTypeset by AMS-TEXYanh VissuetNo ratings yet
- 1 Span and Bases: Lecture 2: September 30, 2021Document6 pages1 Span and Bases: Lecture 2: September 30, 2021Pushkaraj PanseNo ratings yet
- Advanced Algorithms Course. Lecture Notes. Part 11: Chernoff BoundsDocument4 pagesAdvanced Algorithms Course. Lecture Notes. Part 11: Chernoff BoundsKasapaNo ratings yet
- Advanced Algorithms 2011. Exam QuestionsDocument4 pagesAdvanced Algorithms 2011. Exam QuestionsKasapaNo ratings yet
- Advanced Algorithms 2011. Exam AnswersDocument2 pagesAdvanced Algorithms 2011. Exam AnswersKasapaNo ratings yet
- Advalgex4 PDFDocument1 pageAdvalgex4 PDFKasapaNo ratings yet
- Advanced Algorithms 2011. Exercises 1-3: J J J JDocument2 pagesAdvanced Algorithms 2011. Exercises 1-3: J J J JKasapaNo ratings yet
- Advalgex5 PDFDocument2 pagesAdvalgex5 PDFKasapaNo ratings yet
- Advanced Algorithms Course. Lecture Notes. Part 5: Speeding Up Maximum Flow ComputationDocument5 pagesAdvanced Algorithms Course. Lecture Notes. Part 5: Speeding Up Maximum Flow ComputationKasapaNo ratings yet
- Advanced Algorithms Course. Lecture Notes. Part 12: Small Vertex Covers (Continued)Document3 pagesAdvanced Algorithms Course. Lecture Notes. Part 12: Small Vertex Covers (Continued)KasapaNo ratings yet
- Advanced Algorithms 2011. Exercises 4-6Document2 pagesAdvanced Algorithms 2011. Exercises 4-6KasapaNo ratings yet
- Advanced Algorithms 2011. Exercises 7-9Document1 pageAdvanced Algorithms 2011. Exercises 7-9KasapaNo ratings yet
- Advanced Algorithms Course. Lecture Notes. Part 4: Using Linear Programming For Approximation AlgorithmsDocument5 pagesAdvanced Algorithms Course. Lecture Notes. Part 4: Using Linear Programming For Approximation AlgorithmsKasapaNo ratings yet
- Advanced Algorithms Course. Lecture Notes. Part 10: HashingDocument4 pagesAdvanced Algorithms Course. Lecture Notes. Part 10: HashingKasapaNo ratings yet
- Advanced Algorithms Course. Lecture Notes. Part 8Document2 pagesAdvanced Algorithms Course. Lecture Notes. Part 8KasapaNo ratings yet
- Advanced Algorithms Course. Lecture Notes. Part 9: 3-SAT: How To Satisfy Most ClausesDocument4 pagesAdvanced Algorithms Course. Lecture Notes. Part 9: 3-SAT: How To Satisfy Most ClausesKasapaNo ratings yet
- Advanced Algorithms Course. Lecture Notes. Part 7: Minimum Cost Perfect Matchings in Bipartite GraphsDocument3 pagesAdvanced Algorithms Course. Lecture Notes. Part 7: Minimum Cost Perfect Matchings in Bipartite GraphsKasapaNo ratings yet
- Advanced Algorithms Course. Lecture Notes. Part 6: A Simplified Airline Scheduling ProblemDocument4 pagesAdvanced Algorithms Course. Lecture Notes. Part 6: A Simplified Airline Scheduling ProblemKasapaNo ratings yet
- Advanced Algorithms Course. Lecture Notes. Part 1Document4 pagesAdvanced Algorithms Course. Lecture Notes. Part 1KasapaNo ratings yet
- Web-Enabled Decision Support Systems: Prof. Name Position (123) 456-7890 University NameDocument18 pagesWeb-Enabled Decision Support Systems: Prof. Name Position (123) 456-7890 University NameKasapaNo ratings yet
- TDD HarqDocument24 pagesTDD HarqVimal Pratap SinghNo ratings yet
- KOM 3781 Discrete-Time Control Systems: Veysel GaziDocument59 pagesKOM 3781 Discrete-Time Control Systems: Veysel GaziFatih CanbolatNo ratings yet
- Johnloomis Org Ece563 Notes Geom Resize ImresizeDocument10 pagesJohnloomis Org Ece563 Notes Geom Resize ImresizeAdrian Jose Costa OspinoNo ratings yet
- 91exam SolutionDocument6 pages91exam Solutionmahe32maheNo ratings yet
- Application of Rigorous and Relaxed EPWT On 8x8 Image MatrixDocument9 pagesApplication of Rigorous and Relaxed EPWT On 8x8 Image MatrixZeeshan AhmedNo ratings yet
- CE 007 (Numerical Solutions To CE Problems)Document19 pagesCE 007 (Numerical Solutions To CE Problems)Michelle Anne SantosNo ratings yet
- Gauss Seidel MethodDocument2 pagesGauss Seidel MethodgalingeNo ratings yet
- Dess P Box DetilsDocument23 pagesDess P Box Detilslamba5No ratings yet
- Quiz 2 Solutions: and Analysis of AlgorithmsDocument12 pagesQuiz 2 Solutions: and Analysis of Algorithmstestuser4realNo ratings yet
- Polyphase Channelizer TransformationDocument17 pagesPolyphase Channelizer Transformationtasos1970No ratings yet
- Maneesha Nidigonda Minor Project .IpynbDocument35 pagesManeesha Nidigonda Minor Project .IpynbManeesha NidigondaNo ratings yet
- Kristen-Thesis Optimization TecnuqiesDocument39 pagesKristen-Thesis Optimization TecnuqiesuqurxNo ratings yet
- Binary Codes Lecture NotesDocument7 pagesBinary Codes Lecture NotesPatrick SerandonNo ratings yet
- On Handwritten Digit RecognitionDocument15 pagesOn Handwritten Digit RecognitionAnkit Upadhyay100% (1)
- PRE TEST QUESTIONAIRE - Math7 2ndQDocument2 pagesPRE TEST QUESTIONAIRE - Math7 2ndQTherence UbasNo ratings yet
- YOLO V3 ML ProjectDocument15 pagesYOLO V3 ML ProjectAnnie ShuklaNo ratings yet
- 02-1 Linear Algebraic EquationsDocument29 pages02-1 Linear Algebraic EquationsAseel OtoumNo ratings yet
- Tridiagonal Matrix Algorithm: A. SalihDocument2 pagesTridiagonal Matrix Algorithm: A. SalihlomeshNo ratings yet
- Unit IVDocument34 pagesUnit IVCecilia ChinnaNo ratings yet
- Lab 11Document3 pagesLab 11Katneza Katman MohlalaNo ratings yet
- Prob-E 2Document4 pagesProb-E 2Rvo ProductionNo ratings yet
- Introduction To PolynomialsDocument12 pagesIntroduction To PolynomialsJesus PeraltaNo ratings yet
- Practice MidtermDocument2 pagesPractice MidtermwoxaixniNo ratings yet
- Online Passive-Aggressive Algorithms On A BudgetDocument8 pagesOnline Passive-Aggressive Algorithms On A BudgetP6E7P7No ratings yet
- Error Detecting CodesDocument4 pagesError Detecting CodesnqdinhNo ratings yet
- Data Struct Assgn19Document25 pagesData Struct Assgn19Namish DevarajNo ratings yet
- Digital Filter DesignDocument102 pagesDigital Filter Designjaun danielNo ratings yet
- Dip Part-A PDFDocument3 pagesDip Part-A PDFMuthu Palaniappan ANo ratings yet