You might also like
- Digital Control Engineering: Analysis and DesignFrom EverandDigital Control Engineering: Analysis and DesignRating: 3 out of 5 stars3/5 (1)
- Introduction to Reliable and Secure Distributed ProgrammingFrom EverandIntroduction to Reliable and Secure Distributed ProgrammingNo ratings yet
- Using A Rule Engine For Distributed Systems Management: An Exploration Using Data Replication Quan PhamDocument28 pagesUsing A Rule Engine For Distributed Systems Management: An Exploration Using Data Replication Quan PhamthouartuNo ratings yet
- The Distributed Training Environment: Java Object Oriented Neural EngineDocument24 pagesThe Distributed Training Environment: Java Object Oriented Neural EngineJohn Emmanuel I. EncinasNo ratings yet
- Annex 12: Technical Environment and Standard Operating Procedures of The Publications OfficeDocument24 pagesAnnex 12: Technical Environment and Standard Operating Procedures of The Publications OfficedamodarNo ratings yet
- SRS RevisedDocument23 pagesSRS RevisedComputer ScienceNo ratings yet
- Smartplant Instrumentation 2007: Using Rule ManagerDocument33 pagesSmartplant Instrumentation 2007: Using Rule ManagerChristianNo ratings yet
- Best Practice - Data Consistency Check For Logistics PDFDocument68 pagesBest Practice - Data Consistency Check For Logistics PDFUfuk DoğanNo ratings yet
- MusicCengHistoryX SRSDocument23 pagesMusicCengHistoryX SRSNayana GoudaNo ratings yet
- Bde ProgrammingDocument49 pagesBde Programmingboroman99No ratings yet
- BDE C++ Coding StandardsDocument50 pagesBDE C++ Coding StandardsStewart HendersonNo ratings yet
- CEP Thesis PDFDocument72 pagesCEP Thesis PDFManoj SelvamNo ratings yet
- Performance Tuning Waits QueuesDocument98 pagesPerformance Tuning Waits QueuesalexcadimaNo ratings yet
- FD Project ReportDocument13 pagesFD Project ReportZain ZaheerNo ratings yet
- 9293 Selfmanaging In-NetworkDocument12 pages9293 Selfmanaging In-NetworkMark AldissNo ratings yet
- MS Oodf13Document835 pagesMS Oodf13gabrielnsdantasNo ratings yet
- Guide-to-cmdb-solution-designDocument20 pagesGuide-to-cmdb-solution-designcamunozbaNo ratings yet
- Best Practice - Data Consistency Check For LogisticsDocument68 pagesBest Practice - Data Consistency Check For LogisticsMuralidhara Rao Goulapu100% (1)
- Timeouts PT8.5xDocument21 pagesTimeouts PT8.5xJack WangNo ratings yet
- CuramWorkflowOverviewGuide_810Document34 pagesCuramWorkflowOverviewGuide_810Dewansh PachauriNo ratings yet
- SE Lab File 3 PDFDocument7 pagesSE Lab File 3 PDFgambler yeagerNo ratings yet
- System Design Document - SampleDocument20 pagesSystem Design Document - Sampleakshayanavo200950% (2)
- Diogo R. Ferreira (Auth.) - Enterprise Systems Integration_ a Process-Oriented Approach-Springer-Verlag Berlin Heidelberg (2013)Document393 pagesDiogo R. Ferreira (Auth.) - Enterprise Systems Integration_ a Process-Oriented Approach-Springer-Verlag Berlin Heidelberg (2013)Dhafin HananNo ratings yet
- SRS v2 - 13 - 10Document46 pagesSRS v2 - 13 - 10AnNo ratings yet
- Configuration Management (CM) PlanDocument17 pagesConfiguration Management (CM) PlanMartinNo ratings yet
- DOCUMENTATION MM-2.1-EN - US-System Architecture OverviewDocument22 pagesDOCUMENTATION MM-2.1-EN - US-System Architecture OverviewEstefa QuinteroNo ratings yet
- EDS Technical Reference Guide 9.1Document90 pagesEDS Technical Reference Guide 9.1imrich horvathNo ratings yet
- SRS for Hardware Sales and Servicing Information System V1.1Document24 pagesSRS for Hardware Sales and Servicing Information System V1.1prashant_kumar552510No ratings yet
- Integration Patterns and PracticesDocument53 pagesIntegration Patterns and PracticesatifhassansiddiquiNo ratings yet
- Active Rules Based On Object Relational QueriesDocument106 pagesActive Rules Based On Object Relational QueriesJatin GeraNo ratings yet
- Corporate Security Practices 4490843Document12 pagesCorporate Security Practices 4490843saracaro13No ratings yet
- Feasibility Report Template 1.0Document16 pagesFeasibility Report Template 1.0Shubham GuptaNo ratings yet
- Software Requirement SpecificationDocument12 pagesSoftware Requirement SpecificationHafsa AhmedNo ratings yet
- SJ-20121213161606-024-ZXWR RNC (V3.12.10) Calling Trace Operation Guide PDFDocument72 pagesSJ-20121213161606-024-ZXWR RNC (V3.12.10) Calling Trace Operation Guide PDFAmirpasha FatemiNo ratings yet
- MSFT Privacy Guidelines For Developers. Read Section 2 (Page 26-46)Document51 pagesMSFT Privacy Guidelines For Developers. Read Section 2 (Page 26-46)Tomas KancyperNo ratings yet
- Drools Fusion User Guide: Version 5.5.0.beta1Document46 pagesDrools Fusion User Guide: Version 5.5.0.beta1Erwan BeauvergerNo ratings yet
- Ceng History X SRS - Music Recommendation SystemDocument24 pagesCeng History X SRS - Music Recommendation SystemJeck NoNo ratings yet
- Shift Scheduler Software Design SpecificationDocument24 pagesShift Scheduler Software Design SpecificationAditya RolaNo ratings yet
- Types of Operating SystemsDocument25 pagesTypes of Operating SystemsNilotpal Kalita100% (1)
- UTD eAppointment SRS Software RequirementsDocument25 pagesUTD eAppointment SRS Software Requirementsaravind pvNo ratings yet
- System Design Document Template: Approved byDocument20 pagesSystem Design Document Template: Approved byKat NekochanNo ratings yet
- Medical Shop C#Document88 pagesMedical Shop C#AyushNo ratings yet
- Software Paradigms (Lesson 8)Document25 pagesSoftware Paradigms (Lesson 8)BrijeshNo ratings yet
- Checkpoint FireWall 1Document176 pagesCheckpoint FireWall 1Fabricio Silva0% (1)
- NCC Group Whitepaper - Securing CI EnvironmentDocument18 pagesNCC Group Whitepaper - Securing CI EnvironmentLarbi JosephNo ratings yet
- Data MigrationDocument31 pagesData Migrationsridhar_e100% (1)
- Per Session 2 WB 1.0Document77 pagesPer Session 2 WB 1.0ashwani kumarNo ratings yet
- Kognitio Configuration and Maintenance Manual: Data Classification - PUBLICDocument117 pagesKognitio Configuration and Maintenance Manual: Data Classification - PUBLICGova Govardhan ReddyNo ratings yet
- Report 2 - System Design Specification TemplateDocument14 pagesReport 2 - System Design Specification TemplateOsama TariqNo ratings yet
- Introduction To Software Engineering Software Development Lifecycle Rescue Management SystemDocument29 pagesIntroduction To Software Engineering Software Development Lifecycle Rescue Management SystemkhadijaNo ratings yet
- Srs Document For University Management SystemDocument59 pagesSrs Document For University Management SystemLevko DovganNo ratings yet
- SOC SLA SummaryDocument13 pagesSOC SLA Summarydamola2real100% (3)
- Software Requirement Specifications: Submitted To: Mrs. Kakoli Banerjee Mrs. Rosy ChauhanDocument22 pagesSoftware Requirement Specifications: Submitted To: Mrs. Kakoli Banerjee Mrs. Rosy ChauhanArchit GargNo ratings yet
- Data MigrationDocument30 pagesData MigrationManisekaran Seetharaman100% (1)
- Final SRSDocument15 pagesFinal SRSAhmadNo ratings yet
- Pre-Production Testing: Best Practices & GuidanceDocument25 pagesPre-Production Testing: Best Practices & GuidanceRamamurthyNo ratings yet
- Software Requirements Specification For Scheduling SystemDocument41 pagesSoftware Requirements Specification For Scheduling SystemSāJø ApoNo ratings yet
- 525670986-Srs-Document-for-University-Management-SystemDocument59 pages525670986-Srs-Document-for-University-Management-Systemtanya2110215No ratings yet
- Software Requirements Specification: Exam EarnDocument22 pagesSoftware Requirements Specification: Exam EarnGurjyot SinghNo ratings yet
- Diaposa Requirements v2Document13 pagesDiaposa Requirements v2paragavhaleNo ratings yet
- Inputs and Outputs List Page:1/21: Example-9: Sequential Control of Induction MotorsDocument7 pagesInputs and Outputs List Page:1/21: Example-9: Sequential Control of Induction MotorsjupudiguptaNo ratings yet
- Inputs and Outputs List Page:1/6: Filling & TransferingDocument7 pagesInputs and Outputs List Page:1/6: Filling & TransferingjupudiguptaNo ratings yet
- Inputs and Outputs List Page:1/4: Example-5: ConveyorDocument4 pagesInputs and Outputs List Page:1/4: Example-5: ConveyorjupudiguptaNo ratings yet
- Inputs and Outputs List Page:1/4: EXAMPLE-3: Bottle FillingDocument7 pagesInputs and Outputs List Page:1/4: EXAMPLE-3: Bottle FillingjupudiguptaNo ratings yet
- Example: Punching Machine Page:1/4Document5 pagesExample: Punching Machine Page:1/4jupudiguptaNo ratings yet
- Welcome To All Participants: Plastics MachineryDocument78 pagesWelcome To All Participants: Plastics MachineryjupudiguptaNo ratings yet
- Tank filling control with feedbackDocument4 pagesTank filling control with feedbackjupudiguptaNo ratings yet
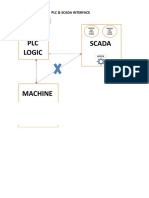
- PLC & Scada InterfaceDocument2 pagesPLC & Scada InterfacejupudiguptaNo ratings yet
- Scada DocDocument6 pagesScada DocjupudiguptaNo ratings yet
- Toggle logic inputs and outputsDocument6 pagesToggle logic inputs and outputsjupudiguptaNo ratings yet
- Teradata Developer Besant Technologies Course Content PDFDocument3 pagesTeradata Developer Besant Technologies Course Content PDFjupudiguptaNo ratings yet
- PlantsDocument1 pagePlantsjupudiguptaNo ratings yet
- Teradata Installation: Installation Steps For WindowsDocument4 pagesTeradata Installation: Installation Steps For WindowsjupudiguptaNo ratings yet
- Example: Punching Machine Page:1/4Document5 pagesExample: Punching Machine Page:1/4jupudiguptaNo ratings yet
- PLC & Scada InterfaceDocument2 pagesPLC & Scada InterfacejupudiguptaNo ratings yet
- SAP Cloud Platform Integration Training ContentDocument4 pagesSAP Cloud Platform Integration Training Contentjupudigupta67% (3)
- Home - HCI TrainingDocument13 pagesHome - HCI TrainingjupudiguptaNo ratings yet
- EST Lesson PlanDocument2 pagesEST Lesson PlanjupudiguptaNo ratings yet
- Data Concentrator Unit (DCU) : Visiontek-88GrDocument4 pagesData Concentrator Unit (DCU) : Visiontek-88GrjupudiguptaNo ratings yet
- Overview of SAP CPI - HandsoutDocument2 pagesOverview of SAP CPI - HandsoutjupudiguptaNo ratings yet
- Teradata Installation: Installation Steps For WindowsDocument4 pagesTeradata Installation: Installation Steps For WindowsjupudiguptaNo ratings yet
- Ximail30 XSDDocument2 pagesXimail30 XSDjupudiguptaNo ratings yet
- QuestionsDocument5 pagesQuestionsjupudiguptaNo ratings yet
- Narendra - SR SAP XI - PI EDI CONSULTANTDocument5 pagesNarendra - SR SAP XI - PI EDI CONSULTANTjupudiguptaNo ratings yet
- Smart by Gep Sap AdapterDocument6 pagesSmart by Gep Sap AdapterjupudiguptaNo ratings yet
- What Is A Data Warehouse?Document7 pagesWhat Is A Data Warehouse?jupudiguptaNo ratings yet
- What Is A Data Warehouse?Document7 pagesWhat Is A Data Warehouse?jupudiguptaNo ratings yet
- QuestionsDocument5 pagesQuestionsjupudiguptaNo ratings yet
- Activation ErrorDocument1 pageActivation ErrorjupudiguptaNo ratings yet
- ERP BasicsDocument14 pagesERP Basicsfinal_destination280100% (2)
- 5Document37 pages5shankari24381No ratings yet
- AchuthDocument4 pagesAchuthbarathNo ratings yet
- Not All Postings Are Listed in T-Code AIAB For Settlement (Or Message AW001 - "There Are No Line Items")Document3 pagesNot All Postings Are Listed in T-Code AIAB For Settlement (Or Message AW001 - "There Are No Line Items")Faheem AdeebNo ratings yet
- Industrial Training Report On SAPDocument34 pagesIndustrial Training Report On SAPPrakhar Bhatnagar100% (1)
- Human Capital Management (HR) : SAP AG 1999Document16 pagesHuman Capital Management (HR) : SAP AG 1999MeketeNo ratings yet
- Surtel Technologies: Sap AribaDocument11 pagesSurtel Technologies: Sap AribajvbyahattiNo ratings yet
- Case 6 Sap For AtlamDocument15 pagesCase 6 Sap For Atlamyumiko_sebastian201450% (2)
- Livelink Enterprise Archive vs. SAP Content Server - DETAILEDDocument56 pagesLivelink Enterprise Archive vs. SAP Content Server - DETAILEDObed SilvaNo ratings yet
- Database Upgrade Guide Upgrade To Sap Maxdb Database 7.8: UnixDocument34 pagesDatabase Upgrade Guide Upgrade To Sap Maxdb Database 7.8: UnixNelson EmeNo ratings yet
- SAP System Copy Solution SheetDocument2 pagesSAP System Copy Solution SheetWarwick81No ratings yet
- Inst Op2022Document92 pagesInst Op2022kevinhaoihuangNo ratings yet
- Accenture Clone and TestDocument4 pagesAccenture Clone and TestJozsef NagyNo ratings yet
- Skullcandy Case Study - Part OneDocument8 pagesSkullcandy Case Study - Part OneUthmanNo ratings yet
- Streamlining The Claims Process With SAP Claims ManagementDocument12 pagesStreamlining The Claims Process With SAP Claims ManagementDwi Pamudji SoetedjoNo ratings yet
- SAP DSS Role in Fonterra's Dairy Industry ExpansionDocument13 pagesSAP DSS Role in Fonterra's Dairy Industry ExpansionerangadddNo ratings yet
- Data Migration Approach During UpgradeDocument24 pagesData Migration Approach During Upgradeskmittal75No ratings yet
- Sap® Erp Upgrade and Testing Case: Haaga-Helia UAS: Titta-Maria SilvennoinenDocument170 pagesSap® Erp Upgrade and Testing Case: Haaga-Helia UAS: Titta-Maria Silvennoinensap pipoNo ratings yet
- Sap MM NotesDocument51 pagesSap MM Noteslostrider_991100% (2)
- ORGANISATION STRUCTURE TRAINING at Manjilas Double Horse For MBA Christ UniversityDocument36 pagesORGANISATION STRUCTURE TRAINING at Manjilas Double Horse For MBA Christ UniversityVishnu Raj86% (29)
- Post Processing FrameworkDocument2 pagesPost Processing Frameworkmr_rohitkumar88No ratings yet
- IBP Security GuideDocument60 pagesIBP Security GuideMario Cruz100% (3)
- SAP - SFDC IntegrationDocument17 pagesSAP - SFDC Integrationkalicharan13No ratings yet
- Hana PDFDocument7 pagesHana PDFDevender5194No ratings yet
- Pa33 Installation enDocument122 pagesPa33 Installation enmoorthyNo ratings yet
- 1355 V11 201502 BestPractices SoftwareChangeManagement V4eDocument37 pages1355 V11 201502 BestPractices SoftwareChangeManagement V4eroysapuNo ratings yet
- Sap Transportation Management (Sap TM)Document23 pagesSap Transportation Management (Sap TM)parthatripathi60% (1)
- SAP BASIS SecurityDocument5 pagesSAP BASIS SecuritykavinganNo ratings yet
- Lumira DesignerDocument2 pagesLumira Designervenkat143786No ratings yet
- Finance ExtenDocument15 pagesFinance Extensmile1alwaysNo ratings yet