You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Theory of LoveDocument6 pagesTheory of LoveShaurya KapoorNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Adobe Premiere Pro Help - Keyboard Shortcuts in Premiere Pro CC PDFDocument11 pagesAdobe Premiere Pro Help - Keyboard Shortcuts in Premiere Pro CC PDFMunna TeronNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Traditions of The North American Indians, Vol. 1 (Of 3) by Jones, James AthearnDocument125 pagesTraditions of The North American Indians, Vol. 1 (Of 3) by Jones, James AthearnGutenberg.org100% (2)
- GAIN - Flight Safety HandbookDocument180 pagesGAIN - Flight Safety HandbookDennis Groves100% (4)
- MotoSimEG-VRC Us PDFDocument816 pagesMotoSimEG-VRC Us PDFRafael SchroerNo ratings yet
- 3 Flowserve CatalogueDocument268 pages3 Flowserve CatalogueSudherson JagannathanNo ratings yet
- A Thread From @SwissRamble - #FCBarcelona Are Facing A Financial Crisis, Due To A Combination of Mismanagement and The COVID-19 (... )Document17 pagesA Thread From @SwissRamble - #FCBarcelona Are Facing A Financial Crisis, Due To A Combination of Mismanagement and The COVID-19 (... )Shaurya KapoorNo ratings yet
- Programmable Networks Service Ai ML Operation NewDocument6 pagesProgrammable Networks Service Ai ML Operation NewShaurya KapoorNo ratings yet
- Transforming Contact Centers Into Customer Engagement HubsDocument11 pagesTransforming Contact Centers Into Customer Engagement HubsShaurya KapoorNo ratings yet
- The Symbiotic Relation of Mythical Stories in Transforming Human LivesDocument7 pagesThe Symbiotic Relation of Mythical Stories in Transforming Human LivesShaurya KapoorNo ratings yet
- Virtual Machine Security Challenges: Case StudiesDocument14 pagesVirtual Machine Security Challenges: Case StudiesShaurya KapoorNo ratings yet
- An Investigation of Antecedents and Consequences oDocument48 pagesAn Investigation of Antecedents and Consequences oShaurya KapoorNo ratings yet
- Cloud Service Security & Application Vulnerability: April 2015Document9 pagesCloud Service Security & Application Vulnerability: April 2015Shaurya KapoorNo ratings yet
- French Sem3 PDFDocument44 pagesFrench Sem3 PDFShaurya KapoorNo ratings yet
- Intimacy, Passion and Commitment in Adult Romantic Relationships: A Test of The Triangular Theory of LoveDocument31 pagesIntimacy, Passion and Commitment in Adult Romantic Relationships: A Test of The Triangular Theory of LoveShaurya KapoorNo ratings yet
- Compassionate Love in Romantic Relationships: A Review and Some New FindingsDocument27 pagesCompassionate Love in Romantic Relationships: A Review and Some New FindingsShaurya KapoorNo ratings yet
- Experiment-1 Aim: Write A Program For Implementation of Bit StuffingDocument56 pagesExperiment-1 Aim: Write A Program For Implementation of Bit StuffingShaurya KapoorNo ratings yet
- The Psychology of Close Relationships: Fourteen Core PrinciplesDocument31 pagesThe Psychology of Close Relationships: Fourteen Core PrinciplesShaurya KapoorNo ratings yet
- Presentation On Fiber Distributed Data Interface (FDDI) &Document16 pagesPresentation On Fiber Distributed Data Interface (FDDI) &Shaurya KapoorNo ratings yet
- SPM Unit 1Document18 pagesSPM Unit 1Shaurya KapoorNo ratings yet
- Write A Shell Script To Find The Largest Among 3 Numbers. AnsDocument40 pagesWrite A Shell Script To Find The Largest Among 3 Numbers. AnsShaurya KapoorNo ratings yet
- Enterprise Computing With Java Practical File: Master of Computer ApplicationDocument45 pagesEnterprise Computing With Java Practical File: Master of Computer ApplicationShaurya KapoorNo ratings yet
- Modern Public-Key CryptosystemsDocument57 pagesModern Public-Key CryptosystemsShaurya KapoorNo ratings yet
- Enterprise Computing and J2EEDocument62 pagesEnterprise Computing and J2EEShaurya KapoorNo ratings yet
- SPM Unit 4Document10 pagesSPM Unit 4Shaurya KapoorNo ratings yet
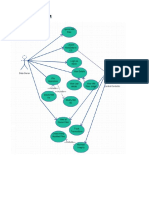
- Use Case DiagramDocument8 pagesUse Case DiagramShaurya KapoorNo ratings yet
- Monolithic Kernels and Micro-KernelsDocument2 pagesMonolithic Kernels and Micro-KernelsShaurya KapoorNo ratings yet
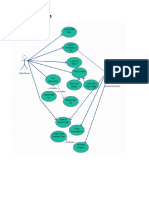
- Use Case DiagramDocument8 pagesUse Case DiagramShaurya KapoorNo ratings yet
- Acn NotesDocument36 pagesAcn NotesShaurya KapoorNo ratings yet
- Variables Are "Words" That Hold A Value. The Shell Enables You To Create, Assign, andDocument19 pagesVariables Are "Words" That Hold A Value. The Shell Enables You To Create, Assign, andShaurya KapoorNo ratings yet
- SIX SIGMA at GEDocument11 pagesSIX SIGMA at GE1987dezyNo ratings yet
- 21266-47576-1-PB GenderDocument25 pages21266-47576-1-PB GenderAira CamilleNo ratings yet
- Course Outline BA301-2Document4 pagesCourse Outline BA301-2drugs_182No ratings yet
- Status Report Cbms 2020Document20 pagesStatus Report Cbms 2020Lilian Belen Dela CruzNo ratings yet
- Exchanger Tube Data Analysis PDFDocument9 pagesExchanger Tube Data Analysis PDFArjed Ali ShaikhNo ratings yet
- Lib Burst GeneratedDocument37 pagesLib Burst GeneratedIgnacio Del RioNo ratings yet
- Lab #3Document10 pagesLab #3Najmul Puda PappadamNo ratings yet
- Univariate Homework 2 (1) CompletedDocument6 pagesUnivariate Homework 2 (1) CompletedNytaijah McAuleyNo ratings yet
- VTU 7 Sem B.E (CSE/ISE) : Java/ J2EeDocument57 pagesVTU 7 Sem B.E (CSE/ISE) : Java/ J2EeNikhilGuptaNo ratings yet
- E-Cell DSCOE IIT Bombay - 2018 19Document12 pagesE-Cell DSCOE IIT Bombay - 2018 19abhiNo ratings yet
- Thesis Evaluation FrameworkDocument5 pagesThesis Evaluation FrameworkRadheshyam ThakurNo ratings yet
- Davos ProgramDocument80 pagesDavos ProgramhamiltajNo ratings yet
- 0401110Document66 pages0401110HomeNo ratings yet
- Scientific Notation PDFDocument2 pagesScientific Notation PDFJAYSONNo ratings yet
- PSG Marijuana For Medical PurposesDocument5 pagesPSG Marijuana For Medical PurposesCKNW980No ratings yet
- G120 Cu240beDocument942 pagesG120 Cu240beRaphael Paulino BertiNo ratings yet
- 1960 Mower LearningtheoryDocument585 pages1960 Mower Learningtheoryfatty_mvNo ratings yet
- TEST - 3 - Code-C All India Aakash Test Series For JEE (Main) - 2020Document22 pagesTEST - 3 - Code-C All India Aakash Test Series For JEE (Main) - 2020Shivam NishadNo ratings yet
- Argumentative Essay TemplateDocument4 pagesArgumentative Essay Template민수No ratings yet
- Population QuestionsDocument79 pagesPopulation QuestionsBooNo ratings yet
- Dsto-Tn-1155 PRDocument52 pagesDsto-Tn-1155 PRGoutham BurraNo ratings yet
- Naac Uma Maha PandharpurDocument204 pagesNaac Uma Maha Pandharpurapi-191430885No ratings yet
- Intel (R) ME Firmware Integrated Clock Control (ICC) Tools User GuideDocument24 pagesIntel (R) ME Firmware Integrated Clock Control (ICC) Tools User Guidebox.office1003261No ratings yet
- Managerial LEADERSHIP P WrightDocument5 pagesManagerial LEADERSHIP P WrighttomorNo ratings yet
- Up LB Research Manual 2008Document168 pagesUp LB Research Manual 2008Eunice ChavezNo ratings yet