You might also like
- Implementing Real-Time Partitioned Convolution Algorithms On Conventional Operating SystemsDocument8 pagesImplementing Real-Time Partitioned Convolution Algorithms On Conventional Operating SystemsotringalNo ratings yet
- DSP Interview QuestionsDocument5 pagesDSP Interview QuestionsHaribabu Kadulla50% (2)
- Nursys E-Notify File and API Specifications v2.1.8 PDFDocument47 pagesNursys E-Notify File and API Specifications v2.1.8 PDFShahzad TariqNo ratings yet
- Icsps10 WindowDocument4 pagesIcsps10 WindowkondaraNo ratings yet
- Short Time Fourier TransformDocument39 pagesShort Time Fourier TransformKishore MylavarapuNo ratings yet
- Short Time Fourier TransformDocument37 pagesShort Time Fourier TransformHamada AlmasalmaNo ratings yet
- Ch9-Time Frequency WaveletDocument62 pagesCh9-Time Frequency WaveletkalajamunNo ratings yet
- L29: Fourier AnalysisDocument29 pagesL29: Fourier AnalysisHarshNo ratings yet
- Short-Time Fourier Transform - WikipediaDocument11 pagesShort-Time Fourier Transform - WikipediaEn Iyisi İnşaat MühendisiNo ratings yet
- Speech Analysis and Synthesis For STFTDocument17 pagesSpeech Analysis and Synthesis For STFTzsyed92No ratings yet
- STFTDocument3 pagesSTFTRaynald SumampouwNo ratings yet
- Effects in Frequency Domain: Stefania Serafin Music Informatics Fall 2004Document18 pagesEffects in Frequency Domain: Stefania Serafin Music Informatics Fall 2004Asad KhanNo ratings yet
- Week 6Document12 pagesWeek 6vidishashukla03No ratings yet
- 2.continuous Wavelet TechniquesDocument14 pages2.continuous Wavelet TechniquesremaravindraNo ratings yet
- Filter Bank: Insights into Computer Vision's Filter Bank TechniquesFrom EverandFilter Bank: Insights into Computer Vision's Filter Bank TechniquesNo ratings yet
- OFDM TutorialDocument23 pagesOFDM Tutoriallg900df5063No ratings yet
- OFDM Paper - Independent Study - RIT - Rafael SueroDocument22 pagesOFDM Paper - Independent Study - RIT - Rafael SueroRafael Clemente Suero SamboyNo ratings yet
- 752 Frequency ModulationDocument10 pages752 Frequency ModulationMiki ArsovskiNo ratings yet
- Short Time Fourier TransformDocument39 pagesShort Time Fourier Transformpratik shindeNo ratings yet
- Introduction To The Short-Time Fourier Transform (STFT) : Richard M. SternDocument23 pagesIntroduction To The Short-Time Fourier Transform (STFT) : Richard M. SternSabri BouloumaNo ratings yet
- PFFT Max/MSPDocument14 pagesPFFT Max/MSPIoana Tăleanu100% (1)
- Real-Time DSP Implementation of Audio Crosstalk Cancellation Using Mixed Uniform Partitioned ConvolutionDocument10 pagesReal-Time DSP Implementation of Audio Crosstalk Cancellation Using Mixed Uniform Partitioned ConvolutionAI Coordinator - CSC JournalsNo ratings yet
- Short Term Spectral Analysis, Modification Discrete Fourier Transform Synthesis, andDocument4 pagesShort Term Spectral Analysis, Modification Discrete Fourier Transform Synthesis, andDeepak Kumar Singh Res. Scholar., Dept. of Mechanical Engg., IIT (BHU)No ratings yet
- Task-01: Discrete Time Fourier TransformDocument5 pagesTask-01: Discrete Time Fourier TransformAsit44 gleNo ratings yet
- NVH Fallstudie Frequency AnalysisDocument5 pagesNVH Fallstudie Frequency Analysisreek_bhatNo ratings yet
- Short Time Fourier TransformDocument13 pagesShort Time Fourier TransformsssssssssssNo ratings yet
- Saramäki Polynomial Based Interpolation Filters Springer 2007Document32 pagesSaramäki Polynomial Based Interpolation Filters Springer 2007algebraic.sum19No ratings yet
- FFTs and Oscilloscopes A Practical GuideDocument8 pagesFFTs and Oscilloscopes A Practical GuidecasagrandeNo ratings yet
- ReportDocument5 pagesReportChokkarapu Anil100% (1)
- Dynamic Control of Frequency-Domain-Based Spectral TransformationsDocument13 pagesDynamic Control of Frequency-Domain-Based Spectral TransformationsSergio Nunez MenesesNo ratings yet
- Wavelet TransformDocument41 pagesWavelet Transformarshi khan100% (1)
- Wavlets in Control EngineeringDocument27 pagesWavlets in Control EngineeringSunil KumarNo ratings yet
- TEMJournalFebruary2019 56 64Document9 pagesTEMJournalFebruary2019 56 64Ioana GuțăNo ratings yet
- Facultad de Ingeniería Laboratorio de Análisis de SeñalesDocument6 pagesFacultad de Ingeniería Laboratorio de Análisis de SeñalesFernando DiegoNo ratings yet
- 3F3 3 Fast Fourier TransformDocument50 pages3F3 3 Fast Fourier TransformChalani PremadasaNo ratings yet
- Samplingrate BWDocument4 pagesSamplingrate BWRaveendranath KRNo ratings yet
- Short-Time Fourier Transform Analysis and Synthesis: P T E RDocument19 pagesShort-Time Fourier Transform Analysis and Synthesis: P T E Rsouvik5000No ratings yet
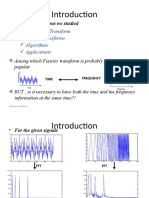
- in Previous Sessions We Studied: Meaning of Transform Types of Transforms Algorithms ApplicationsDocument35 pagesin Previous Sessions We Studied: Meaning of Transform Types of Transforms Algorithms ApplicationsOsama Mahmoud HamedNo ratings yet
- Packet 1Document4 pagesPacket 1rekhakambanNo ratings yet
- Tesche - The Fast Laplace TransformDocument25 pagesTesche - The Fast Laplace TransformbugbugbugbugNo ratings yet
- Achizitia in Timp Real A SemnalelorDocument10 pagesAchizitia in Timp Real A SemnalelorFawad HasanNo ratings yet
- Design and FPGA Implementation of Variable FIR Filters Using The Spectral Parameter Approximation and Time-Domain ApproachDocument5 pagesDesign and FPGA Implementation of Variable FIR Filters Using The Spectral Parameter Approximation and Time-Domain ApproachRahul SharmaNo ratings yet
- TFCLEAN: Time-Frequency Noise Suppression: TopicsDocument14 pagesTFCLEAN: Time-Frequency Noise Suppression: TopicsVijay YadavNo ratings yet
- Me'Scopeves Application Note #1: The FFT, Leakage, and WindowingDocument8 pagesMe'Scopeves Application Note #1: The FFT, Leakage, and Windowingho-faNo ratings yet
- FFT To WaveletDocument25 pagesFFT To WaveletHEET GUPTANo ratings yet
- DWT PaperDocument6 pagesDWT PaperLucas WeaverNo ratings yet
- Application of DFT Filter Bank To Power Frequency Harmonic MeasurementDocument5 pagesApplication of DFT Filter Bank To Power Frequency Harmonic Measurementfranchisca9999No ratings yet
- Continuous Fouriers Transform: Forward FT of A Continuous Signal Where Is Described AsDocument12 pagesContinuous Fouriers Transform: Forward FT of A Continuous Signal Where Is Described As宮能翔No ratings yet
- Lecture 16: Spectral Filtering: C Christopher S. Bretherton Winter 2015Document3 pagesLecture 16: Spectral Filtering: C Christopher S. Bretherton Winter 2015Priyo TenanNo ratings yet
- Oral Questions On DSP 2020-21Document41 pagesOral Questions On DSP 2020-21Pratibha VermaNo ratings yet
- The Lecture Contains:: Lecture 15: Sampling of Video Signals, Choice of Sampling Rates in Different Video SystemsDocument5 pagesThe Lecture Contains:: Lecture 15: Sampling of Video Signals, Choice of Sampling Rates in Different Video SystemsAdeoti OladapoNo ratings yet
- Second-Order Synchrosqueezing Transform or Invertible Reassignment? Towards Ideal Time-Frequency RepresentationsDocument26 pagesSecond-Order Synchrosqueezing Transform or Invertible Reassignment? Towards Ideal Time-Frequency RepresentationsPhong DangNo ratings yet
- Short-Time FFT, Multi-Taper Analysis & Filtering in SPM12Document27 pagesShort-Time FFT, Multi-Taper Analysis & Filtering in SPM12intang pingkiNo ratings yet
- Formal Definition : Orthonormal Wavelet and of The Integral Wavelet TransformDocument6 pagesFormal Definition : Orthonormal Wavelet and of The Integral Wavelet TransformAguirre UrNo ratings yet
- A Schroeder Reverberator Called JCRevDocument5 pagesA Schroeder Reverberator Called JCRevLaboratorio Sonido2No ratings yet
- Digital and Kalman Filtering: An Introduction to Discrete-Time Filtering and Optimum Linear Estimation, Second EditionFrom EverandDigital and Kalman Filtering: An Introduction to Discrete-Time Filtering and Optimum Linear Estimation, Second EditionNo ratings yet
- Single Channel Phase-Aware Signal Processing in Speech Communication: Theory and PracticeFrom EverandSingle Channel Phase-Aware Signal Processing in Speech Communication: Theory and PracticeNo ratings yet
- Slyt416 Ecg EegDocument18 pagesSlyt416 Ecg EegsakthyinNo ratings yet
- TEQIP Sponsored National Seminar On "ADVANCEMENT IN Biomaterials & Biomechanics" (Nsabb-2013) 12 July, 2013Document6 pagesTEQIP Sponsored National Seminar On "ADVANCEMENT IN Biomaterials & Biomechanics" (Nsabb-2013) 12 July, 2013souvik5000No ratings yet
- Automatic Text Detection Using Morphological Operations and InpaintingDocument5 pagesAutomatic Text Detection Using Morphological Operations and Inpaintingsouvik5000No ratings yet
- Achievements of FacultyDocument1 pageAchievements of Facultysouvik5000No ratings yet
- Introduction and History: Tissue ExpanderDocument9 pagesIntroduction and History: Tissue Expandersouvik5000No ratings yet
- Zambia Chapter 4 DDocument26 pagesZambia Chapter 4 Dsouvik5000No ratings yet
- Short-Time: FourierDocument14 pagesShort-Time: Fouriersouvik5000No ratings yet
- The Process of Feature Extraction in Automatic Speech Recognition System For Computer Machine Interaction With Humans: A ReviewDocument7 pagesThe Process of Feature Extraction in Automatic Speech Recognition System For Computer Machine Interaction With Humans: A Reviewsouvik5000No ratings yet
- Topic 10: The Fast Fourier Transform: ELEN E4810: Digital Signal ProcessingDocument37 pagesTopic 10: The Fast Fourier Transform: ELEN E4810: Digital Signal Processingsouvik5000No ratings yet
- Analysis0 2Document377 pagesAnalysis0 2souvik5000No ratings yet
- Fundamental Tools For Image RetrievalDocument24 pagesFundamental Tools For Image Retrievalsouvik5000No ratings yet
- Spectral Analysis of SignalsDocument0 pagesSpectral Analysis of Signalssouvik5000No ratings yet
- Short-Time Fourier Transform Analysis and Synthesis: P T E RDocument19 pagesShort-Time Fourier Transform Analysis and Synthesis: P T E Rsouvik5000No ratings yet
- BSPII Ch8 Spectrogram 2008Document6 pagesBSPII Ch8 Spectrogram 2008souvik5000No ratings yet
- Cepstral Analysis: Appendix 3Document3 pagesCepstral Analysis: Appendix 3souvik5000No ratings yet
- MFTDocument0 pagesMFTsouvik5000No ratings yet
- Scilab 6Document9 pagesScilab 6souvik5000No ratings yet
- 8 Cepstral AnalysisDocument24 pages8 Cepstral Analysissouvik5000No ratings yet
- GHS AP Stat TalkDocument8 pagesGHS AP Stat Talksouvik5000No ratings yet
- Cepstral Signal Analysis For Pitch Detection: 1.1 Definition of The Cepstral CoefficientsDocument3 pagesCepstral Signal Analysis For Pitch Detection: 1.1 Definition of The Cepstral Coefficientssouvik5000No ratings yet
- TEQIP Book Requirement: Gerard Blanchet Maurice CharbitDocument1 pageTEQIP Book Requirement: Gerard Blanchet Maurice Charbitsouvik5000No ratings yet
- 9 Linear Filters: (X (t), t ∈ Z) (β, j ∈ Z) (Y (t), t ∈ Z) − j), t ∈ Z,Document9 pages9 Linear Filters: (X (t), t ∈ Z) (β, j ∈ Z) (Y (t), t ∈ Z) − j), t ∈ Z,souvik5000No ratings yet
- Creating Volume Groups For Bidirectional RemoteDocument3 pagesCreating Volume Groups For Bidirectional Remotevignesh17jNo ratings yet
- DataStructure - Circular, Double Ended, Priority QueuesDocument29 pagesDataStructure - Circular, Double Ended, Priority Queuesaliyaraza150% (2)
- Changing The Rock Physics Function at Any Time in PetrelDocument4 pagesChanging The Rock Physics Function at Any Time in PetrelHalitch HadivitcheNo ratings yet
- To Check Whether String Belongs To A Grammar or Not: AlgorithmDocument34 pagesTo Check Whether String Belongs To A Grammar or Not: AlgorithmHisham KhanNo ratings yet
- SmartGWT Quick Start GuideDocument92 pagesSmartGWT Quick Start GuideGermán KruszewskiNo ratings yet
- Archivetempindex PHPDocument2 pagesArchivetempindex PHPVerlai Jhoser SanchezNo ratings yet
- Reports With XML Publisher: (Using BI Publisher and Microsoft Word) Connected Query ReportDocument5 pagesReports With XML Publisher: (Using BI Publisher and Microsoft Word) Connected Query ReportMunib MohsinNo ratings yet
- 18CSC205J Ex1to3Document17 pages18CSC205J Ex1to3Anshul RajputNo ratings yet
- Retro Gaming PDFDocument164 pagesRetro Gaming PDFVipper80No ratings yet
- Ekt120 Week06 Functions2Document25 pagesEkt120 Week06 Functions2Muhammad Faiz bin Ahmad ShafiNo ratings yet
- Frank Kane - Hands-On Data Science and Python Machine Learning - Perform Data Mining and Machine Learning Efficiently Using Python and Spark-Packt Publishing - Ebooks Account (2017) PDFDocument415 pagesFrank Kane - Hands-On Data Science and Python Machine Learning - Perform Data Mining and Machine Learning Efficiently Using Python and Spark-Packt Publishing - Ebooks Account (2017) PDFDavid Quirilao100% (4)
- HCNP-R&S-IERS Implementing Enterprise Routing and Switching Network Training V2.0Document480 pagesHCNP-R&S-IERS Implementing Enterprise Routing and Switching Network Training V2.0Teferi BarantoNo ratings yet
- OCR Project Report PDFDocument24 pagesOCR Project Report PDFvirali shahNo ratings yet
- SQL Topics: by Naresh Kumar B. NDocument9 pagesSQL Topics: by Naresh Kumar B. NKashyap MnvlNo ratings yet
- Frontline Solvers User GuideDocument271 pagesFrontline Solvers User Guideedwinap75No ratings yet
- Datasheet c78 739715Document10 pagesDatasheet c78 739715Mahmoud RamadanNo ratings yet
- Linear Time Invariant Systems - GATE Study Material in PDFDocument5 pagesLinear Time Invariant Systems - GATE Study Material in PDFTestbook BlogNo ratings yet
- VPC Lab InstructionsDocument75 pagesVPC Lab InstructionsrazzzzzzzzzzzNo ratings yet
- MLib Cheat Sheet DesignDocument1 pageMLib Cheat Sheet DesignSURAJ KATRENo ratings yet
- Data Manual: TMS320F28335, TMS320F28334, TMS320F28332Document100 pagesData Manual: TMS320F28335, TMS320F28334, TMS320F28332trantuan88No ratings yet
- An SAP Consultant - ABAP - Infotype Record Creation - HR - INFOTYPE - OPERATIONDocument2 pagesAn SAP Consultant - ABAP - Infotype Record Creation - HR - INFOTYPE - OPERATIONarunNo ratings yet
- Microsoft Word - Enhance The CRM WebClient UI With Custom Fields2Document21 pagesMicrosoft Word - Enhance The CRM WebClient UI With Custom Fields2Peter Van AlphenNo ratings yet
- Grade 11 ICT - Class TaskDocument5 pagesGrade 11 ICT - Class TaskCraigNo ratings yet
- HSST Computer Science 2013 (SC - ST) PDFDocument7 pagesHSST Computer Science 2013 (SC - ST) PDFSooraj Rajmohan100% (2)
- GtkwaveDocument159 pagesGtkwaveMinu MathewNo ratings yet
- Compulsory To All Branch 14Phdrm: Research MethodologyDocument6 pagesCompulsory To All Branch 14Phdrm: Research MethodologyAmbica AnnavarapuNo ratings yet
- DIH 9.6 Lab 1 Automated Publications and SubscriptionsDocument57 pagesDIH 9.6 Lab 1 Automated Publications and Subscriptionsecho chenNo ratings yet
- Global Server Load Balancing: Cns 205-5I: Citrix Netscaler 10.5 Essentials and NetworkingDocument37 pagesGlobal Server Load Balancing: Cns 205-5I: Citrix Netscaler 10.5 Essentials and NetworkingsudharaghavanNo ratings yet
- MERLIN Tech ManualBDocument37 pagesMERLIN Tech ManualBThuận Béo MậpNo ratings yet