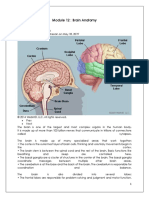
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5814)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1092)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (845)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (348)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Rationale For Lesson PlanDocument3 pagesRationale For Lesson Planapi-35753807178% (9)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- English Lexicology 3 Year, 6 Semester: You're Looking Very Smart in Your New Clothes!Document4 pagesEnglish Lexicology 3 Year, 6 Semester: You're Looking Very Smart in Your New Clothes!Julia SalashnikNo ratings yet
- Wida Standards Grades Prek-5Document44 pagesWida Standards Grades Prek-5api-218642075100% (1)
- Referential and Emotive MeaningsDocument3 pagesReferential and Emotive MeaningsDewi AnjeliNo ratings yet
- Esl Grade 1 CatDocument5 pagesEsl Grade 1 Catapi-106728792No ratings yet
- Grade 3 Summer Pack Session 2024-25Document114 pagesGrade 3 Summer Pack Session 2024-25theconceptvirtualschoolNo ratings yet
- SOW ENGLISH YEAR 2 2023-2024 by RozayusAcademyDocument13 pagesSOW ENGLISH YEAR 2 2023-2024 by RozayusAcademyzulianazunainiNo ratings yet
- A Study of The Phonological Differences Between American English and British EnglishDocument6 pagesA Study of The Phonological Differences Between American English and British EnglishalebagildasNo ratings yet
- Demenchuk Contrastive-LexicologyDocument147 pagesDemenchuk Contrastive-LexicologyЕлена БалабанNo ratings yet
- Intermediate I. Lesson Plan Submittal. 2019Document56 pagesIntermediate I. Lesson Plan Submittal. 2019juan vNo ratings yet
- ELS 102 Theories of Language Module 12-15Document13 pagesELS 102 Theories of Language Module 12-15LovelyLoey ParkNo ratings yet
- Lexico - Semantic LevelsDocument9 pagesLexico - Semantic Levelsmahparah2002No ratings yet
- Primary Year 3 SK SOWDocument266 pagesPrimary Year 3 SK SOWkamalskss72No ratings yet
- Hal 131 PDFDocument237 pagesHal 131 PDFDiah MaulidyaNo ratings yet
- Practical Research 2: Quarter 1 - Module 5: Research Questions, Scope, & DelimitationDocument17 pagesPractical Research 2: Quarter 1 - Module 5: Research Questions, Scope, & DelimitationDivina Grace Rodriguez - Librea100% (1)
- Nur Fadillah - SEMANTIC TRANSLATIONDocument3 pagesNur Fadillah - SEMANTIC TRANSLATIONDillaa VokavokahNo ratings yet
- Eng 223 Advanced English Composition IDocument121 pagesEng 223 Advanced English Composition IAyegboNo ratings yet
- Peculiarities of Translation of Works of Fantasy GenreDocument4 pagesPeculiarities of Translation of Works of Fantasy GenreResearch ParkNo ratings yet
- Word Formation in Tamil PDFDocument96 pagesWord Formation in Tamil PDFStanly Jebaroons SNo ratings yet
- Hanja Lesson 1 - 大, 小, 中, 山, 門Document8 pagesHanja Lesson 1 - 大, 小, 中, 山, 門hvsjgsNo ratings yet
- Summary of English Course MaterialDocument2 pagesSummary of English Course MaterialYemima Ratu S ANo ratings yet
- The Commonest Types of Metaphor in EnglishDocument21 pagesThe Commonest Types of Metaphor in EnglishmanuNo ratings yet
- NR CRT - Detalieri Tematice - Elemente de Construcţie A Comunicǎrii - Funcţii Comunicative 1.1 1.4 4.3Document9 pagesNR CRT - Detalieri Tematice - Elemente de Construcţie A Comunicǎrii - Funcţii Comunicative 1.1 1.4 4.3Alina Mihaela CiubotaruNo ratings yet
- Sow Year 2 2021-Penjajaran Kurikulum 2.0Document11 pagesSow Year 2 2021-Penjajaran Kurikulum 2.0farhanNo ratings yet
- Cantonese 3 Minute Kobo AudiobookDocument201 pagesCantonese 3 Minute Kobo AudiobookslojnotakNo ratings yet
- English Language As A Tool in Business CommunicationDocument16 pagesEnglish Language As A Tool in Business Communicationpshantanu123No ratings yet
- Curriculum Map English 10Document16 pagesCurriculum Map English 10Mark Cesar VillanuevaNo ratings yet
- Module 3Document55 pagesModule 3CLARIZZE JAINE MANALONo ratings yet
- Life 2E Advanced Scope and SequenceDocument4 pagesLife 2E Advanced Scope and SequenceLukas Miguel CassianoNo ratings yet
- Scientific Writing (Pebrini Ginting) 2182131007Document13 pagesScientific Writing (Pebrini Ginting) 2182131007pebriniNo ratings yet