You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (842)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5807)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Linear Regression: Prepared by Muralidharan NDocument34 pagesLinear Regression: Prepared by Muralidharan NZohaib Imam77% (13)
- Probability & Statistics Practice Final Exam and AnswersDocument8 pagesProbability & Statistics Practice Final Exam and Answersmisterjags0% (1)
- Biostatistics and Research Methods Exercise 1Document5 pagesBiostatistics and Research Methods Exercise 1elias50% (2)
- Control ChartsDocument136 pagesControl ChartsSowmya VisinigiriNo ratings yet
- María Dolores Ugarte, Ana F. Militino, Alan T. Arnholt - Probability and Statistics With R-CRC (2008)Document694 pagesMaría Dolores Ugarte, Ana F. Militino, Alan T. Arnholt - Probability and Statistics With R-CRC (2008)vinay kumarNo ratings yet
- Regression Analysis Q&A ImpDocument3 pagesRegression Analysis Q&A ImpAniKet B0% (1)
- 4-1 - How To Use SmartPLS Software - Structural Model Assessment - 3-5-14Document23 pages4-1 - How To Use SmartPLS Software - Structural Model Assessment - 3-5-14Dedek Putri LestariNo ratings yet
- MailChimp - Audience (Updated On 31 March 2022)Document877 pagesMailChimp - Audience (Updated On 31 March 2022)HaslindaNo ratings yet
- SN & SV November 2016Document7 pagesSN & SV November 2016HaslindaNo ratings yet
- SN & SV - May 2016Document8 pagesSN & SV - May 2016HaslindaNo ratings yet
- XPM Info Request Report - NK - 24032022Document6 pagesXPM Info Request Report - NK - 24032022HaslindaNo ratings yet
- SN & SV June 2016Document10 pagesSN & SV June 2016HaslindaNo ratings yet
- SN & SV April Til May 2016Document5 pagesSN & SV April Til May 2016HaslindaNo ratings yet
- SN & SV 2017 - JuneDocument33 pagesSN & SV 2017 - JuneHaslindaNo ratings yet
- SN & SV 2017 - MarchDocument21 pagesSN & SV 2017 - MarchHaslindaNo ratings yet
- SN & SV - December 2016Document6 pagesSN & SV - December 2016HaslindaNo ratings yet
- SN & SV 2017 - JanuaryDocument5 pagesSN & SV 2017 - JanuaryHaslindaNo ratings yet
- 1S2C Meeting: Date Time Venue Prepared by in Attendance Chairperson Issue Discussion PIC DatelineDocument1 page1S2C Meeting: Date Time Venue Prepared by in Attendance Chairperson Issue Discussion PIC DatelineHaslindaNo ratings yet
- SN & SV 2017 - FebruaryDocument21 pagesSN & SV 2017 - FebruaryHaslindaNo ratings yet
- Birth Certificate Status SOPDocument5 pagesBirth Certificate Status SOPHaslindaNo ratings yet
- Sales Operation Dept - Structure 2016 (May Pan)Document51 pagesSales Operation Dept - Structure 2016 (May Pan)HaslindaNo ratings yet
- Complain Report - Minor & MajorDocument10 pagesComplain Report - Minor & MajorHaslindaNo ratings yet
- CryoCare Insurance Renewal (Revised)Document11 pagesCryoCare Insurance Renewal (Revised)HaslindaNo ratings yet
- Annual Storage Fee SOPDocument8 pagesAnnual Storage Fee SOPHaslindaNo ratings yet
- Change of Details 1s2c SOPDocument6 pagesChange of Details 1s2c SOPHaslindaNo ratings yet
- Customer Service Executive Performance Score Card: March - December, 2015Document5 pagesCustomer Service Executive Performance Score Card: March - December, 2015HaslindaNo ratings yet
- Request For Copy of Client DocumentDocument10 pagesRequest For Copy of Client DocumentHaslindaNo ratings yet
- Jadad ScoreDocument2 pagesJadad Scoreandus007100% (1)
- Para MapDocument29 pagesPara MapananyaajatasatruNo ratings yet
- Lecture10 Regression2 TS PDFDocument22 pagesLecture10 Regression2 TS PDFsnoozermanNo ratings yet
- Econometrics Chapter 8 PPT SlidesDocument42 pagesEconometrics Chapter 8 PPT SlidesIsabelleDwight100% (1)
- School Dropout Across Indian States and Uts: An Econometric StudyDocument8 pagesSchool Dropout Across Indian States and Uts: An Econometric StudyNaveen KumarNo ratings yet
- Computers & Education: Daniel Darghan Felisoni, Alexandra Strommer Godoi MarkDocument13 pagesComputers & Education: Daniel Darghan Felisoni, Alexandra Strommer Godoi MarkZehra SafderNo ratings yet
- Number of Factors SPSS-R2Document14 pagesNumber of Factors SPSS-R2sen xNo ratings yet
- Mining Class ComparisonsDocument4 pagesMining Class Comparisonsmurali_20c100% (1)
- PDF 3 Statistics and Probability g11 Quarter 4 Module 3 Formulating Null and Alternative HypothesesDocument27 pagesPDF 3 Statistics and Probability g11 Quarter 4 Module 3 Formulating Null and Alternative HypothesesJudy Ann AbalosNo ratings yet
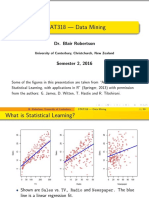
- STAT318 - Data Mining: Dr. Blair RobertsonDocument39 pagesSTAT318 - Data Mining: Dr. Blair RobertsonCesilyNo ratings yet
- Item Parceling Strategies in SEM: Investigating The Subtle Effects of Unmodeled Secondary ConstructsDocument24 pagesItem Parceling Strategies in SEM: Investigating The Subtle Effects of Unmodeled Secondary ConstructsnalakacwNo ratings yet
- Confirmatory Factor Analysis Using AMOS: Step 1: Launch The AMOS SoftwareDocument12 pagesConfirmatory Factor Analysis Using AMOS: Step 1: Launch The AMOS Softwareanjana2014No ratings yet
- Sampling Methods in Clinical Research An Educational ReviewDocument3 pagesSampling Methods in Clinical Research An Educational Reviewjoke clubNo ratings yet
- Manpower Planning - CHRP 2021Document31 pagesManpower Planning - CHRP 2021Fandi Al-HafizhNo ratings yet
- M4-Data Management 1.2Document22 pagesM4-Data Management 1.2ROSEALLEXANDRA ESPARAGONo ratings yet
- Res12 Module 2Document20 pagesRes12 Module 2Yanchen KylaNo ratings yet
- SPSS Answers (Chapter 12)Document15 pagesSPSS Answers (Chapter 12)Abhijit SinghNo ratings yet
- Module 4 (Data Management) - Math 101Document8 pagesModule 4 (Data Management) - Math 101Flory CabaseNo ratings yet
- Sta 131 Complete NoteDocument33 pagesSta 131 Complete NoteAbuNo ratings yet
- Talaid, Czar Lexus G. Bem 109 - Probability and Statistics Midterm ExamDocument2 pagesTalaid, Czar Lexus G. Bem 109 - Probability and Statistics Midterm ExamElison AngelesNo ratings yet
- Predictive Models Receiver-Operating Characteristic Analysis For Evaluating Diagnostic Tests andDocument5 pagesPredictive Models Receiver-Operating Characteristic Analysis For Evaluating Diagnostic Tests andLucila Figueroa GalloNo ratings yet
- Casey 1985Document19 pagesCasey 1985Fanita ArtisariNo ratings yet
- Lab 6 WorksheetDocument2 pagesLab 6 WorksheetPohuyistNo ratings yet