You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Skills in Mathematics Integral Calculus For JEE Main and Advanced 2022Document319 pagesSkills in Mathematics Integral Calculus For JEE Main and Advanced 2022Harshil Nagwani100% (3)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Motor of Pump HandbookDocument252 pagesMotor of Pump Handbookhithr1No ratings yet
- Advanced Methods For Determining The Origin of Vapor Cloud Explosions Case StudyDocument28 pagesAdvanced Methods For Determining The Origin of Vapor Cloud Explosions Case StudyСергей АлексеевNo ratings yet
- Transformer ProtectionDocument6 pagesTransformer Protectionapi-3743746100% (2)
- Machine Fault Signature AnalysisDocument10 pagesMachine Fault Signature AnalysisKotha MahipalNo ratings yet
- Spec1and2 WA BookDocument361 pagesSpec1and2 WA BookTHEUNDEADKING100% (1)
- Plant Commissioning Start Up ProcedureDocument100 pagesPlant Commissioning Start Up Proceduremsaad292% (124)
- Woodward Industrial Turbine ControlDocument16 pagesWoodward Industrial Turbine ControlhrstgaNo ratings yet
- Communication Systems: Phasor & Line SpectraDocument20 pagesCommunication Systems: Phasor & Line SpectraMubashir Ghaffar100% (1)
- CS50 NotesDocument2 pagesCS50 NotesFelix WongNo ratings yet
- Japan-ASEAN: Asian DX Promotion Project: © 2019 JERA Co., Inc. All Rights ReservedDocument10 pagesJapan-ASEAN: Asian DX Promotion Project: © 2019 JERA Co., Inc. All Rights ReservedtinozasableNo ratings yet
- Tabu PDFDocument12 pagesTabu PDFtinozasableNo ratings yet
- EE263 Homework Problems Lecture 2 - Linear Functions and ExamplesDocument154 pagesEE263 Homework Problems Lecture 2 - Linear Functions and Examplestinozasable100% (1)
- Plagiarism: Importance of Awareness"Document8 pagesPlagiarism: Importance of Awareness"tinozasableNo ratings yet
- 2A2 Signal Conditioning L1 Notes CollinsDocument138 pages2A2 Signal Conditioning L1 Notes CollinsKev107No ratings yet
- 2A2 Signal Conditioning L1 Notes CollinsDocument138 pages2A2 Signal Conditioning L1 Notes CollinsKev107No ratings yet
- 2A2 Signal Conditioning L1 Notes CollinsDocument138 pages2A2 Signal Conditioning L1 Notes CollinsKev107No ratings yet
- 2A2 Signal Conditioning L1 Notes CollinsDocument138 pages2A2 Signal Conditioning L1 Notes CollinsKev107No ratings yet
- Biomass Power Plant Control OperationDocument10 pagesBiomass Power Plant Control OperationtinozasableNo ratings yet
- Teaching Scheme For B.Tech "Industrial & Production Engineering"Document61 pagesTeaching Scheme For B.Tech "Industrial & Production Engineering"Sasank SaiNo ratings yet
- Pseudo 1Document1 pagePseudo 1Chamari JayawanthiNo ratings yet
- P1-Set TheoryDocument41 pagesP1-Set TheoryDipanwita DebnathNo ratings yet
- SubtractorDocument11 pagesSubtractorRocky SamratNo ratings yet
- Math Models of Physics ProblemsDocument29 pagesMath Models of Physics ProblemsSsj KakarottNo ratings yet
- Retinal Problems and Its Analysis Using Image Processing A ReviewDocument6 pagesRetinal Problems and Its Analysis Using Image Processing A ReviewSandeep MendhuleNo ratings yet
- Synthetic Division ReviewDocument3 pagesSynthetic Division ReviewLailah Rose AngkiNo ratings yet
- Mathematics Memorandum Grade 8 November 2018Document11 pagesMathematics Memorandum Grade 8 November 2018Kutlwano TemaNo ratings yet
- 1 ShaftDocument20 pages1 ShaftAJ BantayNo ratings yet
- Mathematics: Quarter 2 - Module 11: Dividing Decimal With Up To 2 Decimal PlacesDocument9 pagesMathematics: Quarter 2 - Module 11: Dividing Decimal With Up To 2 Decimal PlaceszytwnklNo ratings yet
- Chem Lab 7sDocument7 pagesChem Lab 7sChantelle LimNo ratings yet
- UTech CMP1025 Tutorial 3Document2 pagesUTech CMP1025 Tutorial 3Leia MichaelsonNo ratings yet
- Game Theory and Business Strategy: Individual Assignment 2Document2 pagesGame Theory and Business Strategy: Individual Assignment 2PKNo ratings yet
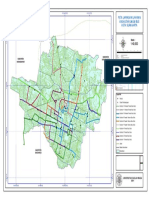
- Peta Jaringan Layanan Angkutan UmumDocument1 pagePeta Jaringan Layanan Angkutan UmumARFICONo ratings yet
- Work, Energy, Power: Chapter 7 in A NutshellDocument31 pagesWork, Energy, Power: Chapter 7 in A NutshellArun Kumar AruchamyNo ratings yet
- Rock Mechanics Fundamentals: Foot) - What Is Its Specific Gravity?Document18 pagesRock Mechanics Fundamentals: Foot) - What Is Its Specific Gravity?Ghulam Mohyuddin SohailNo ratings yet
- Product Data: Real-Time Frequency Analyzer - Type 2143 Dual Channel Real-Time Frequency Analyzers - Types 2144, 2148/7667Document12 pagesProduct Data: Real-Time Frequency Analyzer - Type 2143 Dual Channel Real-Time Frequency Analyzers - Types 2144, 2148/7667jhon vargasNo ratings yet
- Yaron Herman - ThesisDocument115 pagesYaron Herman - ThesisBojan MarjanovicNo ratings yet
- Tutorial 1Document2 pagesTutorial 1Shahidin ShahNo ratings yet
- Generalized Confusion Matrix For Multiple ClassesDocument3 pagesGeneralized Confusion Matrix For Multiple ClassesFira SukmanisaNo ratings yet
- MathDocument5 pagesMathvickimabelli100% (1)
- The Journal of Space Syntax (JOSS)Document9 pagesThe Journal of Space Syntax (JOSS)Luma DaradkehNo ratings yet
- المعاصر - ماث - 3 ع - ترم 2 - ذاكرولي PDFDocument798 pagesالمعاصر - ماث - 3 ع - ترم 2 - ذاكرولي PDFTarekNo ratings yet
- Quiz 4Document6 pagesQuiz 4William Jordache SaraivaNo ratings yet