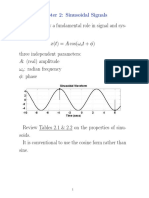
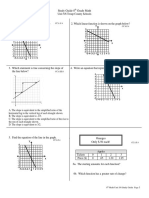
You might also like
- BF 01183737Document12 pagesBF 01183737Itay GelNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Week 9: PHY 305 Classical Mechanics Instructor: Sebastian W Uster, IISER Bhopal, 2020Document11 pagesWeek 9: PHY 305 Classical Mechanics Instructor: Sebastian W Uster, IISER Bhopal, 2020Keijo SalonenNo ratings yet
- Sixth Term Examination Papers Mathematics 3: Monday 23 June 2008Document8 pagesSixth Term Examination Papers Mathematics 3: Monday 23 June 2008hmphryNo ratings yet
- ISI MStat 08Document5 pagesISI MStat 08api-26401608No ratings yet
- 3.05 3.06 Moments and Moment Generating Function PDFDocument8 pages3.05 3.06 Moments and Moment Generating Function PDFDeepak ChaudharyNo ratings yet
- 6 Averages and The Relationship Between The Partition Func-Tion and Thermodynamic QuantitiesDocument1 page6 Averages and The Relationship Between The Partition Func-Tion and Thermodynamic QuantitiesJaydeep SinghNo ratings yet
- N-Dimensional Gaussian Cumulative FunctionDocument8 pagesN-Dimensional Gaussian Cumulative FunctionmsayalaNo ratings yet
- Bijective Coding of Automorphisms of TheDocument2 pagesBijective Coding of Automorphisms of TheLauro CésarNo ratings yet
- PHYSICS HOMEWORKDocument13 pagesPHYSICS HOMEWORKAdam ChanNo ratings yet
- Introduction To Real Analysis MATH 2001: Juris Stepr AnsDocument27 pagesIntroduction To Real Analysis MATH 2001: Juris Stepr AnsSandeep SajuNo ratings yet
- A Summary of Basic Vibration Theory: Degree-Of-Freedom BlueDocument22 pagesA Summary of Basic Vibration Theory: Degree-Of-Freedom BlueRui Pedro Chedas SampaioNo ratings yet
- Multivariate Normal DistributionDocument9 pagesMultivariate Normal DistributionccffffNo ratings yet
- Boyce ODEch 3 S 7 P 05Document3 pagesBoyce ODEch 3 S 7 P 05Josh BarrogaNo ratings yet
- Two Proofs of The Central Limit TheoremDocument13 pagesTwo Proofs of The Central Limit Theoremavi_weberNo ratings yet
- SlidesDocument38 pagesSlidesKurt RobertsNo ratings yet
- Practice Quiz 2 SolutionsDocument4 pagesPractice Quiz 2 SolutionsGeorge TreacyNo ratings yet
- , x, - . -, x f (x, x, - . -, x, x, - . -, x, x, - . -, x, x, - . -, x, x, - . -, x, σ, - . -, σ ∈Document5 pages, x, - . -, x f (x, x, - . -, x, x, - . -, x, x, - . -, x, x, - . -, x, x, - . -, x, σ, - . -, σ ∈guido360No ratings yet
- Method of Moments: Topic 13Document9 pagesMethod of Moments: Topic 13Zeeshan AhmedNo ratings yet
- Third and Fourth Binomial CoefficientsDocument4 pagesThird and Fourth Binomial Coefficientslab_bNo ratings yet
- Solution of Wave EquationDocument7 pagesSolution of Wave Equationjeetendra222523No ratings yet
- Two-D Triangular Ising Model ThermodynamicsDocument16 pagesTwo-D Triangular Ising Model ThermodynamicsSaroj ChhatoiNo ratings yet
- Lecture3 Coupled OscillatorsDocument6 pagesLecture3 Coupled OscillatorsDiego ErasoNo ratings yet
- Random Signals: 1 Kolmogorov's Axiomatic Definition of ProbabilityDocument14 pagesRandom Signals: 1 Kolmogorov's Axiomatic Definition of ProbabilitySeham RaheelNo ratings yet
- Geometry of Multiple Zeta ValuesDocument9 pagesGeometry of Multiple Zeta ValuesqwertyNo ratings yet
- 4707 StirlingDocument6 pages4707 StirlingCHEMICALSNo ratings yet
- Calculus Homework - PalumboDocument1 pageCalculus Homework - PalumboMatteo Gerardo PalumboNo ratings yet
- Solution Set 2Document10 pagesSolution Set 2TomicaTomicatomicaNo ratings yet
- TMRCA EstimatesDocument9 pagesTMRCA Estimatesdavejphys100% (1)
- Physics 105. Mechanics. Professor DineDocument1 pagePhysics 105. Mechanics. Professor DineqftgaugeNo ratings yet
- CLT PDFDocument13 pagesCLT PDFsalmanNo ratings yet
- A Collatz-Type Conjecture On The Set of Rational NumbersDocument7 pagesA Collatz-Type Conjecture On The Set of Rational NumbersvahidNo ratings yet
- Fourier Series Expansion of Functions in Two or More DimensionsDocument3 pagesFourier Series Expansion of Functions in Two or More DimensionsIgor GjorgjievNo ratings yet
- Jackson (Some) SolutionsDocument12 pagesJackson (Some) SolutionsKapila WijayaratneNo ratings yet
- CH 13Document19 pagesCH 13Eufemio MorenoNo ratings yet
- Solutions To The 67th William Lowell Putnam Mathematical Competition Saturday, December 2, 2006Document8 pagesSolutions To The 67th William Lowell Putnam Mathematical Competition Saturday, December 2, 2006Ganesh KumarNo ratings yet
- 18.950 Differential Geometry: Mit OpencoursewareDocument12 pages18.950 Differential Geometry: Mit OpencoursewarePhi Tien CuongNo ratings yet
- Collatz Conjecture ProofDocument6 pagesCollatz Conjecture ProofThiago da Silva VieiraNo ratings yet
- Problem of the Month: Counting sums of powers of 3 between 10^6 and 2x10^6Document5 pagesProblem of the Month: Counting sums of powers of 3 between 10^6 and 2x10^6Nguyen DuyNo ratings yet
- Tensor AnalysisDocument23 pagesTensor AnalysislordarunsunnyNo ratings yet
- On A P-Adic Julia SetDocument2 pagesOn A P-Adic Julia SetdmtriNo ratings yet
- Abney McPeek An NGDocument23 pagesAbney McPeek An NGMohammad Imran ShafiNo ratings yet
- Basic Notions and Examples: 2.1 The Notion of A Dynamical SystemDocument20 pagesBasic Notions and Examples: 2.1 The Notion of A Dynamical SystemluisNo ratings yet
- CH 02Document30 pagesCH 02KavunNo ratings yet
- Gambling, Random Walks and The Central Limit Theorem: 3.1 Random Variables and Laws of Large Num-BersDocument59 pagesGambling, Random Walks and The Central Limit Theorem: 3.1 Random Variables and Laws of Large Num-BersRajulNo ratings yet
- Calogero-Moser Hierarchy and KP HierarchyDocument8 pagesCalogero-Moser Hierarchy and KP Hierarchyhelmantico1970No ratings yet
- 104 Inverse TrigsdfsdDocument6 pages104 Inverse TrigsdfsdJinnat AdamNo ratings yet
- Square Roots 7Document5 pagesSquare Roots 7tomchoopperNo ratings yet
- Computing the Characteristic PolynomialDocument8 pagesComputing the Characteristic Polynomialblackdawn201No ratings yet
- 08 Aos674Document30 pages08 Aos674siti hayatiNo ratings yet
- Electronic Journal of Combinatorial Number TheoryDocument7 pagesElectronic Journal of Combinatorial Number TheoryEddie NugentNo ratings yet
- MTH4100 Calculus I: Lecture Notes For Week 3 Thomas' Calculus, Sections 1.5, 1.6, 2.1, 2.2 and 2.4Document14 pagesMTH4100 Calculus I: Lecture Notes For Week 3 Thomas' Calculus, Sections 1.5, 1.6, 2.1, 2.2 and 2.4Roy VeseyNo ratings yet
- Col LatzDocument6 pagesCol LatzItsos SotirisNo ratings yet
- Chapter 4 Power SeriesDocument55 pagesChapter 4 Power SeriesThalagawali RajagopalNo ratings yet
- 1 The Euler Phi FunctionDocument19 pages1 The Euler Phi FunctionRico LeeNo ratings yet
- 91070Document9 pages91070atomdNo ratings yet
- LM 741Document16 pagesLM 741SetinkNo ratings yet
- 161 09595 0 Irf540nDocument10 pages161 09595 0 Irf540nindianhitsNo ratings yet
- UPSC Odia Literature OptionalDocument2 pagesUPSC Odia Literature OptionalTanmaya Tapaswini TripathyNo ratings yet
- 2N4401TAR MMSZ4V3T1G. Mmsz4V3T1G 2N4401G 2N4401RLRPG 2N4401RLRAG. 2N4401RLRAGDocument9 pages2N4401TAR MMSZ4V3T1G. Mmsz4V3T1G 2N4401G 2N4401RLRPG 2N4401RLRAG. 2N4401RLRAGTanmaya Tapaswini TripathyNo ratings yet
- 1N4001 - 1N4007 1.0A Rectifier Features: Not Recommended For New Design USEDocument3 pages1N4001 - 1N4007 1.0A Rectifier Features: Not Recommended For New Design USETanmaya Tapaswini TripathyNo ratings yet
- Notification For The Posts of Gramin Dak Sevaks Cycle - Iii/2020-2021 Odisha CircleDocument132 pagesNotification For The Posts of Gramin Dak Sevaks Cycle - Iii/2020-2021 Odisha CircleTanmaya Tapaswini TripathyNo ratings yet
- 1N4001 - 1N4007 1.0A Rectifier Features: Not Recommended For New Design USEDocument3 pages1N4001 - 1N4007 1.0A Rectifier Features: Not Recommended For New Design USETanmaya Tapaswini TripathyNo ratings yet
- Compound Word ListDocument15 pagesCompound Word ListMpscTargetNo ratings yet
- Results for Gramin Dak Sevak Recruitment in Odisha CircleDocument149 pagesResults for Gramin Dak Sevak Recruitment in Odisha CirclepraneshNo ratings yet
- 1N4001, 1N4002, 1N4003, 1N4004, 1N4005, 1N4006, 1N4007: Vishay General SemiconductorDocument5 pages1N4001, 1N4002, 1N4003, 1N4004, 1N4005, 1N4006, 1N4007: Vishay General SemiconductorTanmaya Tapaswini TripathyNo ratings yet
- Digital Electronics Notes 4 IsroDocument15 pagesDigital Electronics Notes 4 Isroresearch4maniNo ratings yet
- Reasoning Test Placement Papers: Answer: Option BDocument9 pagesReasoning Test Placement Papers: Answer: Option BdeviNo ratings yet
- Q. 1 - Q. 25 Carry One Mark Each.: X A X AADocument14 pagesQ. 1 - Q. 25 Carry One Mark Each.: X A X AAGauravArjariaNo ratings yet
- English Grammar BookDocument8 pagesEnglish Grammar BookGaurav KumarNo ratings yet
- Playcentre Aotearoa's Hazard and Risk Management ProcedureDocument4 pagesPlaycentre Aotearoa's Hazard and Risk Management ProcedureTanmaya Tapaswini TripathyNo ratings yet
- English Grammar - Tenses TableDocument5 pagesEnglish Grammar - Tenses TableGeorgopoulos NikosNo ratings yet
- 2n2222 DatasheetDocument9 pages2n2222 DatasheetHoàng Quốc HuyNo ratings yet
- Notification For The Posts of Gramin Dak Sevaks Cycle - Iii/2020-2021 Odisha CircleDocument132 pagesNotification For The Posts of Gramin Dak Sevaks Cycle - Iii/2020-2021 Odisha CircleTanmaya Tapaswini TripathyNo ratings yet
- Sample Interview Questions With Suggested Ways of Answering: Research The CompanyDocument2 pagesSample Interview Questions With Suggested Ways of Answering: Research The CompanyIngi Abdel Aziz SragNo ratings yet
- Veer Surendra Sai University of Technology, Burla: NoticeDocument1 pageVeer Surendra Sai University of Technology, Burla: NoticeTanmaya Tapaswini TripathyNo ratings yet
- VSSUT PhD Admission List Autumn 2020Document5 pagesVSSUT PhD Admission List Autumn 2020Tanmaya Tapaswini TripathyNo ratings yet
- Q. 1 - Q. 25 Carry One Mark Each.: X A X AADocument14 pagesQ. 1 - Q. 25 Carry One Mark Each.: X A X AAGauravArjariaNo ratings yet
- Q1 - Q5 Carry One Mark Each.: GA - General AptitudeDocument35 pagesQ1 - Q5 Carry One Mark Each.: GA - General AptitudeTanmaya Tapaswini TripathyNo ratings yet
- Notification For The Posts of Gramin Dak Sevaks Cycle - Iii/2020-2021 Odisha CircleDocument132 pagesNotification For The Posts of Gramin Dak Sevaks Cycle - Iii/2020-2021 Odisha CircleTanmaya Tapaswini TripathyNo ratings yet
- MOSFET I-V Characteristics: Key FactorsDocument22 pagesMOSFET I-V Characteristics: Key FactorsAntonio LeonNo ratings yet
- Nodia and Company: Gate Solved Paper Electronics & Communication 2005Document39 pagesNodia and Company: Gate Solved Paper Electronics & Communication 2005Tanmaya Tapaswini TripathyNo ratings yet
- MosfetDocument13 pagesMosfetSristick100% (3)
- Lesson 6 Metal Oxide Semiconductor Field Effect Transistor (MOSFET)Document30 pagesLesson 6 Metal Oxide Semiconductor Field Effect Transistor (MOSFET)Chacko MathewNo ratings yet
- MOSFET Characteristics-Theory and Practice: Debapratim GhoshDocument20 pagesMOSFET Characteristics-Theory and Practice: Debapratim Ghosha durgadeviNo ratings yet
- 02 Differential EquationDocument14 pages02 Differential EquationB AbhinavNo ratings yet
- Herstein Topics in Algebra Solution 2.8Document6 pagesHerstein Topics in Algebra Solution 2.8Arun PatelNo ratings yet
- Arithmetic ProgressionDocument9 pagesArithmetic ProgressionMuhyuddin ArshadNo ratings yet
- Mathematics Diagnostic Test Class 7 Session 2021-2022Document2 pagesMathematics Diagnostic Test Class 7 Session 2021-2022Arshad BilalNo ratings yet
- Jürgen Jost - Mathematical Concepts-Springer International Publishing (2015)Document315 pagesJürgen Jost - Mathematical Concepts-Springer International Publishing (2015)RickNo ratings yet
- Determinant and OtherDocument9 pagesDeterminant and Otherpema karmoNo ratings yet
- 2.1 Basic Equations of Motion of A Rigid BodyDocument17 pages2.1 Basic Equations of Motion of A Rigid Bodyelectroweak262No ratings yet
- 1 - Numbers, Factors & Multiples 1Document35 pages1 - Numbers, Factors & Multiples 1Liane RegnardNo ratings yet
- MATH 404-Presentation 2 - Elimination of Arbitrary Constant & Family of CurvesDocument14 pagesMATH 404-Presentation 2 - Elimination of Arbitrary Constant & Family of CurvesReyven Recon0% (1)
- Calculus Differentiation RulesDocument28 pagesCalculus Differentiation RulesHarold BunaosNo ratings yet
- 4 Fourier SeriesDocument22 pages4 Fourier SeriesFatin FadhlinaNo ratings yet
- 2012 JC2 Preliminary Exam H2 Math Paper 1 SolutionsDocument10 pages2012 JC2 Preliminary Exam H2 Math Paper 1 SolutionsHuixin LimNo ratings yet
- Inmo 1991Document2 pagesInmo 1991Aryan DoshiNo ratings yet
- INVERSE OF ONE-TO-ONE FUNCTIONSDocument1 pageINVERSE OF ONE-TO-ONE FUNCTIONSJeffrey Del Mundo100% (1)
- Test+MaBNVC05 VG MVG Level+Algebra Geometry FunctionsDocument3 pagesTest+MaBNVC05 VG MVG Level+Algebra Geometry FunctionsEpic WinNo ratings yet
- SM3 Wks 2-8Document10 pagesSM3 Wks 2-8Erin GallagherNo ratings yet
- Embedding diamond graphs in Lp and L1 dimension reductionDocument3 pagesEmbedding diamond graphs in Lp and L1 dimension reductiondoraxNo ratings yet
- 8th Unit 56 StudyDocument5 pages8th Unit 56 Studyapi-327041524No ratings yet
- 39f0fcea b849 452c 9a2d 8d6ec841cc2Document26 pages39f0fcea b849 452c 9a2d 8d6ec841cc2ShubhNo ratings yet
- Mathematics 10-Learner's Material-Pages 26 - 42Document2 pagesMathematics 10-Learner's Material-Pages 26 - 42Yanyan AlfanteNo ratings yet
- Getting started with Matlab basicsDocument32 pagesGetting started with Matlab basicsGabriela da CostaNo ratings yet
- Gate Environmental Science Study Material PDFDocument9 pagesGate Environmental Science Study Material PDFmarketing cavNo ratings yet
- Trigonometry in A NutshellDocument5 pagesTrigonometry in A NutshellRakesh S IndiaNo ratings yet
- Trigonometric Integration FormulasDocument14 pagesTrigonometric Integration FormulasMarvin James JaoNo ratings yet
- 1st. Grade-M2 SkillspracticeDocument105 pages1st. Grade-M2 SkillspracticeAngelica Valverde MartinezNo ratings yet
- Heat Transfer Module 4 ObjectivesDocument22 pagesHeat Transfer Module 4 ObjectivesPunit BhatiaNo ratings yet
- Transformations, Shape & Space Revision Notes From GCSE Maths TutorDocument5 pagesTransformations, Shape & Space Revision Notes From GCSE Maths Tutorgcsemathstutor100% (2)
- Topic: Function and Graphs Thinking Map: Circle Map Thinking Process: Defining in ContextDocument7 pagesTopic: Function and Graphs Thinking Map: Circle Map Thinking Process: Defining in Contextjokydin92No ratings yet
- JEE Main 2023 January Session 1 Shift-1 (DT 30-01-2023) MathematicsDocument10 pagesJEE Main 2023 January Session 1 Shift-1 (DT 30-01-2023) MathematicsResonance Eduventures100% (1)
- WBJEE 2014 Mathematics Question Paper With SolutionsDocument20 pagesWBJEE 2014 Mathematics Question Paper With SolutionsLokesh Kumar0% (2)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 5 out of 5 stars5/5 (5)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingFrom EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingRating: 4.5 out of 5 stars4.5/5 (21)
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldFrom EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldRating: 3 out of 5 stars3/5 (79)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 4.5 out of 5 stars4.5/5 (3)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Mental Math Secrets - How To Be a Human CalculatorFrom EverandMental Math Secrets - How To Be a Human CalculatorRating: 5 out of 5 stars5/5 (3)
- Making and Tinkering With STEM: Solving Design Challenges With Young ChildrenFrom EverandMaking and Tinkering With STEM: Solving Design Challenges With Young ChildrenNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Limitless Mind: Learn, Lead, and Live Without BarriersFrom EverandLimitless Mind: Learn, Lead, and Live Without BarriersRating: 4 out of 5 stars4/5 (6)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 4.5 out of 5 stars4.5/5 (20)
- Strategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceFrom EverandStrategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceNo ratings yet
- Calculus Workbook For Dummies with Online PracticeFrom EverandCalculus Workbook For Dummies with Online PracticeRating: 3.5 out of 5 stars3.5/5 (8)