You might also like
- Fraud Detection Using GraphDB - 2014Document11 pagesFraud Detection Using GraphDB - 2014Ryan AllenNo ratings yet
- Survey Paper On Credit Card Fraud DetectionDocument6 pagesSurvey Paper On Credit Card Fraud DetectionMike RomeoNo ratings yet
- Managing Risk and Threat in Financial Services With Link Analysis 2Document17 pagesManaging Risk and Threat in Financial Services With Link Analysis 2praveenparambathNo ratings yet
- Real Time Credit Card Fraud DetectionDocument5 pagesReal Time Credit Card Fraud DetectionInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Catch fraud faster with network visualizationDocument12 pagesCatch fraud faster with network visualizationlvnvenkatNo ratings yet
- Enterrprise Fraud ManagementDocument18 pagesEnterrprise Fraud ManagementrkappearNo ratings yet
- Bolton and HandDocument16 pagesBolton and HandDianna Gene Pagarigan AquinoNo ratings yet
- AI in fraud detection and prevention researchDocument10 pagesAI in fraud detection and prevention researchSusmita Dhital100% (1)
- Anti fraud for Cheques and use of AI: Next gen realtime anti fraud 4 cheque processingFrom EverandAnti fraud for Cheques and use of AI: Next gen realtime anti fraud 4 cheque processingNo ratings yet
- Statistical Fraud Detection - A ReviewDocument21 pagesStatistical Fraud Detection - A ReviewGiuseppeLegrottaglieNo ratings yet
- Process Mining Techniques For Detecting Fraud in Banks: A StudyDocument18 pagesProcess Mining Techniques For Detecting Fraud in Banks: A StudyCharie TabangilNo ratings yet
- Deep Learning Methods For Credit Card Fraud DetectDocument8 pagesDeep Learning Methods For Credit Card Fraud Detectsatyabrata mohapatraNo ratings yet
- Managing Fraud With Link Analysis and Timeline VisualizationDocument14 pagesManaging Fraud With Link Analysis and Timeline VisualizationBadrane HambliNo ratings yet
- maTgvpCT0QDlI - CxtrE68D Nec PDFDocument14 pagesmaTgvpCT0QDlI - CxtrE68D Nec PDFWanted Guy100% (1)
- Unsupervised Profiling Methods ForDocument16 pagesUnsupervised Profiling Methods ForDr.Shrishail MathNo ratings yet
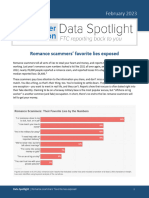
- Romance Spotlight 2023Document3 pagesRomance Spotlight 2023adsamuel061No ratings yet
- THE BLACK BOX SOCIETY-pages-28-67Document40 pagesTHE BLACK BOX SOCIETY-pages-28-67Luis Henrique GonçalvesNo ratings yet
- Fraud Analytics: Strategies and Methods for Detection and PreventionFrom EverandFraud Analytics: Strategies and Methods for Detection and PreventionRating: 5 out of 5 stars5/5 (2)
- Sample 1Document5 pagesSample 1Ivy May Geanga SarabiaNo ratings yet
- Privileged Attack Vectors: Building Effective Cyber-Defense Strategies to Protect OrganizationsFrom EverandPrivileged Attack Vectors: Building Effective Cyber-Defense Strategies to Protect OrganizationsNo ratings yet
- d2000000-a5ec-4992-9ce3-957b8727d83bDocument20 pagesd2000000-a5ec-4992-9ce3-957b8727d83bJaimeNo ratings yet
- Doi: 10.5281/zenodo.7922883: ISSN: 1004-9037Document18 pagesDoi: 10.5281/zenodo.7922883: ISSN: 1004-9037Chaitanya KapilaNo ratings yet
- Cybersafe For Humans: A Simple Guide to Keep You and Your Family Safe OnlineFrom EverandCybersafe For Humans: A Simple Guide to Keep You and Your Family Safe OnlineNo ratings yet
- 122208Document17 pages122208lieselenaNo ratings yet
- How to Prevent Identity Theft: How Anyone Can Protect Themselves from Being a Victim of Identity TheftFrom EverandHow to Prevent Identity Theft: How Anyone Can Protect Themselves from Being a Victim of Identity TheftNo ratings yet
- Analysis On Credit Card Fraud Detection MethodsDocument7 pagesAnalysis On Credit Card Fraud Detection MethodsseventhsensegroupNo ratings yet
- Paper-7 - Supervised Machine Learning Model For Credit Card Fraud DetectionDocument7 pagesPaper-7 - Supervised Machine Learning Model For Credit Card Fraud DetectionRachel WheelerNo ratings yet
- Unmasking Online Scams and Pyramid Schemes: Essential Guide to Protecting Yourself from Digital FraudsFrom EverandUnmasking Online Scams and Pyramid Schemes: Essential Guide to Protecting Yourself from Digital FraudsNo ratings yet
- Review of Related LiteratureDocument3 pagesReview of Related LiteratureDylan Steezy0% (1)
- AGI IndiaDocument19 pagesAGI IndiaAnkush DasNo ratings yet
- Chapter Fraud DetectionDocument14 pagesChapter Fraud DetectionAmare LakewNo ratings yet
- The Top 5 Use Cases of Graph Databases: Unlocking New Possibilities With Connected DataDocument13 pagesThe Top 5 Use Cases of Graph Databases: Unlocking New Possibilities With Connected DataAbhijitNo ratings yet
- Phishing Pharming and Identity TheftDocument11 pagesPhishing Pharming and Identity TheftSalah BarakjiNo ratings yet
- Expert Systems with Applications 39 (2012) 12650–12657Document8 pagesExpert Systems with Applications 39 (2012) 12650–12657mahmutNo ratings yet
- Insurance Fraud DetectionDocument10 pagesInsurance Fraud DetectionNataraju GaddamaduguNo ratings yet
- Industry of Anonymity: Inside the Business of CybercrimeFrom EverandIndustry of Anonymity: Inside the Business of CybercrimeRating: 2 out of 5 stars2/5 (3)
- MPML10 2022 FRDocument24 pagesMPML10 2022 FRMaliha MirzaNo ratings yet
- A Comparative Analysis of Credit Card Fraud Detection Using Machine Learning TechniquesDocument2 pagesA Comparative Analysis of Credit Card Fraud Detection Using Machine Learning TechniquesKhairunnisa SafiNo ratings yet
- Srinivasulu JournalDocument5 pagesSrinivasulu JournalLalitha PonnamNo ratings yet
- Credit Card Fraud Detection ProjectDocument8 pagesCredit Card Fraud Detection ProjectIJRASETPublicationsNo ratings yet
- Spam Nation: The Inside Story of Organized Cybercrime—from Global Epidemic to Your Front DoorFrom EverandSpam Nation: The Inside Story of Organized Cybercrime—from Global Epidemic to Your Front DoorRating: 4 out of 5 stars4/5 (8)
- how-banks-can-get-ahead-on-fraud-risk-management-final-8_27_23Document5 pageshow-banks-can-get-ahead-on-fraud-risk-management-final-8_27_23Girish GandhiNo ratings yet
- Don't Be Scammed by Identity Fraud: I Was Scammed BooksFrom EverandDon't Be Scammed by Identity Fraud: I Was Scammed BooksRating: 5 out of 5 stars5/5 (1)
- Credit Card Fraud Detection 1Document15 pagesCredit Card Fraud Detection 1Rishit MangalNo ratings yet
- B-Intelligence Report 11 2012.en-UsDocument14 pagesB-Intelligence Report 11 2012.en-UsAderlyn OconNo ratings yet
- Financial Cyber CrimeDocument10 pagesFinancial Cyber Crimebehappy_aklprasadNo ratings yet
- Survey of Credit Card Fraud Detection Techniques: Data and Technique PerspectivesDocument26 pagesSurvey of Credit Card Fraud Detection Techniques: Data and Technique PerspectivesPrashanth MohanNo ratings yet
- Financial FraudDocument8 pagesFinancial Fraudsai singh bobbyNo ratings yet
- Divyanshu Assignment 2Document7 pagesDivyanshu Assignment 2Jay SoniNo ratings yet
- Credit Card DetectionDocument9 pagesCredit Card DetectionAhmad WarrichNo ratings yet
- An analysis of identity theft: Motives, related frauds, techniques and preventionDocument7 pagesAn analysis of identity theft: Motives, related frauds, techniques and preventionAli RazaNo ratings yet
- Title Detect and Prevent Identity TheftDocument14 pagesTitle Detect and Prevent Identity TheftAymane2006No ratings yet
- 01 - Minastireanu, MesnitaDocument12 pages01 - Minastireanu, Mesnitaravi prakashNo ratings yet
- Neo4j - WP Fraud Detection With Graph DatabasesDocument12 pagesNeo4j - WP Fraud Detection With Graph Databaseschris jonasNo ratings yet
- FBP June16 ThreeDocument4 pagesFBP June16 Threechris jonasNo ratings yet
- Nursing Leadership in Guam.6Document7 pagesNursing Leadership in Guam.6chris jonasNo ratings yet
- 2018-01-19 CEG To DOJ and DEA (Hezbollah Investigation)Document4 pages2018-01-19 CEG To DOJ and DEA (Hezbollah Investigation)The DiggerNo ratings yet
- Native Americans and American History: Francis Flavin, Ph.D. University of Texas at DallasDocument11 pagesNative Americans and American History: Francis Flavin, Ph.D. University of Texas at DallasIchraf KhechineNo ratings yet
- Documentation For The Loughranmcdonald - MasterdictionaryDocument4 pagesDocumentation For The Loughranmcdonald - Masterdictionarychris jonasNo ratings yet
- IBM I2 Analyst's Notebook: What It Can Do For Your BusinessDocument4 pagesIBM I2 Analyst's Notebook: What It Can Do For Your Businesschris jonasNo ratings yet
- There's A Fight Brewing Between The NYPD and Silicon Valley's PalantirDocument5 pagesThere's A Fight Brewing Between The NYPD and Silicon Valley's Palantirchris jonasNo ratings yet
- Make Sense of Your Big Data with VisalloDocument2 pagesMake Sense of Your Big Data with Visallochris jonasNo ratings yet
- Make Sense of Your Big Data: Adapts To Your Problem SetDocument2 pagesMake Sense of Your Big Data: Adapts To Your Problem Setchris jonasNo ratings yet
- Technology Designed For Investigation Technology Designed For InvestigationDocument4 pagesTechnology Designed For Investigation Technology Designed For Investigationchris jonasNo ratings yet
- Visall - The AlternativeDocument3 pagesVisall - The Alternativechris jonasNo ratings yet
- Sovereign Wealth FundsDocument1 pageSovereign Wealth Fundschris jonasNo ratings yet
- Lexicon-Based Sentiment Analysis in The Social Web-J Basic Appl Sci Res 4 (6) 238-248 2014 ISSN 2090-4304 PDFDocument12 pagesLexicon-Based Sentiment Analysis in The Social Web-J Basic Appl Sci Res 4 (6) 238-248 2014 ISSN 2090-4304 PDFchris jonasNo ratings yet
- California Evaluation Procedures For New Aftermarket Catalytic ConvertersDocument27 pagesCalifornia Evaluation Procedures For New Aftermarket Catalytic Convertersferio252No ratings yet
- Operation Manuals HCWA10NEGQ - Wired ControllerDocument2 pagesOperation Manuals HCWA10NEGQ - Wired Controllerchamara wijesuriyaNo ratings yet
- Contradictions That Drive Toyota's SuccessDocument7 pagesContradictions That Drive Toyota's SuccesskidurexNo ratings yet
- An Improved TS Algorithm For Loss-Minimum Reconfiguration in Large-Scale Distribution SystemsDocument10 pagesAn Improved TS Algorithm For Loss-Minimum Reconfiguration in Large-Scale Distribution Systemsapi-3697505No ratings yet
- G.princy Xii - CommerceDocument21 pagesG.princy Xii - CommerceEvanglin .gNo ratings yet
- Table 141: India'S Overall Balance of Payments - RupeesDocument2 pagesTable 141: India'S Overall Balance of Payments - Rupeesmahbobullah rahmaniNo ratings yet
- Lentz Criminal ComplaintDocument16 pagesLentz Criminal ComplaintKristen Faith SchneiderNo ratings yet
- Task 7 Family Disaster Risk Reduction and Management PlanDocument7 pagesTask 7 Family Disaster Risk Reduction and Management PlanHaise SasakiNo ratings yet
- Land Sale Dispute Interest Rate CaseDocument3 pagesLand Sale Dispute Interest Rate CaseAnne MiguelNo ratings yet
- 11 Core CompetenciesDocument11 pages11 Core CompetenciesrlinaoNo ratings yet
- Educ 13C Questions For MidtermDocument9 pagesEduc 13C Questions For MidtermSannie MonoyNo ratings yet
- RRB GR1Document2 pagesRRB GR1Eniyav DragneelNo ratings yet
- GPU, A Gnutella Processing UnitDocument27 pagesGPU, A Gnutella Processing UnitMengotti Tiziano FlavioNo ratings yet
- HQ 170aDocument82 pagesHQ 170aTony WellsNo ratings yet
- Nurses' Documentation of Falls Prevention in A Patient Centred Care Plan in A Medical WardDocument6 pagesNurses' Documentation of Falls Prevention in A Patient Centred Care Plan in A Medical WardJAY LORRAINE PALACATNo ratings yet
- Piano Sonata No. 17 Tempest 1. Largo - AllegroDocument10 pagesPiano Sonata No. 17 Tempest 1. Largo - AllegroOtrebor ImlesNo ratings yet
- FEA Finite Element Analysis Tutorial ProblemsDocument16 pagesFEA Finite Element Analysis Tutorial ProblemsVinceTanNo ratings yet
- Etextbook 978 0078025884 Accounting Information Systems 4th EditionDocument61 pagesEtextbook 978 0078025884 Accounting Information Systems 4th Editionmark.dame383100% (48)
- Toaz - Info Module in Ergonomics and Planning Facilities For The Hospitality Industry PRDocument33 pagesToaz - Info Module in Ergonomics and Planning Facilities For The Hospitality Industry PRma celine villoNo ratings yet
- Honeywell 393690 Inlet Outlet Flange Kits 69-0256Document2 pagesHoneywell 393690 Inlet Outlet Flange Kits 69-0256Alfredo Castro FernándezNo ratings yet
- Jasmine Nagata Smart GoalsDocument5 pagesJasmine Nagata Smart Goalsapi-319625868No ratings yet
- GitHub TrainingDocument21 pagesGitHub Trainingcyberfox786No ratings yet
- Company Law PPT on Types of CompaniesDocument8 pagesCompany Law PPT on Types of CompaniesAbid CoolNo ratings yet
- Court Invalidates Mortgage Due to Bank's Lack of DiligenceDocument10 pagesCourt Invalidates Mortgage Due to Bank's Lack of DiligenceTokie TokiNo ratings yet
- 5 Short MustWatch Motivational Videos For TeachersrccymDocument4 pages5 Short MustWatch Motivational Videos For Teachersrccymfoxpeak8No ratings yet
- Assignment 2Document21 pagesAssignment 2api-445531772No ratings yet
- C-TECC Principles Guide TECC EducationDocument4 pagesC-TECC Principles Guide TECC EducationDavid Sepulveda MirandaNo ratings yet
- COVID-19 Vaccination Appointment Details: Center Preferred Time SlotDocument1 pageCOVID-19 Vaccination Appointment Details: Center Preferred Time SlotRmillionsque FinserveNo ratings yet
- Air ConditionDocument4 pagesAir ConditionTaller Energy EnergyNo ratings yet
- EY - NASSCOM - M&A Trends and Outlook - Technology Services VF - 0Document35 pagesEY - NASSCOM - M&A Trends and Outlook - Technology Services VF - 0Tejas JosephNo ratings yet