You might also like
- Non-Spherical Errors AnalysisDocument14 pagesNon-Spherical Errors AnalysisPeterson SihotangNo ratings yet
- The Linear Regression ModelDocument24 pagesThe Linear Regression ModelYellow CarterNo ratings yet
- Lecture 15: Diagnostics and Inference For Multiple Linear Regression 1 ReviewDocument7 pagesLecture 15: Diagnostics and Inference For Multiple Linear Regression 1 ReviewSNo ratings yet
- Best Linear PredictorDocument15 pagesBest Linear PredictorHoracioCastellanosMuñoaNo ratings yet
- Matrix OLS NYU NotesDocument14 pagesMatrix OLS NYU NotesAnonymous 2g4jKo5a7vNo ratings yet
- 3.4 Geometry Linear SystemsDocument4 pages3.4 Geometry Linear SystemsChloeNo ratings yet
- Ecf480 FPD 13 2019 2Document8 pagesEcf480 FPD 13 2019 2richard kapimpaNo ratings yet
- 1 Regression Analysis and Least Squares EstimatorsDocument8 pages1 Regression Analysis and Least Squares EstimatorsJenningsJingjingXuNo ratings yet
- Notes On Tensors: 1 Covariant and Contravariant VectorsDocument4 pagesNotes On Tensors: 1 Covariant and Contravariant VectorsCarlos BattistiNo ratings yet
- General Tensors I Transformation of CoordinatesDocument14 pagesGeneral Tensors I Transformation of CoordinatesABCSDFGNo ratings yet
- Laplace Type Invariants For Parabolic EquationsDocument9 pagesLaplace Type Invariants For Parabolic EquationsPanagiot LoukopoulosNo ratings yet
- Regression Analysis: Properties of Least Squares EstimatorsDocument7 pagesRegression Analysis: Properties of Least Squares EstimatorsFreddie YuanNo ratings yet
- Chapter 6: RegressionDocument7 pagesChapter 6: RegressionHienpt PhamNo ratings yet
- Lecture 24: Weighted and Generalized Least Squares 1 Weighted Least SquaresDocument8 pagesLecture 24: Weighted and Generalized Least Squares 1 Weighted Least SquaresSNo ratings yet
- Analysis of Two Partial-Least-Squares Algorithms for Multivariate CalibrationDocument17 pagesAnalysis of Two Partial-Least-Squares Algorithms for Multivariate CalibrationAna RebeloNo ratings yet
- Final 2015 PDFDocument13 pagesFinal 2015 PDFAchilles 777No ratings yet
- CSE Example Capacitor Numerical PDEDocument13 pagesCSE Example Capacitor Numerical PDESarthak SinghNo ratings yet
- Solution To Chapter 1 Analytical ExercisesDocument5 pagesSolution To Chapter 1 Analytical ExercisesCamila SanchezNo ratings yet
- Econometrics - Fumio Hayashi (Solutions Analytical)Document44 pagesEconometrics - Fumio Hayashi (Solutions Analytical)Papai SmurfNo ratings yet
- Econometrics LS Estimator PropertiesDocument68 pagesEconometrics LS Estimator PropertiesDryasser AtieaNo ratings yet
- 1 The Pendulum EquationDocument7 pages1 The Pendulum EquationGanesh SatheNo ratings yet
- The Method of Frobenius for Regular Singular PointsDocument33 pagesThe Method of Frobenius for Regular Singular PointsakshayNo ratings yet
- Power Series and Differential Equations: The Method of FrobeniusDocument25 pagesPower Series and Differential Equations: The Method of Frobeniusomotoriogun samuelNo ratings yet
- Power Series and Differential Equations: The Method of FrobeniusDocument19 pagesPower Series and Differential Equations: The Method of FrobeniusHassan AliNo ratings yet
- Wave Equation 2Document32 pagesWave Equation 2Yudistira Adi NNo ratings yet
- Question 1Document4 pagesQuestion 1lifetips6786No ratings yet
- Vvedensky D.-Group Theory, Problems and Solutions (2005)Document94 pagesVvedensky D.-Group Theory, Problems and Solutions (2005)egmont7No ratings yet
- StatisticDocument5 pagesStatisticrahmanabir97No ratings yet
- LXIX Olimpiada Matematyczna: Rozwiązania Zadań Konkursowych Zawodów Stopnia TrzeciegoDocument7 pagesLXIX Olimpiada Matematyczna: Rozwiązania Zadań Konkursowych Zawodów Stopnia TrzeciegoIlir HoxhaNo ratings yet
- Hahn-Banach theorems explainedDocument7 pagesHahn-Banach theorems explainedEDU CIPANANo ratings yet
- Calc VarDocument8 pagesCalc VarAreej FatimaNo ratings yet
- UnivariateRegression 2Document72 pagesUnivariateRegression 2Alada manaNo ratings yet
- Gauss-Markov TheoremDocument5 pagesGauss-Markov Theoremalanpicard2303No ratings yet
- LinearDocument31 pagesLinearHiGrill25No ratings yet
- a, a, …, a, α, …, α a α a α a …+α a a, a, …, a a α a α a …+α a α …=αDocument7 pagesa, a, …, a, α, …, α a α a α a …+α a a, a, …, a a α a α a …+α a α …=αKimondo KingNo ratings yet
- Lyapunov functions reveal global stabilityDocument8 pagesLyapunov functions reveal global stabilitykamalulwafiNo ratings yet
- Econometrics 2012 ExamDocument9 pagesEconometrics 2012 ExamLuca SomigliNo ratings yet
- 1.2. An Overview of Key IdeasDocument5 pages1.2. An Overview of Key IdeasTung TienNo ratings yet
- Lecture FOURDocument4 pagesLecture FOURBenjamin Amwoma OmbworiNo ratings yet
- VCV Week3Document4 pagesVCV Week3Diman Si KancilNo ratings yet
- Machine Learning Report Analyzes Bayesian ClassificationDocument3 pagesMachine Learning Report Analyzes Bayesian ClassificationCarl WoodsNo ratings yet
- Optimization Techniques 1. Least SquaresDocument17 pagesOptimization Techniques 1. Least SquaresKhalil UllahNo ratings yet
- UnivariateRegression 3Document81 pagesUnivariateRegression 3Alada manaNo ratings yet
- EC1 Final 2018 03 27 SolDocument3 pagesEC1 Final 2018 03 27 SolLucas BakkerNo ratings yet
- GMM Estimation PDFDocument35 pagesGMM Estimation PDFdamian camargoNo ratings yet
- Gibbs Annealing for Multiway Bayesian Linear RegressionsDocument8 pagesGibbs Annealing for Multiway Bayesian Linear RegressionsJohn ValjohnNo ratings yet
- L3 MLRMDocument10 pagesL3 MLRM洪梓沛No ratings yet
- GauntletDocument6 pagesGauntletsuvo baidyaNo ratings yet
- Lecture 14: Multiple Linear Regression 1 Review of Simple Linear Regression in Matrix FormDocument7 pagesLecture 14: Multiple Linear Regression 1 Review of Simple Linear Regression in Matrix FormSNo ratings yet
- Chapter 1Document11 pagesChapter 1cicin8190No ratings yet
- Advanced algorithms explainedDocument188 pagesAdvanced algorithms explainedyohanes sinagaNo ratings yet
- IpdeDocument6 pagesIpdeBenci MonoriNo ratings yet
- Exercises Session1 PDFDocument4 pagesExercises Session1 PDFAnonymous a01mXIKLxtNo ratings yet
- EC2303 Additional Practice QuestionsDocument7 pagesEC2303 Additional Practice QuestionsSiya LimNo ratings yet
- Ch. 2 - GLS and HeteroskedasticityDocument23 pagesCh. 2 - GLS and HeteroskedasticityVolkan VeliNo ratings yet
- Solucao T6Document2 pagesSolucao T6Marcello HenriqueNo ratings yet
- Google SearchDocument2 pagesGoogle SearchFucKerWengieNo ratings yet
- Facebook Video Downloader - Download Facebook Videos OnlineDocument2 pagesFacebook Video Downloader - Download Facebook Videos OnlineFucKerWengieNo ratings yet
- See Results About: Limited Liability CompanDocument2 pagesSee Results About: Limited Liability CompanFucKerWengieNo ratings yet
- 908 - Google SearchDocument2 pages908 - Google SearchFucKerWengieNo ratings yet
- Triple G Boxing HighlightsDocument2 pagesTriple G Boxing HighlightsFucKerWengieNo ratings yet
- Reg - Google SearchDocument2 pagesReg - Google SearchFucKerWengieNo ratings yet
- 3 Reasons Why You Are Seeing 2:22 - The Meaning of 222 ... : People Also AskDocument3 pages3 Reasons Why You Are Seeing 2:22 - The Meaning of 222 ... : People Also AskFucKerWengieNo ratings yet
- We Vs Virus Hackathon Canada - Google SearchDocument2 pagesWe Vs Virus Hackathon Canada - Google SearchFucKerWengieNo ratings yet
- Dwe - Google SearchDocument2 pagesDwe - Google SearchFucKerWengieNo ratings yet
- DDD - Google SearchDocument3 pagesDDD - Google SearchFucKerWengieNo ratings yet
- VBA Programming Workshop - Tic Tac Toe: Mr. Chew Chun Yong, Ms. Choo Ley YaDocument8 pagesVBA Programming Workshop - Tic Tac Toe: Mr. Chew Chun Yong, Ms. Choo Ley YaFucKerWengieNo ratings yet
- Cyclone Excel Calculation - Google SearchDocument2 pagesCyclone Excel Calculation - Google SearchFucKerWengieNo ratings yet
- CCCC - Google SearchDocument2 pagesCCCC - Google SearchFucKerWengieNo ratings yet
- Google SearchDocument2 pagesGoogle SearchFucKerWengieNo ratings yet
- KLSE StockDocument14 pagesKLSE StockFucKerWengieNo ratings yet
- Rownumber Area Age Sex Payment Status Nodays StatusDocument22 pagesRownumber Area Age Sex Payment Status Nodays StatusFucKerWengieNo ratings yet
- Deep Well Pump 4SAm - Google SearchDocument2 pagesDeep Well Pump 4SAm - Google SearchFucKerWengieNo ratings yet
- Postalcode Hashcode Age Gender Payment Method Rownumber LasttransactionDocument44 pagesPostalcode Hashcode Age Gender Payment Method Rownumber LasttransactionFucKerWengieNo ratings yet
- Topic6 PDFDocument32 pagesTopic6 PDFFucKerWengieNo ratings yet
- Rownumber Area Age Sex Payment Nodays StatusDocument22 pagesRownumber Area Age Sex Payment Nodays StatusFucKerWengieNo ratings yet
- Age, Income & Buy Data for 10 PeopleDocument2 pagesAge, Income & Buy Data for 10 PeopleFucKerWengieNo ratings yet
- Predictive Model - Linear and Logistic Models PDFDocument108 pagesPredictive Model - Linear and Logistic Models PDFFucKerWengie100% (1)
- MEME19403 Data Analytics and Visualization: Module Three: Visualization With DashboardDocument51 pagesMEME19403 Data Analytics and Visualization: Module Three: Visualization With DashboardFucKerWengieNo ratings yet
- Descriptive and Predictive AnalyticsDocument45 pagesDescriptive and Predictive AnalyticsFucKerWengie0% (1)
- UECM 1534 Data Loading and Storage TechniquesDocument22 pagesUECM 1534 Data Loading and Storage TechniquesFucKerWengieNo ratings yet
- Introduction and ETLDocument125 pagesIntroduction and ETLFucKerWengieNo ratings yet
- Predictive Model - Linear and Logistic Models PDFDocument108 pagesPredictive Model - Linear and Logistic Models PDFFucKerWengie100% (1)
- 04 Introduction To Python-1Document29 pages04 Introduction To Python-1FucKerWengieNo ratings yet
- User Guide: Co-Curricular Fee Payment SystemDocument11 pagesUser Guide: Co-Curricular Fee Payment SystemFucKerWengieNo ratings yet
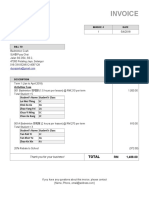
- Invoice: SJK© Puay ChaiDocument5 pagesInvoice: SJK© Puay ChaiFucKerWengieNo ratings yet
- Chapter 3 DEMAND ESTIMATION 3Document38 pagesChapter 3 DEMAND ESTIMATION 3The TwitterNo ratings yet
- Simple Linear RegressionDocument24 pagesSimple Linear Regressionইশতিয়াক হোসেন সিদ্দিকীNo ratings yet
- Statistics For Business and Economics: Estimation: Single PopulationDocument46 pagesStatistics For Business and Economics: Estimation: Single Populationfour threepioNo ratings yet
- CH05 - Wooldridge - 7e PPT - 2ppDocument9 pagesCH05 - Wooldridge - 7e PPT - 2ppMahlatse Mabeba100% (1)
- 130646Document26 pages130646Agung SetiawanNo ratings yet
- Testing EndogeneityDocument3 pagesTesting Endogeneitysharkbait_fbNo ratings yet
- Tata MoDocument24 pagesTata MoSaurabh RanjanNo ratings yet
- Regression AnalysisDocument44 pagesRegression AnalysisPritisha SrivastavaNo ratings yet
- Full Download Using Econometrics A Practical Guide 7th Edition Studenmund Solutions ManualDocument36 pagesFull Download Using Econometrics A Practical Guide 7th Edition Studenmund Solutions Manualnoahkim2jgp100% (28)
- 6th Lecture Note 108335647 230518 203102Document35 pages6th Lecture Note 108335647 230518 203102Girie YumNo ratings yet
- Correlation & RegressionDocument24 pagesCorrelation & RegressionAnsh TalwarNo ratings yet
- Dummy Variables and Interaction TermsDocument7 pagesDummy Variables and Interaction TermsAnnas Aman KtkNo ratings yet
- Chapter 3. Panel Threshold Regression ModelsDocument86 pagesChapter 3. Panel Threshold Regression ModelsdorinNo ratings yet
- Complex Systems in Finance and EconometricsDocument19 pagesComplex Systems in Finance and EconometricsJuliana TessariNo ratings yet
- Logistic RegressionDocument37 pagesLogistic RegressionDhruv BansalNo ratings yet
- CPI, Interest Rates, Exchange Rates and Unemployment Impact on Housing StartsDocument10 pagesCPI, Interest Rates, Exchange Rates and Unemployment Impact on Housing StartsTito MazolaNo ratings yet
- Regression Analysis For Cost ModellingDocument25 pagesRegression Analysis For Cost ModellingChivantha SamarajiwaNo ratings yet
- Levine Bsfc7ge ch12Document84 pagesLevine Bsfc7ge ch12Chih Chou ChiuNo ratings yet
- Switching Models: Introductory Econometrics For Finance © Chris Brooks 2002 1Document29 pagesSwitching Models: Introductory Econometrics For Finance © Chris Brooks 2002 1Chander Bhanu SinghNo ratings yet
- 168 Sample ChapterDocument14 pages168 Sample ChapterMishi Bhatnagar100% (1)
- US Passenger Vehicle Sales 2004-2017Document5 pagesUS Passenger Vehicle Sales 2004-2017Samdeesh SinghNo ratings yet
- Data AnalysisDocument28 pagesData AnalysisDotRev Ibs100% (1)
- Multiple Regression EstimationDocument18 pagesMultiple Regression EstimationSakshi VashishthaNo ratings yet
- Regression Analysis Under Linear Restrictions and Preliminary Test EstimationDocument24 pagesRegression Analysis Under Linear Restrictions and Preliminary Test EstimationAbdullah KhatibNo ratings yet
- Slides Lecture 6.4 PDFDocument3 pagesSlides Lecture 6.4 PDFJavier DoradoNo ratings yet
- REGRESSION CHECKLIST GUIDEDocument3 pagesREGRESSION CHECKLIST GUIDEYixin XiaNo ratings yet
- AERM - Applied Econometrics For Rural ManagementDocument3 pagesAERM - Applied Econometrics For Rural ManagementNavi FisNo ratings yet
- STADocument20 pagesSTAshajib_sustNo ratings yet
- Multiple Regression Analysis Using SPSS StatisticsDocument5 pagesMultiple Regression Analysis Using SPSS StatisticssuwashiniNo ratings yet
- Coursera Instrumental Analysis: Linear Regression - Example 1Document10 pagesCoursera Instrumental Analysis: Linear Regression - Example 1Oscar RojasNo ratings yet