You might also like
- Método de La Falsa Posición, Ejemplo 3Document6 pagesMétodo de La Falsa Posición, Ejemplo 3Sergio SanchezNo ratings yet
- KTL - MocktestDocument3 pagesKTL - MocktestFTU.CS2 Bùi Võ Song ThươngNo ratings yet
- Linear Regression Using TensorFlow PDFDocument5 pagesLinear Regression Using TensorFlow PDFkknkNo ratings yet
- Digital Image Processing Lab Manual: Experiment-1Document13 pagesDigital Image Processing Lab Manual: Experiment-1Anonymous G5D0xzq2No ratings yet
- Exercice5 - ColaboratoryDocument3 pagesExercice5 - ColaboratoryYosr ZaiedNo ratings yet
- Name: Muhammad Sarfraz Seat: EP1850086 Section: A Course Code: 514 Course Name: Data Warehousing and Data MiningDocument39 pagesName: Muhammad Sarfraz Seat: EP1850086 Section: A Course Code: 514 Course Name: Data Warehousing and Data MiningMuhammad SarfrazNo ratings yet
- Assignment 3 Problems - Chapter 13 analysis and solutionsDocument12 pagesAssignment 3 Problems - Chapter 13 analysis and solutionsAhmed AfridiNo ratings yet
- Chapter 7 Costing Systems SummaryDocument24 pagesChapter 7 Costing Systems SummaryCharlene BalderaNo ratings yet
- Parte 1. Problemas Sobre Tema 2.: Unrecognized Function or Variable 'B'Document10 pagesParte 1. Problemas Sobre Tema 2.: Unrecognized Function or Variable 'B'EMILIO RODRIGUEZ CALDERONNo ratings yet
- Capacity Planning InsightsDocument13 pagesCapacity Planning InsightsSarsal6067No ratings yet
- Excell Re UltDocument1,068 pagesExcell Re UltHundeejireenyaNo ratings yet
- Staticbuild LogDocument6 pagesStaticbuild LogJAlexanderLampreaNo ratings yet
- Name: Shreyash Kharat Homework: Hw3 (Problem 1)Document7 pagesName: Shreyash Kharat Homework: Hw3 (Problem 1)Mainak SamantaNo ratings yet
- Advanced Accounting Problems and Solutions GuideDocument4 pagesAdvanced Accounting Problems and Solutions GuideChristian GoNo ratings yet
- Math 1010 Project 2 Zero Gravity ProjectDocument4 pagesMath 1010 Project 2 Zero Gravity Projectapi-317113210100% (1)
- Tutorial Pandas Bag-5Document11 pagesTutorial Pandas Bag-5NUR JAYANo ratings yet
- Setup: Chapter 2 - End-To-End Machine Learning ProjectDocument31 pagesSetup: Chapter 2 - End-To-End Machine Learning ProjectAmitNo ratings yet
- Assignment 2 Golden Section OptimizationDocument9 pagesAssignment 2 Golden Section OptimizationAlfredo IllescasNo ratings yet
- Chapter # 15 Solutions - Engineering Economy, 7 TH Editionleland Blank and Anthony TarquinDocument13 pagesChapter # 15 Solutions - Engineering Economy, 7 TH Editionleland Blank and Anthony TarquinMusa'b100% (1)
- P3 1.501 - P4 0.678 - P4 0.74 - P3 1.538: Surveryor: Date:: Locaton: Project: CheckingDocument25 pagesP3 1.501 - P4 0.678 - P4 0.74 - P3 1.538: Surveryor: Date:: Locaton: Project: CheckingVincent Co'rudi NmcNo ratings yet
- Statistics AssignmemntDocument18 pagesStatistics AssignmemntManinder KaurNo ratings yet
- Multiple Choice Questions ChapterDocument18 pagesMultiple Choice Questions Chaptersweetwinkle09No ratings yet
- LogDocument18 pagesLogmhnzal001No ratings yet
- Lab 5 BA Varying DensityDocument1 pageLab 5 BA Varying DensitySHRISTI THAKURNo ratings yet
- Additonal - Chapter 5Document19 pagesAdditonal - Chapter 5Gega XachidENo ratings yet
- Exercise 7.24: Function For ... ... EndDocument3 pagesExercise 7.24: Function For ... ... EndDebi BoleNo ratings yet
- Output: Give Coord (x0 Y0 x1 Y1) : (0 0 5 5) : Experiment - 3 Program For Scan Conversion of A Straight LineDocument7 pagesOutput: Give Coord (x0 Y0 x1 Y1) : (0 0 5 5) : Experiment - 3 Program For Scan Conversion of A Straight LineJackNo ratings yet
- UWI Mona ACCT1003 intro to cost mgmt accounting worksheet solutionsDocument5 pagesUWI Mona ACCT1003 intro to cost mgmt accounting worksheet solutionsJustine Powell100% (1)
- COST EXAM2 (Compiled by Gail)Document17 pagesCOST EXAM2 (Compiled by Gail)Mildred Angela DingalNo ratings yet
- Punto 11 Taller 1 Método de Falsa Posición Angie ArenasDocument7 pagesPunto 11 Taller 1 Método de Falsa Posición Angie ArenasANGIE MARCELA ARENAS NUÑEZNo ratings yet
- Analysis Investment ProjectDocument13 pagesAnalysis Investment ProjectsolomonNo ratings yet
- Bisección numérica para encontrar raíces de una funciónDocument22 pagesBisección numérica para encontrar raíces de una funciónMaría Nelly Gallardo BarretoNo ratings yet
- Nelly - Gallardo - Barreto - Metodo de La BisecciónDocument22 pagesNelly - Gallardo - Barreto - Metodo de La BisecciónMaría Nelly Gallardo BarretoNo ratings yet
- Experiment 10: To Demonstrate The ASK Modulation & DemodulationDocument12 pagesExperiment 10: To Demonstrate The ASK Modulation & Demodulationf180535 SajjadAhmadNo ratings yet
- Faculty of Civil and Environmental Engineering Department of Structure and Material Engineering Lab MaterialDocument19 pagesFaculty of Civil and Environmental Engineering Department of Structure and Material Engineering Lab MaterialIkhwan Z.83% (6)
- Deber MatlabDocument15 pagesDeber MatlabLENIN STALIN VALDEZNo ratings yet
- Ujian Mid SemesterDocument11 pagesUjian Mid SemesterAkhmad Fauzul AlbabNo ratings yet
- Import Data Set: Forward SelectionDocument7 pagesImport Data Set: Forward SelectionThejusNo ratings yet
- Simulation of Inverted Pendulum With Step ResponseDocument8 pagesSimulation of Inverted Pendulum With Step ResponseJohn TysonNo ratings yet
- Project 8 Predictive Analytics - Ipynb - ColaboratoryDocument8 pagesProject 8 Predictive Analytics - Ipynb - ColaboratoryaadityadeolalikarNo ratings yet
- Basit Doğrusal Regresyon KodlarDocument5 pagesBasit Doğrusal Regresyon KodlarRamazan AcarNo ratings yet
- MathDocument3 pagesMathWilliam Ethanvince J. TiongcoNo ratings yet
- LogDocument12 pagesLogGari AapNo ratings yet
- Assignment 1 AnswersDocument7 pagesAssignment 1 AnswersIzwan YusofNo ratings yet
- Chapter 5 Arithmetic and Logic CircuitsDocument13 pagesChapter 5 Arithmetic and Logic Circuitsee206023No ratings yet
- Matlab-Median and ModeDocument12 pagesMatlab-Median and ModeYash Garg100% (1)
- Chapter 13Document29 pagesChapter 13sweetwinkle09No ratings yet
- 02 MulticollinearityDocument8 pages02 MulticollinearityGabriel Gheorghe100% (1)
- Program PNBDocument78 pagesProgram PNBLukaNo ratings yet
- Chap013 SolutionsDocument21 pagesChap013 SolutionsDiane Katz ZiegmanNo ratings yet
- Akar 04Document3 pagesAkar 04imaharNo ratings yet
- Import Excel Data and Perform Operations in MatlabDocument6 pagesImport Excel Data and Perform Operations in MatlabSulman ShahzadNo ratings yet
- Cape, Jessielyn Vea C. PCBET-01-301P AC9/ THURSDAY/ 9:00AM-12:00PMDocument8 pagesCape, Jessielyn Vea C. PCBET-01-301P AC9/ THURSDAY/ 9:00AM-12:00PMhan jisungNo ratings yet
- Studi Kasus: Flow Bottom Flow Middle Flow Top Speed Basis Weight CaliperDocument11 pagesStudi Kasus: Flow Bottom Flow Middle Flow Top Speed Basis Weight CaliperBetrik QatrunnadaNo ratings yet
- MPT BL Bayesian PDFDocument112 pagesMPT BL Bayesian PDFyuzukiebaNo ratings yet
- Bab IvDocument9 pagesBab IvMuh ArbiNo ratings yet
- Ekomet Jawaban CH 2Document8 pagesEkomet Jawaban CH 2valen mirandaNo ratings yet
- ADVANCED ACCOUNTING CHAPTERS 9-10Document4 pagesADVANCED ACCOUNTING CHAPTERS 9-10James CantorneNo ratings yet
- Laboratory Exercises in Astronomy: Solutions and AnswersFrom EverandLaboratory Exercises in Astronomy: Solutions and AnswersNo ratings yet
- Title PageDocument1 pageTitle PageSuper AmazingNo ratings yet
- Dear StudentDocument1 pageDear StudentSuper AmazingNo ratings yet
- RentalDocument1 pageRentalSuper AmazingNo ratings yet
- Business PlanDocument41 pagesBusiness PlanSuper AmazingNo ratings yet
- Thailand: ValuesDocument7 pagesThailand: ValuesSuper AmazingNo ratings yet
- Success Story of Henry Sy Sr.Document2 pagesSuccess Story of Henry Sy Sr.Super Amazing100% (2)
- Health - Related Physical Fitness Refers To The Overall Well Being of An Individual. Read and Understand Each of ThemDocument7 pagesHealth - Related Physical Fitness Refers To The Overall Well Being of An Individual. Read and Understand Each of ThemSuper AmazingNo ratings yet
- Research 101Document1 pageResearch 101Super AmazingNo ratings yet
- Mini-Activity 2-4: BLM Act 2-4Document3 pagesMini-Activity 2-4: BLM Act 2-4Super AmazingNo ratings yet
- Visual Computing Systems and ApplicationsDocument14 pagesVisual Computing Systems and ApplicationsSuper AmazingNo ratings yet
- Research 101Document1 pageResearch 101Super AmazingNo ratings yet
- Krispy Kreme Case StudyDocument5 pagesKrispy Kreme Case StudyDaphne PerezNo ratings yet
- Visual Computing DisciplinesDocument3 pagesVisual Computing DisciplinesSuper AmazingNo ratings yet
- FGNFCDocument6 pagesFGNFCSuper AmazingNo ratings yet
- Visual Computing DisciplinesDocument3 pagesVisual Computing DisciplinesSuper AmazingNo ratings yet
- Computer Graphics and Computer AnimationDocument14 pagesComputer Graphics and Computer AnimationSuper AmazingNo ratings yet
- Krispy Kreme Case StudyDocument5 pagesKrispy Kreme Case StudyDaphne PerezNo ratings yet
- Form 1 CERTIFICATION JESSA BCDocument2 pagesForm 1 CERTIFICATION JESSA BCSuper AmazingNo ratings yet
- Microorganisma and Human HealthDocument11 pagesMicroorganisma and Human HealthSuper AmazingNo ratings yet
- Krispy Kreme Case StudyDocument5 pagesKrispy Kreme Case StudyDaphne PerezNo ratings yet
- Krispy Kreme Case StudyDocument5 pagesKrispy Kreme Case StudyDaphne PerezNo ratings yet
- Kashato Shirts 1Document63 pagesKashato Shirts 1Danica De Vera100% (2)
- Microorganisma and Human HealthDocument11 pagesMicroorganisma and Human HealthSuper AmazingNo ratings yet
- Microorganisma and Human HealthDocument11 pagesMicroorganisma and Human HealthSuper AmazingNo ratings yet
- Reliability & Maintainability Engineering Ebeling Chapter 2 Book Solutions - Failure Distribut PDFDocument12 pagesReliability & Maintainability Engineering Ebeling Chapter 2 Book Solutions - Failure Distribut PDFNaveenMatthewNo ratings yet
- UCCM2233 - Chp5.2 Continuous Rv-Answer WbleDocument54 pagesUCCM2233 - Chp5.2 Continuous Rv-Answer WbleVS ShirleyNo ratings yet
- MIDAS Completed Action Research - BigboyDocument14 pagesMIDAS Completed Action Research - BigboyAvelino Jr II PayotNo ratings yet
- Field Methods in Psychology Module 2: The Descriptive Methods: Observation Instructor: Greg S. Naldo JR., Mapsy CP., RPMDocument8 pagesField Methods in Psychology Module 2: The Descriptive Methods: Observation Instructor: Greg S. Naldo JR., Mapsy CP., RPMEarl AgustinNo ratings yet
- Integration TablesDocument1 pageIntegration Tablespanos2244662864No ratings yet
- MIT6 003S10 Lec05 HandoutDocument6 pagesMIT6 003S10 Lec05 HandoutBharat KumarNo ratings yet
- 4th Sem Detailed Syllabus (B. Sc. in Data Science)Document5 pages4th Sem Detailed Syllabus (B. Sc. in Data Science)kbhowalNo ratings yet
- Syllabus Che348 Spring2016 Ver4 PDFDocument8 pagesSyllabus Che348 Spring2016 Ver4 PDFMayank PrakashNo ratings yet
- Inverse Jeemain - GuruDocument32 pagesInverse Jeemain - GuruNeetu GuptaNo ratings yet
- Pavement Thesis 5 2Document120 pagesPavement Thesis 5 2Marko PopovicNo ratings yet
- Blenker 2014Document20 pagesBlenker 2014Kwadwo Owusu MainooNo ratings yet
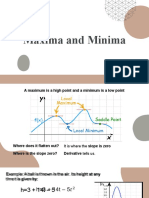
- Finding maximum and minimum points using derivativesDocument13 pagesFinding maximum and minimum points using derivativesMA. ISABELLA BALLESTEROSNo ratings yet
- Bank RpubsDocument24 pagesBank RpubsAnil Kumar NayakNo ratings yet
- Trapezoidal Rule NotesDocument3 pagesTrapezoidal Rule NotesAmbreen KhanNo ratings yet
- Circular Economy at The Company Level An Empirical Study Based On Sustainability ReportsDocument11 pagesCircular Economy at The Company Level An Empirical Study Based On Sustainability ReportsMiren Heras SánchezNo ratings yet
- Qualitative Research ApproachDocument5 pagesQualitative Research Approachamirah dayana100% (1)
- Module 4Document4 pagesModule 4alohanegraNo ratings yet
- Measure of Central Tendency ProjectDocument86 pagesMeasure of Central Tendency ProjectVijay SartapeNo ratings yet
- B Vs C TestDocument7 pagesB Vs C TestSiva Subramaniam M BNo ratings yet
- CPM and PERT-1701Document36 pagesCPM and PERT-1701Refisa JiruNo ratings yet
- 4 - BC 2017-18 5-6.4 FTC and AverageDocument4 pages4 - BC 2017-18 5-6.4 FTC and AverageSamNo ratings yet
- BibliograDocument4 pagesBibliograGrover Milton Mamani CcalleNo ratings yet
- Qualitative Analysis To Improve TechniquesDocument18 pagesQualitative Analysis To Improve TechniquesFrancis FrimpongNo ratings yet
- LinearProgramming Russell TaylorDocument27 pagesLinearProgramming Russell TaylorGaurav100% (1)
- Advanced Engineering Mathematics Prof. P. D. Srivastava Department of Mathematics Indian Institute of Technology, KharagpurDocument17 pagesAdvanced Engineering Mathematics Prof. P. D. Srivastava Department of Mathematics Indian Institute of Technology, KharagpurNiravNo ratings yet
- BSC (P) 18 Sem.I III V PDFDocument9 pagesBSC (P) 18 Sem.I III V PDFHarshit KaluchaNo ratings yet
- 1 Single Variable Calculus Fall 2005 Fall 2006 Fall 2010Document2 pages1 Single Variable Calculus Fall 2005 Fall 2006 Fall 2010Chaitanya ShahNo ratings yet
- Functions Domain and Range GuideDocument24 pagesFunctions Domain and Range Guiderofi modi100% (1)
- Jigsaw Course Academy CatalogDocument1 pageJigsaw Course Academy Catalogsaurs2No ratings yet
- Space Curves - 1: Differential Geometry III, Solutions 4 (Week 4)Document3 pagesSpace Curves - 1: Differential Geometry III, Solutions 4 (Week 4)Gag PafNo ratings yet