You might also like
- Solutions To Sheldon Ross SimulationDocument66 pagesSolutions To Sheldon Ross SimulationSarah Koblick55% (11)
- Exercises in Probability (T. Cacoullos)Document250 pagesExercises in Probability (T. Cacoullos)Miguel AngelNo ratings yet
- Machine Code For Beginners PDFDocument51 pagesMachine Code For Beginners PDFMiguel Angel100% (2)
- Import Import Import Import Import Import Import Import Public Class Extends Implements Public Void ThrowsDocument6 pagesImport Import Import Import Import Import Import Import Public Class Extends Implements Public Void ThrowsSARAVANANNo ratings yet
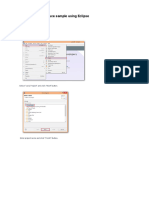
- Execute Java Map Reduce Sample Using EclipseDocument9 pagesExecute Java Map Reduce Sample Using EclipseArjun SNo ratings yet
- Run WordcountDocument3 pagesRun WordcountKhushi PatilNo ratings yet
- WordcountDocument3 pagesWordcount21020279 Trần Diệu AnhNo ratings yet
- Word Count Program To Demonstrate The Use of Map and Reduce TasksDocument5 pagesWord Count Program To Demonstrate The Use of Map and Reduce Tasksriya kNo ratings yet
- Hadoop Configuration and Single Node SetupDocument61 pagesHadoop Configuration and Single Node SetupParthNo ratings yet
- Import Import Import Import Import Import Import Import Public Class Extends ImplementsDocument7 pagesImport Import Import Import Import Import Import Import Public Class Extends ImplementsSARAVANANNo ratings yet
- Step 2 - First MapReduce ProgramDocument25 pagesStep 2 - First MapReduce ProgramSantosh Kumar DesaiNo ratings yet
- ADA Lab ManualDocument34 pagesADA Lab Manualnalluri_08No ratings yet
- Big Data Word Count MapReduce ExampleDocument6 pagesBig Data Word Count MapReduce ExampleJajang NurjamanNo ratings yet
- Apasoft BigData Practices MapReduce JobDocument3 pagesApasoft BigData Practices MapReduce JobChristiam NiñoNo ratings yet
- DBMS Mini Project ReportDocument15 pagesDBMS Mini Project ReportAbhijeetNo ratings yet
- 6 - Simple WordcountDocument2 pages6 - Simple WordcountXavier TxANo ratings yet
- BDT Lab ManualDocument48 pagesBDT Lab ManualVishnu Vardhan HNo ratings yet
- Experiment: Word Count in HadoopDocument12 pagesExperiment: Word Count in HadoopSAMINA ATTARINo ratings yet
- BDF Lab1Document6 pagesBDF Lab1shaliniiiiNo ratings yet
- 1-Implementing A Java ProgramDocument13 pages1-Implementing A Java Programpratigya gNo ratings yet
- Lab ManualDocument86 pagesLab Manualpthuynh709No ratings yet
- BDALab Assn4Document9 pagesBDALab Assn4Deepti AgrawalNo ratings yet
- NPR College of Engineering and Technology Department of Computer Science & Engg.Document38 pagesNPR College of Engineering and Technology Department of Computer Science & Engg.lathikacharanNo ratings yet
- BDA3Document7 pagesBDA3nikithakatta0No ratings yet
- To Count Using Map and Reduce Program: Wordcount - JavaDocument2 pagesTo Count Using Map and Reduce Program: Wordcount - JavaRamya DeviNo ratings yet
- BDALab Assn4Document9 pagesBDALab Assn4Deepti AgrawalNo ratings yet
- Word Count Program With MapReduce and JavaDocument7 pagesWord Count Program With MapReduce and JavachetnaNo ratings yet
- Big DataDocument67 pagesBig DataB21A4530 AshrithaNo ratings yet
- Java MySQL BasicsDocument7 pagesJava MySQL BasicsJesseVillanuevaNo ratings yet
- JLibrary Managment System DocumentationDocument68 pagesJLibrary Managment System Documentationaregawi weleabezgiNo ratings yet
- Develop Simple MapReduce WordCountDocument22 pagesDevelop Simple MapReduce WordCountKaushal PrajapatiNo ratings yet
- Ayushman Bhattcharya - MCAN - 293 - Java Assignment4Document25 pagesAyushman Bhattcharya - MCAN - 293 - Java Assignment4Ayushman BhattacharyaNo ratings yet
- BDA4Document7 pagesBDA4nikithakatta0No ratings yet
- BDA LabManualDocument20 pagesBDA LabManualposprojectzNo ratings yet
- Java ProgramsDocument31 pagesJava ProgramsRaghu GowdaNo ratings yet
- Hadoop Training in HyderabadDocument49 pagesHadoop Training in HyderabadkellytechnologiesNo ratings yet
- Extending Ant: Steve LoughranDocument37 pagesExtending Ant: Steve LoughranLiam NoahNo ratings yet
- Big DataDocument25 pagesBig DataAnu GraphicsNo ratings yet
- Digital Assignment-1: Raghvendra Singh Sisodia 19bce1381Document12 pagesDigital Assignment-1: Raghvendra Singh Sisodia 19bce1381Raghvendra SisodiaNo ratings yet
- Installation of Apache Hadoop 2. Word Count ProgramDocument25 pagesInstallation of Apache Hadoop 2. Word Count Programnecn cse-b 2nd-yearNo ratings yet
- Analyzing The Data With HadoopDocument13 pagesAnalyzing The Data With HadoopVyshnavi ThottempudiNo ratings yet
- CMake ListsDocument4 pagesCMake Listsengelo89No ratings yet
- Setting up Notepad++ for C/C++/Java dev with scriptsDocument3 pagesSetting up Notepad++ for C/C++/Java dev with scriptsJustin WrightNo ratings yet
- Map reduceDocument4 pagesMap reducechetanruparel07awsNo ratings yet
- ANWESHA MONDAL - MCAN - 293 - Java Assignment4Document25 pagesANWESHA MONDAL - MCAN - 293 - Java Assignment4Ayushman BhattacharyaNo ratings yet
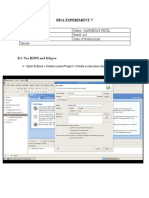
- Bda Experiment 7: Roll No. A-52 Name: Janmejay Patil Class: BE-A Batch: A3 Date of Experiment: Date of Submission GradeDocument8 pagesBda Experiment 7: Roll No. A-52 Name: Janmejay Patil Class: BE-A Batch: A3 Date of Experiment: Date of Submission GradeAlkaNo ratings yet
- Module10-BigData Guide v1.0Document6 pagesModule10-BigData Guide v1.0srinubasaniNo ratings yet
- CS246 TA Session: Hadoop Tutorial: Peyman Kazemian 1/11/2011Document13 pagesCS246 TA Session: Hadoop Tutorial: Peyman Kazemian 1/11/2011smitanair143No ratings yet
- MapReduce ExampleDocument3 pagesMapReduce ExampleRavi ChanderNo ratings yet
- Ce124 SDP Lab10Document29 pagesCe124 SDP Lab10thorwithstrombrakerNo ratings yet
- Java Pra FileDocument18 pagesJava Pra Filesantosh srivastavaNo ratings yet
- Abrir y Guardar Archivo de Texto TXT NetBeansDocument4 pagesAbrir y Guardar Archivo de Texto TXT NetBeansAlex RetrovilleNo ratings yet
- Department of Computer Science and Engineering: Delhi Technological University Big Data Analysis Lab-BDA E3-G3Document4 pagesDepartment of Computer Science and Engineering: Delhi Technological University Big Data Analysis Lab-BDA E3-G3IshanNo ratings yet
- BDA Lab 8 ManualDocument7 pagesBDA Lab 8 ManualMydah NasirNo ratings yet
- Assignment 2-033Document13 pagesAssignment 2-033DHARSHANA C PNo ratings yet
- WordCount Program Hadoop Task 2Document7 pagesWordCount Program Hadoop Task 220261A6757 VIJAYAGIRI ANIL KUMARNo ratings yet
- SalesData Map ReduceDocument3 pagesSalesData Map Reducebhavana16686No ratings yet
- 5 6138713691505295451Document2 pages5 6138713691505295451Shreyansh DiwanNo ratings yet
- Async TaskDocument3 pagesAsync TaskCM-Hitesh TolaniNo ratings yet
- How To Compile JAVA Program in Package From Command LineDocument15 pagesHow To Compile JAVA Program in Package From Command LineVinay KumarNo ratings yet
- Auto CompilationDocument1 pageAuto CompilationR TNo ratings yet
- Worksheet 6thDocument6 pagesWorksheet 6thNeeraj KukretiNo ratings yet
- Machine Learning/Data Science Interview Cheat Sheets: Aqeel AnwarDocument17 pagesMachine Learning/Data Science Interview Cheat Sheets: Aqeel AnwarJulie ArquizaNo ratings yet
- Dermatologist-Level Classification of Skin Cancer With Deep Neural NetworksDocument12 pagesDermatologist-Level Classification of Skin Cancer With Deep Neural NetworksVitaliy KustovNo ratings yet
- Impact of Deep Learning Assistance On The Histopathologic Review of Lymph Nodes For Metastatic Breast CancerDocument11 pagesImpact of Deep Learning Assistance On The Histopathologic Review of Lymph Nodes For Metastatic Breast CancerMiguel AngelNo ratings yet
- Fundus Photograph-Based Deep Learning Algorithms in Detecting Diabetic RetinopathyDocument13 pagesFundus Photograph-Based Deep Learning Algorithms in Detecting Diabetic RetinopathyMiguel AngelNo ratings yet
- Lecun98 PDFDocument46 pagesLecun98 PDFSy LarNo ratings yet
- Gnuplot PDFDocument3 pagesGnuplot PDFMiguel AngelNo ratings yet
- Graph500 BigData2016 PaperDocument8 pagesGraph500 BigData2016 PaperMiguel AngelNo ratings yet
- Notes PDFDocument407 pagesNotes PDFsrasrk11No ratings yet
- Computerized Local Dental Anesthetic Systemsgrace2003Document4 pagesComputerized Local Dental Anesthetic Systemsgrace2003Miguel AngelNo ratings yet
- A "Hands-On" Introduction To Openmp: Tim MattsonDocument200 pagesA "Hands-On" Introduction To Openmp: Tim MattsonMiguel AngelNo ratings yet
- How To - Oscam Compile TutorialDocument5 pagesHow To - Oscam Compile TutorialDot-InsightNo ratings yet
- LSB Steganography: by Tejasram (A046) & Soham Nanavati (A039)Document17 pagesLSB Steganography: by Tejasram (A046) & Soham Nanavati (A039)SHIIJIN KUMAR P SNo ratings yet
- Scope Proposal Ecommerce WebsiteDocument25 pagesScope Proposal Ecommerce WebsiteAle80% (10)
- Jan 31 2023) CT226094 SVL-R40A O2 Sensor CheckDocument13 pagesJan 31 2023) CT226094 SVL-R40A O2 Sensor CheckchristiamNo ratings yet
- E560 RP570-71 SubDocument49 pagesE560 RP570-71 SubTuan Dung LuNo ratings yet
- Kids Shoe Size ChartDocument1 pageKids Shoe Size ChartKatie SquireNo ratings yet
- 1000 MEQs - Software Engineering 100Document227 pages1000 MEQs - Software Engineering 100Dutta Computer AcademyNo ratings yet
- AP M T B S: Jeff Eidenshink, Brian Schwind, Ken Brewer, Zhi-Liang Zhu, Brad Quayle and Stephen HowardDocument19 pagesAP M T B S: Jeff Eidenshink, Brian Schwind, Ken Brewer, Zhi-Liang Zhu, Brad Quayle and Stephen HowardConeyvin Arreza SalupadoNo ratings yet
- Simulation of Electric Vehicles Based On SimulinkDocument8 pagesSimulation of Electric Vehicles Based On SimulinkHoàng Chu ĐứcNo ratings yet
- Prepositions of Place - My RoomDocument1 pagePrepositions of Place - My RoomStela Pavetić100% (1)
- Cyber Controller InstallationDocument21 pagesCyber Controller Installationpurinut9988No ratings yet
- Reynolds Equation - ME17 - 36Document6 pagesReynolds Equation - ME17 - 36parth bhala0% (1)
- ADNAN AhmedDocument19 pagesADNAN AhmedChanna AdnanNo ratings yet
- p62 63 PDFDocument2 pagesp62 63 PDFborden marimira100% (1)
- General Specifications: GS 33J20C10-01ENDocument6 pagesGeneral Specifications: GS 33J20C10-01ENtwirpxNo ratings yet
- Solution TestBlanc Oracle11g PDFDocument5 pagesSolution TestBlanc Oracle11g PDFŰučëf ÂťŕNo ratings yet
- Purple Futuristic Pitch Deck PresentationDocument30 pagesPurple Futuristic Pitch Deck PresentationEljine OchoaNo ratings yet
- MY NEW LIFE MAIN WALKTHROUGH v. 1.7 FixedDocument54 pagesMY NEW LIFE MAIN WALKTHROUGH v. 1.7 FixedHenry CardozaNo ratings yet
- Big Data Analytics White PaperDocument38 pagesBig Data Analytics White PaperDaniela StaciNo ratings yet
- Little Navmap User Manual enDocument384 pagesLittle Navmap User Manual enEmin bojecNo ratings yet
- Intelligent Magnetic Stripe ECU2Document7 pagesIntelligent Magnetic Stripe ECU2CollenNo ratings yet
- FLIR A315 DatasheetDocument12 pagesFLIR A315 DatasheetsinhabillolNo ratings yet
- PHP NotesDocument149 pagesPHP NotesNavaneet Knights100% (1)
- Wa0031Document59 pagesWa0031MUKUND PALNo ratings yet
- Control System and Solutions - Global Case Study Collection - JIV1901 PDFDocument11 pagesControl System and Solutions - Global Case Study Collection - JIV1901 PDFcodefinderNo ratings yet
- B Routing CG Asr9000 62xDocument798 pagesB Routing CG Asr9000 62xNaz LunNo ratings yet
- Command-Line - ¿Qué VIRT, RES y SHR Significa HTOPDocument2 pagesCommand-Line - ¿Qué VIRT, RES y SHR Significa HTOPKaryn AntunezNo ratings yet
- 2Document27 pages2Giby MathewNo ratings yet
- 3 HazardsDocument74 pages3 HazardsAnam GhaffarNo ratings yet
- Learn Kivy MDDocument406 pagesLearn Kivy MDSaumya BondreNo ratings yet