You might also like
- SAS Programming Guidelines Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- Distributed Databases: Chapter 1: IntroductionDocument30 pagesDistributed Databases: Chapter 1: IntroductionNagarjuna ReddyNo ratings yet
- Concepts Structure Advantages Disadvantages Trade-OffsDocument18 pagesConcepts Structure Advantages Disadvantages Trade-Offsrinkigarg_13No ratings yet
- Distributed Database DesignDocument86 pagesDistributed Database Designapi-3798071100% (3)
- CSE 453 Slide 1Document46 pagesCSE 453 Slide 1JAWAD UL KABIRNo ratings yet
- Oracle course details and key conceptsDocument27 pagesOracle course details and key conceptsraghuyadavNo ratings yet
- Distributed Database Systems: Vera GoebelDocument58 pagesDistributed Database Systems: Vera GoebelhamesNo ratings yet
- Distributed Database SystemsDocument311 pagesDistributed Database SystemsEfrain Sanjay AdhikaryNo ratings yet
- dATA Base LectureDocument32 pagesdATA Base LectureJessiNo ratings yet
- CH 1Document32 pagesCH 1pir zadaNo ratings yet
- Homogenous and Heterogenous SystemDocument20 pagesHomogenous and Heterogenous Systempraful_barapatre100% (6)
- Distributed Database Management SystemsDocument23 pagesDistributed Database Management Systemssuganya004No ratings yet
- FinalDocument46 pagesFinalVinod KumarNo ratings yet
- Distributed Database Management SystemsDocument123 pagesDistributed Database Management SystemsMaryamNo ratings yet
- Distributed Database DesignDocument85 pagesDistributed Database Designapi-379807188% (8)
- The Big Data EcosystemDocument42 pagesThe Big Data EcosystemyagoencuestasNo ratings yet
- Distributed DBMS Components & CharacteristicsDocument22 pagesDistributed DBMS Components & CharacteristicsWêēdhzæmē ApdyræhmæåñNo ratings yet
- Week 02 - Creating DB Env 2020Document45 pagesWeek 02 - Creating DB Env 2020MADINA SURAYA BINTI ZHARIN A20EC0203No ratings yet
- Unit-1 Introduction To DDBMSDocument50 pagesUnit-1 Introduction To DDBMSKeshav SharmaNo ratings yet
- Database Management System (DBMS): An OverviewDocument34 pagesDatabase Management System (DBMS): An OverviewCynthia UmubyeyiNo ratings yet
- Chapter - 7 Distributed Database SystemDocument58 pagesChapter - 7 Distributed Database SystemdawodNo ratings yet
- Distributed Database ConceptDocument18 pagesDistributed Database ConceptFouziya AnsariNo ratings yet
- 3 Levels of Database ArchitectureDocument19 pages3 Levels of Database ArchitectureleonardbankzNo ratings yet
- Big DataDocument29 pagesBig DataAnanya KhannaNo ratings yet
- Lesson 1Document26 pagesLesson 1Ahmed AdelNo ratings yet
- CSC457 DOOD - ClassnotesDocument113 pagesCSC457 DOOD - ClassnotesPrabin SilwalNo ratings yet
- Distributed DatabaseDocument24 pagesDistributed DatabaseHimashree BhuyanNo ratings yet
- Distributed Database Management SystemsDocument63 pagesDistributed Database Management SystemsRimpz ╰❥No ratings yet
- DTSc1 PDFDocument86 pagesDTSc1 PDFBimbo De LeonNo ratings yet
- K2View Data Fabric Technical WhitepaperDocument19 pagesK2View Data Fabric Technical Whitepaper1977amNo ratings yet
- Distributed DBMS ArchitectureDocument49 pagesDistributed DBMS ArchitectureMahboobNo ratings yet
- Introduction To Distributed Data Processing (DDP) : G53DBCDocument4 pagesIntroduction To Distributed Data Processing (DDP) : G53DBCAdityaNo ratings yet
- Lec2 DB EnviromentDocument34 pagesLec2 DB Enviromentkillerscorpion381No ratings yet
- Unit - Iii Database Management SystemsDocument42 pagesUnit - Iii Database Management SystemsporseenaNo ratings yet
- Introduction to Distributed Database SystemsDocument18 pagesIntroduction to Distributed Database SystemsAkram TahaNo ratings yet
- Chapter 1Document48 pagesChapter 12023299022No ratings yet
- Distributed Database Management Systems (DDBMS) : Muhammad Hamiz Mohd Radzi Faiqah Hafidzah HalimDocument62 pagesDistributed Database Management Systems (DDBMS) : Muhammad Hamiz Mohd Radzi Faiqah Hafidzah HalimAmmr AmnNo ratings yet
- Database Fundamentals: Made By: Shahinaz S. Azab Edited By: Mona SalehDocument25 pagesDatabase Fundamentals: Made By: Shahinaz S. Azab Edited By: Mona SalehfsdgNo ratings yet
- Iii. Current Trends: Distributed Databases and DBMSS: Concepts and DesignDocument32 pagesIii. Current Trends: Distributed Databases and DBMSS: Concepts and Designpradeep_gupta43No ratings yet
- Introduction To DatabasesDocument24 pagesIntroduction To DatabasesIvy JaniceNo ratings yet
- Distributed Database ConceptsDocument52 pagesDistributed Database ConceptsJoel wakhunguNo ratings yet
- AMS PresentationDocument24 pagesAMS PresentationShowkat HossainNo ratings yet
- Database Management SoftwareDocument34 pagesDatabase Management SoftwareDonna OwenNo ratings yet
- Database Architecture OverviewDocument23 pagesDatabase Architecture OverviewRabin KCNo ratings yet
- DBMS-LECDocument27 pagesDBMS-LECyusha habibNo ratings yet
- Introduction To Databases TransparenciesDocument22 pagesIntroduction To Databases TransparenciesSaleh NjoholeNo ratings yet
- Lec 2 Advantages DBMS and SchemaDocument35 pagesLec 2 Advantages DBMS and SchemaUCIZAMBO ITNo ratings yet
- Chapter 12Document71 pagesChapter 12Chandu ReddyNo ratings yet
- Distributed Database: SourceDocument19 pagesDistributed Database: SourcePro rushoNo ratings yet
- Distributed Databases and Client-Server Architectures: File Systems: MotivationDocument38 pagesDistributed Databases and Client-Server Architectures: File Systems: Motivationacer551No ratings yet
- Unit 1Document35 pagesUnit 1ssNo ratings yet
- Distributed DBDocument146 pagesDistributed DBAnonymous jLw94L1SNo ratings yet
- Overview of Physical Database Design MethodologyDocument5 pagesOverview of Physical Database Design MethodologyaffiNo ratings yet
- Unit - I Distributed Data ProcessingDocument27 pagesUnit - I Distributed Data ProcessingHarsha VardhanNo ratings yet
- Flat File SystemDocument18 pagesFlat File SystemSushil Kumar GoelNo ratings yet
- Introduction To Distributed Database PresentationDocument67 pagesIntroduction To Distributed Database PresentationShrunkhala Wankhede BadwaikNo ratings yet
- Comp ReviewersDocument10 pagesComp ReviewersLyerey Jed MartinNo ratings yet
- QueryProcessing Lect 3Document26 pagesQueryProcessing Lect 3allyNo ratings yet
- 9780198079064Document62 pages9780198079064Sanjid ElahiNo ratings yet
- Lecture Nine 8086 Microprocessor Memory and I/O Interfacing: March 2020Document23 pagesLecture Nine 8086 Microprocessor Memory and I/O Interfacing: March 2020ally0% (1)
- Distributed Database DesignDocument51 pagesDistributed Database DesignallyNo ratings yet
- Microprocessors AllDocument111 pagesMicroprocessors Alldarsh ray100% (1)
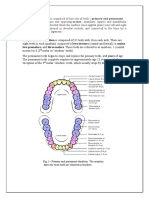
- DentDocument4 pagesDentallyNo ratings yet
- 8086 Memory OrganizationDocument6 pages8086 Memory OrganizationManohar_3020No ratings yet
- Zener DiodeDocument12 pagesZener DiodeallyNo ratings yet
- Common Derivatives IntegralsDocument4 pagesCommon Derivatives Integralsapi-243574449No ratings yet
- Binational Circuits 2013Document31 pagesBinational Circuits 2013allyNo ratings yet
- Lecture 6Document13 pagesLecture 6allyNo ratings yet
- Zener DiodeDocument12 pagesZener DiodeallyNo ratings yet
- Zener DiodeDocument12 pagesZener DiodeallyNo ratings yet
- Signals and Systems: Dr. MuayadDocument11 pagesSignals and Systems: Dr. MuayadallyNo ratings yet
- Application of Fast-Fourier-Transform Techniques To The Discrete-Dipole ApproximationDocument3 pagesApplication of Fast-Fourier-Transform Techniques To The Discrete-Dipole ApproximationallyNo ratings yet
- 3 - 3 Digital Signals: in Information For and Than - ForDocument12 pages3 - 3 Digital Signals: in Information For and Than - ForallyNo ratings yet
- 3 - 3 Digital Signals: in Information For and Than - ForDocument12 pages3 - 3 Digital Signals: in Information For and Than - ForallyNo ratings yet
- X (K) (K) + X2 (K) (K O, I,) X (K+ ) XL (K+ ) +wik+ ) X2 (K+ )Document4 pagesX (K) (K) + X2 (K) (K O, I,) X (K+ ) XL (K+ ) +wik+ ) X2 (K+ )allyNo ratings yet
- Coronaviruses Are From The Family Coronaviridae and Are: Severe Acute Respiratory Syndrome SarsDocument2 pagesCoronaviruses Are From The Family Coronaviridae and Are: Severe Acute Respiratory Syndrome SarsallyNo ratings yet
- HP ProCurve Switch 2610 Series Product OverviewDocument2 pagesHP ProCurve Switch 2610 Series Product OverviewBong FamisNo ratings yet
- Connect digital gauges and devices to applications with InGuage USB interfaceDocument2 pagesConnect digital gauges and devices to applications with InGuage USB interfaceboonlueNo ratings yet
- Department of Education Schools Division Office P. Urduja ST., Doña Rosario Subd., Novaliches, Quezon City Tel. No. 352-59-43Document4 pagesDepartment of Education Schools Division Office P. Urduja ST., Doña Rosario Subd., Novaliches, Quezon City Tel. No. 352-59-43Gean AcabalNo ratings yet
- Site Selection CriteriaDocument15 pagesSite Selection CriteriaashrafertoNo ratings yet
- Customer Experience Management A Handbook To Acquire and Retain Valuable CustomersDocument10 pagesCustomer Experience Management A Handbook To Acquire and Retain Valuable CustomersFranco Garcia VillenaNo ratings yet
- Phoenix SIL2 RelayDocument5 pagesPhoenix SIL2 Relaysteam100deg1658No ratings yet
- ASMSRDDocument13 pagesASMSRDjai_varmanNo ratings yet
- IVMS-4200v2.8.2.2 Release Note - InternalDocument3 pagesIVMS-4200v2.8.2.2 Release Note - InternalnajjaciNo ratings yet
- Bill of Materials and Cost Estimates Description QTY Unit Unit Cost Total Cost Site Works PHP 17,854.77Document8 pagesBill of Materials and Cost Estimates Description QTY Unit Unit Cost Total Cost Site Works PHP 17,854.77RavNo ratings yet
- 4.1.1.2 Packet Tracer - Packet Tracer Physical ViewDocument16 pages4.1.1.2 Packet Tracer - Packet Tracer Physical ViewBetelihem DawitNo ratings yet
- 3-Totally Integrated Automation ChemicalDocument30 pages3-Totally Integrated Automation ChemicalUmesh SNo ratings yet
- Sony E-T-CON PCB For Television KDL-43W800C S0189585611Document5 pagesSony E-T-CON PCB For Television KDL-43W800C S0189585611supergasNo ratings yet
- Specificities Human Resource Management in It Companies: September 2023Document6 pagesSpecificities Human Resource Management in It Companies: September 2023kanayabilaaaNo ratings yet
- X and y I.e., For Arguments and Entries Values, and Plot The Different Points On The Graph ForDocument4 pagesX and y I.e., For Arguments and Entries Values, and Plot The Different Points On The Graph ForFinanti Puja DwikasihNo ratings yet
- Surgical Nursing Lecture NotesDocument203 pagesSurgical Nursing Lecture NotesKwabena AmankwaNo ratings yet
- A Convenient Approach For Penalty Parameter Selection in Robust Lasso RegressionDocument12 pagesA Convenient Approach For Penalty Parameter Selection in Robust Lasso Regressionasfar as-salafiyNo ratings yet
- Smart Mirror CatalogDocument28 pagesSmart Mirror CatalogfoursoulNo ratings yet
- HP Latex 3000 Printer SMDocument1,069 pagesHP Latex 3000 Printer SMMario BraićNo ratings yet
- Simulating The "First Steps" of A Walking Hexapod Robot: Ing. R. Woering CST 2010.075Document81 pagesSimulating The "First Steps" of A Walking Hexapod Robot: Ing. R. Woering CST 2010.075Alina MirelaNo ratings yet
- ASCE702W Wind Analysis Program for ASCE 7-02 CodeDocument15 pagesASCE702W Wind Analysis Program for ASCE 7-02 CodeHgagselim SelimNo ratings yet
- Water Based Printing For Beginners Ebook v1 PDFDocument37 pagesWater Based Printing For Beginners Ebook v1 PDFmdipu5_948971128No ratings yet
- Position of Ipv4 in Tcp/Ip Protocol SuiteDocument19 pagesPosition of Ipv4 in Tcp/Ip Protocol SuiteAyushi GuptaNo ratings yet
- Array ProgramsDocument31 pagesArray ProgramsMadhav TibrewalNo ratings yet
- Abbreviations, Acronyms and Common TermDocument28 pagesAbbreviations, Acronyms and Common TermyatishNo ratings yet
- MIT2 14S14 Prob Archive PDFDocument674 pagesMIT2 14S14 Prob Archive PDFKamal PatelNo ratings yet
- 0 AbdulrehmanDocument1 page0 Abdulrehmanabdulrehman khanNo ratings yet
- Resume of Brianjkim1980Document1 pageResume of Brianjkim1980api-28487603No ratings yet
- Grade 08 ICT Lesson 03Document10 pagesGrade 08 ICT Lesson 03Suhada JayamanneNo ratings yet
- Updated Transformers Notes 6th Sem EEE CAEDDocument42 pagesUpdated Transformers Notes 6th Sem EEE CAEDdeepu kumarNo ratings yet
- ARM7 TDMI Manual Pt3Document46 pagesARM7 TDMI Manual Pt3Deepanshu UpadhyayNo ratings yet