You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Official Statement On Public RelationsDocument1 pageOfficial Statement On Public RelationsAlexandra ZachiNo ratings yet
- 722.6 Transmission Conductor Plate Replacement DIYDocument3 pages722.6 Transmission Conductor Plate Replacement DIYcamaro67427100% (1)
- Applying From OUTSIDE The UK (Permission To Enter) : Online Application Form GuideDocument29 pagesApplying From OUTSIDE The UK (Permission To Enter) : Online Application Form GuideRaja Sekhar BattuNo ratings yet
- LTHE Stage 2.4 ConsolidationDocument6 pagesLTHE Stage 2.4 ConsolidationRaja Sekhar BattuNo ratings yet
- 2017 Exam PaperDocument2 pages2017 Exam PaperRaja Sekhar BattuNo ratings yet
- How To Build and Fly DronesDocument2 pagesHow To Build and Fly DronesRaja Sekhar BattuNo ratings yet
- Evan Grant TED Talk EvaluationDocument1 pageEvan Grant TED Talk EvaluationRaja Sekhar BattuNo ratings yet
- 2019 PSY1205 PaperDocument3 pages2019 PSY1205 PaperRaja Sekhar BattuNo ratings yet
- 2017 Model AnswersDocument19 pages2017 Model AnswersRaja Sekhar BattuNo ratings yet
- 2019 PSY1205 PaperDocument3 pages2019 PSY1205 PaperRaja Sekhar BattuNo ratings yet
- Sub: Engagement of Graduate Engineering Apprentices Under The Apprentices Act 1961Document1 pageSub: Engagement of Graduate Engineering Apprentices Under The Apprentices Act 1961Raja Sekhar BattuNo ratings yet
- Design and Finite Element Analysis of Ai PDFDocument7 pagesDesign and Finite Element Analysis of Ai PDFRaja Sekhar BattuNo ratings yet
- Friction and Wear Mechanisms of A Thermoplastic Composite GF/PA6 Subjected To Different Thermal HistoriesDocument7 pagesFriction and Wear Mechanisms of A Thermoplastic Composite GF/PA6 Subjected To Different Thermal HistoriesRaja Sekhar BattuNo ratings yet
- Academic Technology Approval Scheme (ATAS) - GOV - UkDocument4 pagesAcademic Technology Approval Scheme (ATAS) - GOV - UkRaja Sekhar Battu0% (1)
- RTI Application Exposes AAI FraudDocument2 pagesRTI Application Exposes AAI FraudsolomonNo ratings yet
- (Mathematics in Industry 13) Wil Schilders (auth.), Wilhelmus H. A. Schilders, Henk A. van der Vorst, Joost Rommes (eds.) - Model order reduction_ theory, research aspects and applications-Springer-VeDocument463 pages(Mathematics in Industry 13) Wil Schilders (auth.), Wilhelmus H. A. Schilders, Henk A. van der Vorst, Joost Rommes (eds.) - Model order reduction_ theory, research aspects and applications-Springer-VeRaja Sekhar BattuNo ratings yet
- DynamicsDocument18 pagesDynamicsSon TranNo ratings yet
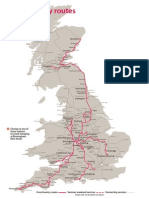
- CrossCountry routes map of stationsDocument1 pageCrossCountry routes map of stationsvitw1844No ratings yet
- HD14 Vibes Continuous Systems 2008Document2 pagesHD14 Vibes Continuous Systems 2008Raja Sekhar BattuNo ratings yet
- Vibration of Continuous SystemsDocument21 pagesVibration of Continuous SystemsHossam T BadranNo ratings yet
- Research ScholarshipsDocument2 pagesResearch ScholarshipsRaja Sekhar BattuNo ratings yet
- U C Jindal PDFDocument1,043 pagesU C Jindal PDFRaja Sekhar Battu100% (1)
- HD14 Vibes Continuous Systems 2008Document34 pagesHD14 Vibes Continuous Systems 2008Guatavo91No ratings yet
- Jo'?y/'f'.cr: . On.. /) :) / o /JJ "'/ "Em /. /N') - , /./. (Document2 pagesJo'?y/'f'.cr: . On.. /) :) / o /JJ "'/ "Em /. /N') - , /./. (Raja Sekhar BattuNo ratings yet
- Understanding the Structure and Function of a Quantum Beam TunnelDocument2 pagesUnderstanding the Structure and Function of a Quantum Beam TunnelRaja Sekhar BattuNo ratings yet
- Total Deformation: Subject: Author: Prepared For: Date CommentsDocument1 pageTotal Deformation: Subject: Author: Prepared For: Date CommentsRaja Sekhar BattuNo ratings yet
- Proceedings of International Conference Applications of Structural Fire Engineering Prague, 19-20 February 2009Document71 pagesProceedings of International Conference Applications of Structural Fire Engineering Prague, 19-20 February 2009Raja Sekhar BattuNo ratings yet
- Formulas and concepts for profit, loss, time, distance, speed, partnership and moreDocument9 pagesFormulas and concepts for profit, loss, time, distance, speed, partnership and morePrashanth MohanNo ratings yet
- Ielts 42 Topics For Speaking Part 1Document32 pagesIelts 42 Topics For Speaking Part 1Zaryab Nisar100% (1)
- (Fluid Mechanics and Its Applications 9) T.K.S. Murthy-Computational Methods in Hypersonic Aerodynamics-Computational Mechanics Publications_ Kluwer Academic Publishers_ Sold and Distributed in the U.Document524 pages(Fluid Mechanics and Its Applications 9) T.K.S. Murthy-Computational Methods in Hypersonic Aerodynamics-Computational Mechanics Publications_ Kluwer Academic Publishers_ Sold and Distributed in the U.Raja Sekhar BattuNo ratings yet
- Formulas and concepts for profit, loss, time, distance, speed, partnership and moreDocument9 pagesFormulas and concepts for profit, loss, time, distance, speed, partnership and morePrashanth MohanNo ratings yet
- The Tower Undergraduate Research Journal Volume VI, Issue IDocument92 pagesThe Tower Undergraduate Research Journal Volume VI, Issue IThe Tower Undergraduate Research JournalNo ratings yet
- General Appraiser Market Analysis and Highest & Best Use-Schedule PDFDocument7 pagesGeneral Appraiser Market Analysis and Highest & Best Use-Schedule PDFadonisghlNo ratings yet
- Work Sample - Wencan XueDocument13 pagesWork Sample - Wencan XueWencan XueNo ratings yet
- Pore and Formation PressureDocument4 pagesPore and Formation PressureramadhanipdNo ratings yet
- SARTIKA LESTARI PCR COVID-19 POSITIVEDocument1 pageSARTIKA LESTARI PCR COVID-19 POSITIVEsartika lestariNo ratings yet
- Os8 - XCVR 8.7r3 RevaDocument85 pagesOs8 - XCVR 8.7r3 RevaDouglas SantosNo ratings yet
- Company Profile Nadal en PDFDocument2 pagesCompany Profile Nadal en PDFkfctco100% (1)
- Quick Start Guide - QualiPoc AndroidDocument24 pagesQuick Start Guide - QualiPoc AndroidDmitekNo ratings yet
- Ib Tok 2014 Unit PlanDocument10 pagesIb Tok 2014 Unit Planapi-273471349No ratings yet
- Abstract PracticeDocument4 pagesAbstract PracticerifqiNo ratings yet
- History of CAD - CAE CompaniesDocument5 pagesHistory of CAD - CAE CompaniesAntonio C. KeithNo ratings yet
- Homework FileDocument18 pagesHomework FiledariadybaNo ratings yet
- GCSE Combined Science PDFDocument198 pagesGCSE Combined Science PDFMpumelelo Langalethu MoyoNo ratings yet
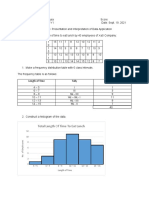
- Cedrix James Estoquia - OLLC Lesson 4.6 Presentation and Interpretation of Data ApplicationDocument4 pagesCedrix James Estoquia - OLLC Lesson 4.6 Presentation and Interpretation of Data ApplicationDeuK WR100% (1)
- Government of India Sponsored Study on Small Industries Potential in Sultanpur DistrictDocument186 pagesGovernment of India Sponsored Study on Small Industries Potential in Sultanpur DistrictNisar Ahmed Ansari100% (1)
- Benevolent Assimilation Proclamation AnalysisDocument4 pagesBenevolent Assimilation Proclamation AnalysishgjfjeuyhdhNo ratings yet
- Basic Instructions: A Load (Contact) SymbolDocument3 pagesBasic Instructions: A Load (Contact) SymbolBaijayanti DasNo ratings yet
- KNS 1063 Bending and Shear Stress AnalysisDocument11 pagesKNS 1063 Bending and Shear Stress AnalysisLuna LatisyaNo ratings yet
- 10.6 Heat Conduction Through Composite WallsDocument35 pages10.6 Heat Conduction Through Composite WallsEngr Muhammad AqibNo ratings yet
- Baikal Izh 18mh ManualDocument24 pagesBaikal Izh 18mh ManualMet AfuckNo ratings yet
- Autochief® C20: Engine Control and Monitoring For General ElectricDocument2 pagesAutochief® C20: Engine Control and Monitoring For General ElectricВадим ГаранNo ratings yet
- Materiality of Cultural ConstructionDocument3 pagesMateriality of Cultural ConstructionPaul YeboahNo ratings yet
- FS2-EP-12 - LanceDocument9 pagesFS2-EP-12 - LanceLance Julien Mamaclay MercadoNo ratings yet
- Fif-12 Om Eng Eaj23x102Document13 pagesFif-12 Om Eng Eaj23x102Schefer FabianNo ratings yet
- Synopsis On Training & DevelopmentDocument6 pagesSynopsis On Training & DevelopmentArchi gupta86% (14)
- Samuel Mendez, "Health Equity Rituals: A Case For The Ritual View of Communication in An Era of Precision Medicine"Document227 pagesSamuel Mendez, "Health Equity Rituals: A Case For The Ritual View of Communication in An Era of Precision Medicine"MIT Comparative Media Studies/WritingNo ratings yet
- Python Quals PytestDocument4 pagesPython Quals PytestAnkit RathoreNo ratings yet
- VISAYAS STATE UNIVERSITY Soil Science Lab on Rocks and MineralsDocument5 pagesVISAYAS STATE UNIVERSITY Soil Science Lab on Rocks and MineralsAleah TyNo ratings yet