You might also like
- cobas8000-DataManager - Host Interface Manual10205 PDFDocument286 pagescobas8000-DataManager - Host Interface Manual10205 PDF박수희No ratings yet
- Afar ProblemsDocument17 pagesAfar ProblemsCrissa Mae Falsis100% (1)
- Case Study RajinderDocument83 pagesCase Study Rajinderapi-161284356100% (1)
- Hodgkin's Lymphoma Stages, Types & Reed-Sternberg CellsDocument63 pagesHodgkin's Lymphoma Stages, Types & Reed-Sternberg CellsHabiba MehmoodNo ratings yet
- Who Leprosy Control BurdenDocument44 pagesWho Leprosy Control BurdenClaire SoletaNo ratings yet
- Telemedicine framework for COVIDDocument3 pagesTelemedicine framework for COVIDAngela NeriNo ratings yet
- Nursing Care Plan Group 3 C2e s2Document5 pagesNursing Care Plan Group 3 C2e s2Frian MariñasNo ratings yet
- A Young Man's Unrequited Love and Its Universal LessonDocument3 pagesA Young Man's Unrequited Love and Its Universal LessonMika SaldañaNo ratings yet
- Electrical Application and Installation Guide For Petroleum TransmissionsDocument131 pagesElectrical Application and Installation Guide For Petroleum Transmissionsharikrishnanpd3327100% (2)
- Imbalanced Nutrition Less Than Body Requirement R/T Insufficient Intake of Food Rich in Potassium and Intestinal DisturbancesDocument22 pagesImbalanced Nutrition Less Than Body Requirement R/T Insufficient Intake of Food Rich in Potassium and Intestinal DisturbancesJor GarciaNo ratings yet
- DRUG STUDY-danaDocument3 pagesDRUG STUDY-danairish_estrellaNo ratings yet
- COPD: Chronic Obstructive Pulmonary DiseaseDocument3 pagesCOPD: Chronic Obstructive Pulmonary DiseaseRichard TanNo ratings yet
- Nursing DiagnosisDocument5 pagesNursing DiagnosisGeovanni Rai HermanoNo ratings yet
- Chapter 3 - DJDocument3 pagesChapter 3 - DJEunice GabrielNo ratings yet
- Patient ChartDocument2 pagesPatient ChartHydieNo ratings yet
- Elastic Constants of A Rubber TubeDocument4 pagesElastic Constants of A Rubber TubenNo ratings yet
- Impaired Skin Integrity For NCP Oct. 212020Document2 pagesImpaired Skin Integrity For NCP Oct. 212020Benjie DimayacyacNo ratings yet
- Chapter 1-3Document27 pagesChapter 1-3JellyAnnGomezNo ratings yet
- Notes On PhenomenologyDocument5 pagesNotes On PhenomenologyDon Chiaw ManongdoNo ratings yet
- Final Integrative ReviewDocument24 pagesFinal Integrative Reviewapi-328315559No ratings yet
- Chest Injury QuestionsDocument3 pagesChest Injury QuestionsNicole Genevie MallariNo ratings yet
- Solved Problems in Definite IntegralsDocument7 pagesSolved Problems in Definite IntegralsJayson AcostaNo ratings yet
- KARDEXDocument2 pagesKARDEXChristine Joy Camacho100% (1)
- Professional Nursing Research PaperDocument6 pagesProfessional Nursing Research Paperapi-357132774No ratings yet
- Reviewer - Muscular SystemDocument11 pagesReviewer - Muscular SystemIvy Jan OcateNo ratings yet
- One-Way ANOVA PDFDocument20 pagesOne-Way ANOVA PDFBliss ManNo ratings yet
- Crs Peripheral Artery Disease - Billi Brian GeniroDocument21 pagesCrs Peripheral Artery Disease - Billi Brian Genirofathiya nurkhalisaNo ratings yet
- Research Paper PDFDocument11 pagesResearch Paper PDFevaNo ratings yet
- Practice Summary Paper For PortfolioDocument9 pagesPractice Summary Paper For Portfolioapi-290938460No ratings yet
- Potassium Chloride Injection Product MonographDocument18 pagesPotassium Chloride Injection Product MonographMatthew ParsonsNo ratings yet
- Benefit Packages For Inpatient Care of Probable and Confirmed COVID-19 Developing Severe Illness / OutcomesDocument31 pagesBenefit Packages For Inpatient Care of Probable and Confirmed COVID-19 Developing Severe Illness / OutcomesGeneXpert Lab LCPNo ratings yet
- Unit-Iii Gordon's Functional Health PatternsDocument3 pagesUnit-Iii Gordon's Functional Health Patternsalphabennydelta4468No ratings yet
- 47Document2 pages47Gpe C. BaronNo ratings yet
- Incident Report Form JrubioDocument2 pagesIncident Report Form Jrubioapi-389592662No ratings yet
- Case Analysis Bsn309 NeriDocument3 pagesCase Analysis Bsn309 NeriAngela NeriNo ratings yet
- Chapter 3 Client PresentationDocument4 pagesChapter 3 Client PresentationEllePeiNo ratings yet
- HypertensionDocument2 pagesHypertensionsigit_riyantono100% (1)
- Letter Consent To Participate FormDocument5 pagesLetter Consent To Participate FormkeithNo ratings yet
- Hodgkin Lymphoma 2023 Update On Diagnosis, Risk-Stratification, and ManagementDocument24 pagesHodgkin Lymphoma 2023 Update On Diagnosis, Risk-Stratification, and ManagementZuri100% (1)
- CVA Case AnalysisDocument11 pagesCVA Case AnalysisFrancis PeterosNo ratings yet
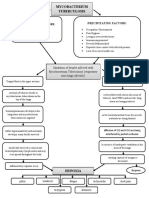
- Mycobacterium Tuberculosis: Precipitating Factors: Predisposing FactorsDocument1 pageMycobacterium Tuberculosis: Precipitating Factors: Predisposing FactorsYoko Mae Yano100% (1)
- Student-Survey-Infographic Effects of COVID 19 To Mental HealthDocument1 pageStudent-Survey-Infographic Effects of COVID 19 To Mental HealthCarlo Acain TungpalanNo ratings yet
- Assessment of Digestive and Gi FunctionDocument3 pagesAssessment of Digestive and Gi FunctionEmi EspinoNo ratings yet
- NRES Thesis - Chapter 1 3Y3-7Document16 pagesNRES Thesis - Chapter 1 3Y3-7acorpuz_4No ratings yet
- Policy Brief Homeless and HealthcareDocument4 pagesPolicy Brief Homeless and Healthcareapi-239640492No ratings yet
- Post Traumatic Stress in Nurses RevDocument13 pagesPost Traumatic Stress in Nurses RevCharles Mwangi WaweruNo ratings yet
- Pds Social PDFDocument232 pagesPds Social PDFShambhu Ashok100% (2)
- Suppositories: Abenol (CAN)Document2 pagesSuppositories: Abenol (CAN)Mikko McDonie VeloriaNo ratings yet
- Respect The Rights of Others Here in The Philippines What Might HappenDocument2 pagesRespect The Rights of Others Here in The Philippines What Might Happenpatricia_rolluquiNo ratings yet
- Write A Descriptive Title For The Questionnaire Write An Introduction To The QuestionnaireDocument4 pagesWrite A Descriptive Title For The Questionnaire Write An Introduction To The QuestionnaireRolando Alonso MoralesNo ratings yet
- M6 Check in Activity 1Document2 pagesM6 Check in Activity 1Alizah BucotNo ratings yet
- Research Samples and ExplanationsDocument56 pagesResearch Samples and ExplanationsJes SelNo ratings yet
- Career Development PlanDocument3 pagesCareer Development PlanRagniJethiNo ratings yet
- Sample Paper 1Document36 pagesSample Paper 1Annshai Jam MetanteNo ratings yet
- TSH TestDocument5 pagesTSH TestdenalynNo ratings yet
- Community Survey ToolDocument3 pagesCommunity Survey ToolMARWA MAMONGCAL100% (1)
- Bone Fracture Concept MapDocument1 pageBone Fracture Concept MapJette Charmae OlboNo ratings yet
- CDx-Brgy-704-Final - PDF Version 1Document103 pagesCDx-Brgy-704-Final - PDF Version 1Reymart FernandezNo ratings yet
- TB Nursing CareplanDocument14 pagesTB Nursing CareplanEstherThompson100% (1)
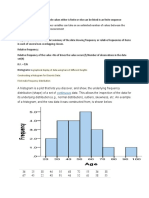
- Steam and - Leaf DisplayDocument25 pagesSteam and - Leaf DisplayKuldeepPaudel100% (1)
- Unit 1.2Document4 pagesUnit 1.2Akash kumarNo ratings yet
- Brand Loyalty Statistics AnalysisDocument38 pagesBrand Loyalty Statistics Analysissaad farooqNo ratings yet
- Statistics - 1: Presentation of DataDocument37 pagesStatistics - 1: Presentation of Datanpk007No ratings yet
- Data Structure Interview QuestionsDocument25 pagesData Structure Interview QuestionsVishal PadharNo ratings yet
- Node - Js Interview QuestionsDocument13 pagesNode - Js Interview QuestionsVishal PadharNo ratings yet
- Asp Net Interview QuestionsDocument14 pagesAsp Net Interview QuestionsVishal PadharNo ratings yet
- Docker Basic QuestionsDocument12 pagesDocker Basic QuestionsVishal PadharNo ratings yet
- Angular Interview Que AnsDocument2 pagesAngular Interview Que AnsVishal PadharNo ratings yet
- Dotnet Core Interview Que AnsDocument4 pagesDotnet Core Interview Que AnsVishal Padhar100% (1)
- School of Science and Technology: Coursework Assessment ElementDocument5 pagesSchool of Science and Technology: Coursework Assessment ElementVishal PadharNo ratings yet
- Aadhaar Enrolment/Update FormDocument2 pagesAadhaar Enrolment/Update FormMadivalappaNo ratings yet
- OOPs Interview Que AnsDocument9 pagesOOPs Interview Que AnsVishal PadharNo ratings yet
- TMS - Business Analysis Review: Transportation CorridorDocument3 pagesTMS - Business Analysis Review: Transportation CorridorVishal PadharNo ratings yet
- School of Science and Technology: Referral Coursework Assessment Specification (PG)Document11 pagesSchool of Science and Technology: Referral Coursework Assessment Specification (PG)Vishal PadharNo ratings yet
- Jahernamu 18 04 2020Document5 pagesJahernamu 18 04 2020Vishal PadharNo ratings yet
- ICICITranDocument1 pageICICITranVishal PadharNo ratings yet
- Visit Us For More Movies and TV Shows ExclusiveDocument1 pageVisit Us For More Movies and TV Shows ExclusiveVishal PadharNo ratings yet
- CamScanner 04-15-2020 21.20.19Document3 pagesCamScanner 04-15-2020 21.20.19Vishal PadharNo ratings yet
- Document Analysis BowenDocument15 pagesDocument Analysis BowenEren ŞenNo ratings yet
- Ships of The World: Sagres: Assembly Instructions: Assembly Instructions: Six A4 Sheets (No. 1 To No. 6)Document6 pagesShips of The World: Sagres: Assembly Instructions: Assembly Instructions: Six A4 Sheets (No. 1 To No. 6)ntdkhanNo ratings yet
- Welcome To WPS Office PDFDocument8 pagesWelcome To WPS Office PDFAmri NastiNo ratings yet
- Ch1 SlidesDocument47 pagesCh1 SlidesPierreNo ratings yet
- 003 Elect - Electrical Earthing System Installation PDFDocument110 pages003 Elect - Electrical Earthing System Installation PDFbisworupmNo ratings yet
- An Investigation Into The Effects of Unsteady Parameters On The Aerodynamics of A Low Reynolds Number Pitching AirfoilDocument15 pagesAn Investigation Into The Effects of Unsteady Parameters On The Aerodynamics of A Low Reynolds Number Pitching AirfoilMANNE SAHITHINo ratings yet
- Domain Logic and SQLDocument23 pagesDomain Logic and SQLatifchaudhryNo ratings yet
- CancioneroDocument7 pagesCancioneroJocelyn Almaguer LariosNo ratings yet
- S/4HANA Margin Analysis, Predictive Accounting, and Continuous CloseDocument27 pagesS/4HANA Margin Analysis, Predictive Accounting, and Continuous Closessbhagat001No ratings yet
- Quantum Computing CSDocument101 pagesQuantum Computing CSRaghavNo ratings yet
- BSBPMG531 - Assessment Task 2 v2Document26 pagesBSBPMG531 - Assessment Task 2 v2Paulo Dizon100% (2)
- MCMC Methods For Multi-Response Generalized LinearDocument22 pagesMCMC Methods For Multi-Response Generalized LinearkyotopinheiroNo ratings yet
- Selected Questions Revised 20200305 2HRDocument3 pagesSelected Questions Revised 20200305 2HRTimmy LeeNo ratings yet
- Report On MinesDocument7 pagesReport On MinesYhaneNo ratings yet
- Chap 7Document35 pagesChap 7Nizar TayemNo ratings yet
- Quality Control and Assurance Processes for Coffee ProductionDocument5 pagesQuality Control and Assurance Processes for Coffee ProductionSharifah NuruljannahNo ratings yet
- Spraying TechniquesDocument12 pagesSpraying TechniquesX800XLNo ratings yet
- Advertisement AnalysisDocument15 pagesAdvertisement AnalysisDaipayan DuttaNo ratings yet
- Coalgebraic Modelling of Timed ProcessesDocument298 pagesCoalgebraic Modelling of Timed ProcessesFaris Abou-SalehNo ratings yet
- Anna University Project Work Submission FormDocument1 pageAnna University Project Work Submission FormaddssdfaNo ratings yet
- Phil. Crocodile-WPS OfficeDocument19 pagesPhil. Crocodile-WPS OfficeQUEENIE JAM ABENOJANo ratings yet
- 4 - Microsoft PowerPoint - JDC Company ProfileDocument12 pages4 - Microsoft PowerPoint - JDC Company ProfileBill LiNo ratings yet
- THE END - MagDocument164 pagesTHE END - MagRozze AngelNo ratings yet
- Maths English Medium 7 To 10Document13 pagesMaths English Medium 7 To 10TNGTASELVASOLAINo ratings yet
- Optimum Selection of Cooling TowerDocument29 pagesOptimum Selection of Cooling TowerNikhil JhaNo ratings yet
- Ansi C 136.20Document16 pagesAnsi C 136.20Amit Kumar Mishra100% (1)
- Data CollectionDocument4 pagesData CollectionjochukoNo ratings yet
- 5fc56cb37a6847288b78b547 - Using Kobo ToolboxDocument4 pages5fc56cb37a6847288b78b547 - Using Kobo Toolboxpouya rahmanyNo ratings yet
- Epimastic 7200: Product DescriptionDocument2 pagesEpimastic 7200: Product DescriptionSu KaNo ratings yet
- PTR 326 Theoretical Lecture 1Document14 pagesPTR 326 Theoretical Lecture 1muhammedariwanNo ratings yet